背景
多年来 Hive 的 RCFile 是Hadoop用于存储表格数据的标准格式。 但是 RCFile 有局限性,因为它将每一列视为没有语义的二进制Blob。 在Hive 0.11中,我们添加了一个名为优化行列式文件(ORC)的新文件格式,该文件使用并保留表定义中的类型信息。
ORC使用特定类型的读取器和写入器,提供轻量级压缩技术,如字典编码、位填充、增量编码和RLE编码,从而导致文件大小显著减小。 此外,ORC可以在轻量级压缩的基础上应用通用压缩,使用zlib或Snappy,以进一步减小文件大小。
然而,存储节省仅仅是收益的一部分。ORC支持投影,可选择要读取的列的子集,以便仅读取查询所需的字节,因此仅读取一个列的查询只读取所需的字节。
此外,ORC文件包括轻量级索引,其中包括每列在每组10,000行和整个文件中的最小和最大值。
使用Hive的谓词下推过滤器,文件读取器可以跳过对于此查询而言不重要的整组行。
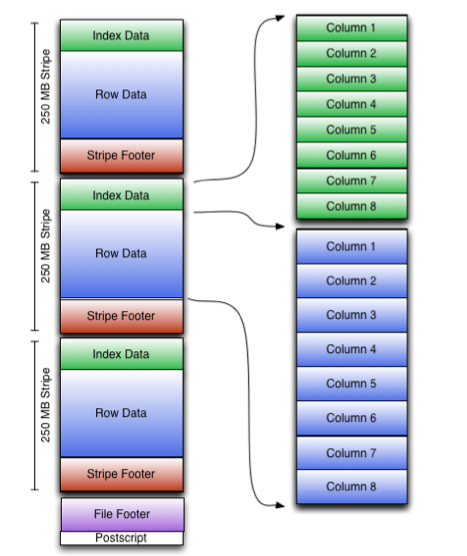
FileTail
由于HDFS不支持在写入文件后更改文件中的数据,因此ORC将顶层索引存储在文件末尾。
文件的整体结构如下所示。 文件的尾部包括三个部分:文件元数据(Metadata)、文件页脚(Footer)和尾部附录(Postscript)。
ORC的元数据使用Protocol Buffers存储,这提供了在不破坏读取器的情况下添加新字段的能力。
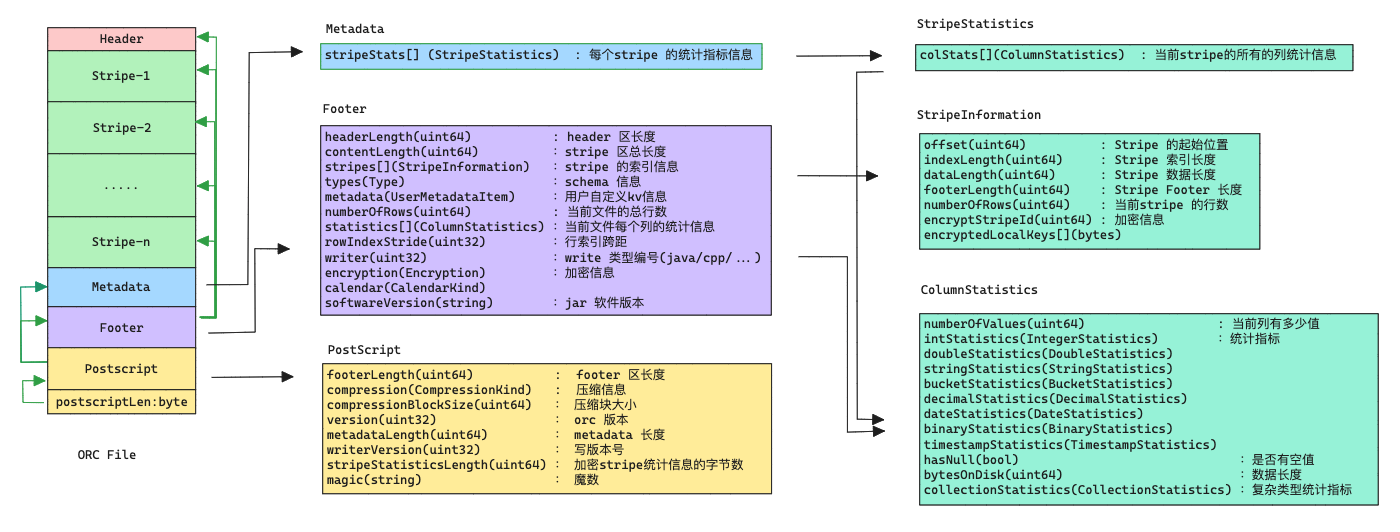
Postscript
Postscript部分提供了解释文件其余部分所需的信息: 包括Footer和Metadata的长度、文件的版本以及使用的通用压缩类型(例如,无压缩、zlib或snappy)。
postscript永远不会被压缩,并在文件结束前一个字节结束(最后一个字节存储 postscript的长度)。
postscript 中存储的版本是保证能够读取文件的最低版本的Hive,以主版本号和次版本号的序列存储。
message PostScript {
optional uint64 footerLength = 1; // 记录当前的footer的长度
optional CompressionKind compression = 2; // 记录当前压缩信息
optional uint64 compressionBlockSize = 3;
// postscript 中存储的版本是保证能够读取文件的最低版本的Hive,以主版本号和次版本号的序列存储。
// [0, 11] = Hive 0.11
// [0, 12] = Hive 0.12
repeated uint32 version = 4 [packed = true];
optional uint64 metadataLength = 5; // 记录metadata的长度
// 写入文件的写入器版本。
// 当我们对写入器进行修复或进行较大更改时,此数字将更新,以便读取器可以检测数据中是否存在特定的错误。
//
// ORC Java写入器的版本:
// 0 = original
// 1 = HIVE-8732 fixed (fixed stripe/file maximum statistics & string statistics use utf8 for min/max)
// 2 = HIVE-4243 fixed (use real column names from Hive tables)
// 3 = HIVE-12055 added (vectorized writer implementation)
// 4 = HIVE-13083 fixed (decimals write present stream correctly)
// 5 = ORC-101 fixed (bloom filters use utf8 consistently)
// 6 = ORC-135 fixed (timestamp statistics use utc)
// 7 = ORC-517 fixed (decimal64 min/max incorrect)
// 8 = ORC-203 added (trim very long string statistics)
// 9 = ORC-14 added (column encryption)
//
// ORC C++ 写入器的版本 :
// 6 = original
//
// ORC Presto 写入器的版本 :
// 6 = original
//
// ORC Go 写入器的版本 :
// 6 = original
//
// ORC Trino 写入器的版本 :
// 6 = original
optional uint32 writerVersion = 6;
optional uint64 stripeStatisticsLength = 7; // 加密stripe统计信息的字节数
optional string magic = 8000; // 魔数
}
Footer
Footer 部分包含文件主体的布局、类型schema信息、行数以及每列的统计信息。
message Footer {
optional uint64 headerLength = 1; // orc 文件header长度 -- OrcFile.MAGIC 魔数
optional uint64 contentLength = 2; // orc 文件body长度
repeated StripeInformation stripes = 3; // stripe 统计信息
repeated Type types = 4; // schema 信息
repeated UserMetadataItem metadata = 5; // 用户自定义元信息
optional uint64 numberOfRows = 6; // 包含的行数据
repeated ColumnStatistics statistics = 7; // 文件级别的每个列的统计信息statics
optional uint32 rowIndexStride = 8; // 每个索引条目中的最大行数。
// 每个编写 ORC 文件的实现都应该注册一个代码。
// 0 = ORC Java
// 1 = ORC C++
// 2 = Presto
// 3 = Scritchley Go from https://github.com/scritchley/orc
// 4 = Trino
optional uint32 writer = 9;
// information about the encryption in this file
optional Encryption encryption = 10; // 对于加密列的处理
optional CalendarKind calendar = 11;
// 有关编写文件的软件版本的信息性描述。假定它在给定的写入器内,例如 ORC 1.7.2 = "1.7.2"。它可以包括后缀,如“-SNAPSHOT”。
optional string softwareVersion = 12;
}
Metadata
Metadata 部分主要用于记录每个stripe 的每个列的统计信息
message Metadata {
repeated StripeStatistics stripeStats = 1;
}
// StripeStatistics(每个stripe一个),其中每个包含每列的 ColumnStatistics.
message StripeStatistics {
repeated ColumnStatistics colStats = 1; // 每个列的统计统计信息
}
Stripe
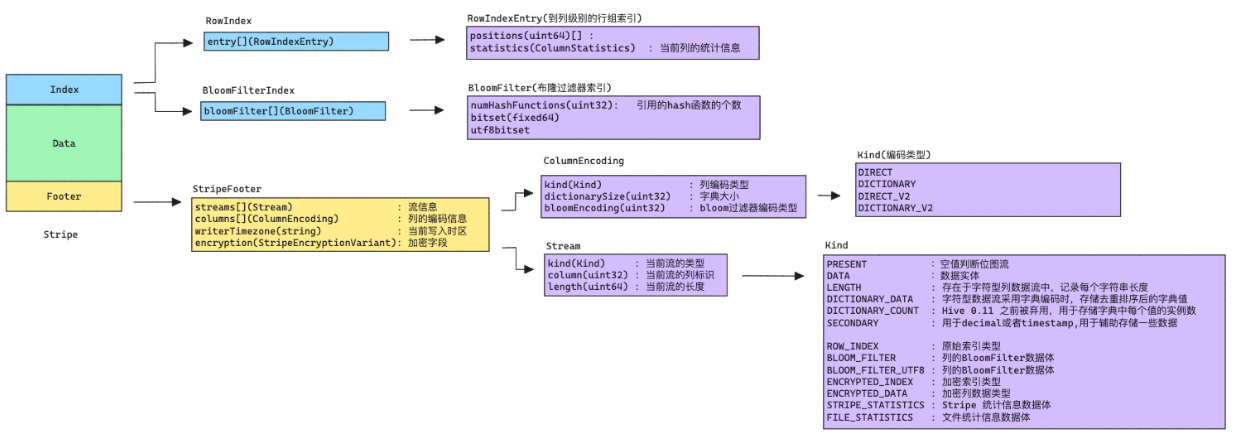
StripeFooter
Stripe Footer 包含每列的编码以及包括它们的位置在内的流目录。
message StripeFooter {
repeated Stream streams = 1; // 每个流的位置(未加密流)。
repeated ColumnEncoding columns = 2; // 每个列的编码类型
optional string writerTimezone = 3; // 写时区
repeated StripeEncryptionVariant encryption = 4; //加密列流类型统计
}
message ColumnEncoding {
enum Kind {
DIRECT = 0; // 直接编码
DICTIONARY = 1; // 字典编码
DIRECT_V2 = 2;
DICTIONARY_V2 = 3;
}
optional Kind kind = 1;
optional uint32 dictionarySize = 2;
// 此列的BloomFile 编码:
// 0 or missing = 没有编码
// 1 = ORC-135 (utc for timestamps)
optional uint32 bloomEncoding = 3;
}
message Stream {
// 数据流的类型
enum Kind {
PRESENT = 0; // 空值位图流
DATA = 1; // 数据实体
LENGTH = 2; //
DICTIONARY_DATA = 3; //
DICTIONARY_COUNT = 4; //
SECONDARY = 5; //
ROW_INDEX = 6; // 原始索引类型
BLOOM_FILTER = 7; // 列的BloomFilter数据体
BLOOM_FILTER_UTF8 = 8; // 列的BloomFilter数据体
ENCRYPTED_INDEX = 9; // 加密索引类型
ENCRYPTED_DATA = 10; // 加密列数据类型
STRIPE_STATISTICS = 100; // Stripe 统计信息数据体
FILE_STATISTICS = 101; // 文件统计信息数据体
}
optional Kind kind = 1; // 表示此数据流的类型
optional uint32 column = 2; // 列的标识ID
optional uint64 length = 3; // 流长度
}
Data
SmallInt、Int 和 BigInt 列
| ColumnEncoding | 包含的 DATA Stream | 是否可选 | 数据内容 |
|---|---|---|---|
| DIRECT | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 否 | 有符号整数 RLE v1 | |
| DIRECT_V2 | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 不 | 有符号整数RLE v2 |
Float 和 Double 列
| ColumnEncoding | 包含的 DATA Stream | 是否可选 | 数据内容 |
|---|---|---|---|
| DIRECT | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 否 | IEEE754浮点表示 |
String、Char 和 VarChar 列
String、char 和 varchar 列可以使用字典编码或直接编码。直接编码应为当存在许多不同值时首选orc.dictionary.key.threshold。
对于直接编码,UTF-8 字节保存在DATA流中,并且每个值的长度将写入LENGTH流中。直接编码,如果值为[“Nevada”, “California”];数据将是“NevadaCalifornia”,长度将是[6, 10]。
对于字典编码,字典被排序(在字典中 UTF-8 编码中的字节顺序)和 UTF-8 字节的顺序 每个唯一值都放入DICTIONARY_DATA中。每个的长度字典中的项被放入LENGTH流中。
DATA流由对字典元素的引用序列组成。
在字典编码中,如果值为 [“Nevada”, “加利福尼亚州”、“内华达州”、“加利福尼亚州”和“佛罗里达州”];这 DICTIONARY_DATA将是“CaliforniaFloridaNevada”,而LENGTH将是[10, 7, 6]。DATA将为[2, 0, 2, 0,1]。
| ColumnEncoding | 包含的 DATA Stream | 是否可选 | 数据内容 |
|---|---|---|---|
| DIRECT | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 否 | 字符串内容 | |
| LENGTH | 否 | 无符号整数 RLE v1 | |
| DICTIONARY | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 否 | 无符号整数 RLE v1 | |
| DICTIONARY_DATA | 否 | 字符串内容 | |
| LENGTH | 否 | 无符号整数 RLE v1 | |
| DIRECT_V2 | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 否 | 字符串内容 | |
| LENGTH | 否 | 无符号整数 RLE v2 | |
| DICTIONARY_V2 | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 否 | 无符号整数 RLE v2 | |
| DICTIONARY_DATA | 否 | 字符串内容 | |
| LENGTH | 否 | 无符号整数 RLE v2 |
Bool,TinyInt列
| ColumnEncoding | 包含的 DATA Stream | 是否可选 | 数据内容 |
|---|---|---|---|
| DIRECT | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 否 | 布尔 RLE |
Bytes 列
| ColumnEncoding | 包含的 DATA Stream | 是否可选 | 数据内容 |
|---|---|---|---|
| DIRECT | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 否 | 字符串内容 | |
| LENGTH | 否 | 无符号整数 RLE v1 | |
| DICTIONARY_V2 | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 否 | 无符号整数 RLE v2 | |
| DICTIONARY_DATA | 否 | 字符串内容 | |
| LENGTH | 否 | 无符号整数 RLE v2 |
Decimal 列
| ColumnEncoding | 包含的 DATA Stream | 是否可选 | 数据内容 |
|---|---|---|---|
| DIRECT | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 否 | 有符号整数 RLE v2 | |
| DIRECT_V2 | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 否 | 无界底数128变量 | |
| SECONDARY | 否 | 有符号整数 RLE v2 |
Date 列
| ColumnEncoding | 包含的 DATA Stream | 是否可选 | 数据内容 |
|---|---|---|---|
| DIRECT | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 否 | 有符号整数 RLE v1 | |
| DIRECT_V2 | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 否 | 有符号整数 RLE v2 |
Timestamp 列
| ColumnEncoding | 包含的 DATA Stream | 是否可选 | 数据内容 |
|---|---|---|---|
| DIRECT | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 否 | 有符号整数 RLE v1 | |
| SECONDARY | 否 | 无符号整数 RLE v1 | |
| DIRECT_V2 | PRESENT | 是(数据全非空可没有) | 布尔 RLE |
| DATA | 否 | 有符号整数 RLE v2 | |
| SECONDARY | 否 | 无符号整数 RLE v2 |
Index

Row Group Index
row group index 由每个行组的基元列的 ROW_INDEX stream 组成。
行组由写入器控制,默认为(orc.row.index.stride) 10,000 行。每个 RowIndexEntry 给出了该列的每个流的位置和该行组的统计信息。
ROW_INDEX stream 放置在 stream 的前面,因为在默认的流式传输情况下它们不需要被读取。
它们只在使用谓词下推或读取器寻求特定行时加载。
// 每个RowGroup的每个列的统计信息
message RowIndexEntry {
repeated uint64 positions = 1 [packed=true]; // 包含data区当前列所有stream的索引信息
optional ColumnStatistics statistics = 2; // 包含行组内的列的相关统计信息,最大值,最小值,求和,
}
// RowGroup 中的每个列的索引信息
message RowIndex {
repeated RowIndexEntry entry = 1;
}
Bloom Filter Index
Hive 1.2.0 开始,Bloom Filters 被添加到 ORC 索引中。
谓词下推可以利用布隆过滤器更好地剪枝不满足过滤条件的行组。布隆过滤器索引包括通过 orc.bloom.filter.columns 属性指定的每个列的 BLOOM_FILTER 流。
BLOOM_FILTER 流为列中的每个row group(默认为 10,000 行)记录一个布隆过滤器条目。只有满足 min/max 行索引评估的行组将被用于布隆过滤器索引的评估。
message BloomFilter {
optional uint32 numHashFunctions = 1;
repeated fixed64 bitset = 2;
optional bytes utf8bitset = 3;
}
message BloomFilterIndex {
repeated BloomFilter bloomFilter = 1;
}
ORC 配置汇总
| orc 配置项 | hive 配置项 | 默认值 | 说明 |
|---|---|---|---|
| orc.stripe.size | hive.exec.orc.default.stripe.size | 64 * 1024*1024 | orc stripe 大小(STRIPE_SIZE) |
| orc.stripe.row.count | orc.stripe.row.count | Integer.MAX_VALUE | 每个stripe可以容纳的数量大小 |
| orc.block.size | hive.exec.orc.default.block.size | 256L * 1024 * 1024 | orc 文件块大小 |
| orc.create.index | orc.create.index | true | 是否创建索引作为文件的一部分 |
| orc.row.index.stride | hive.exec.orc.default.row.index.stride | 10000 | 定义ORC索引的默认步幅,以行数表示。 (步幅是索引条目表示的行数。) |
| orc.compress.size | hive.exec.orc.default.buffer.size | 256 * 1024 | 定义ORC缓冲区的默认大小(BUFFER_SIZE),以字节为单位。 |
| orc.base.delta.ratio | hive.exec.orc.base.delta.ratio | 8 | 在STRIPE_SIZE和BUFFER_SIZE方面的基础写入器和增量写入器的比率。这指的是基础写入器和增量写入器在STRIPE_SIZE和BUFFER_SIZE方面的相对比率。 |
| orc.block.padding | hive.exec.orc.default.block.padding | true | 定义是否应将Stripe填充到HDFS块边界。这个设置指定了是否应该在写入ORC文件时将stripe的大小调整为HDFS块的大小。填充stripe可以有助于优化读取性能。 |
| orc.compress | hive.exec.orc.default.compress | ZLIB | 定义ORC文件的默认压缩编解码器 |
| orc.write.format | hive.exec.orc.write.format | 0.12 | 定义要写入的文件版本。可能的取值为0.11和 0.12 |
| orc.buffer.size.enforce | hive.exec.orc.buffer.size.enforce | false | 定义强制执行ORC压缩缓冲区大小 |
| orc.encoding.strategy | hive.exec.orc.encoding.strategy | SPEED | 定义在写入数据时要使用的编码策略。更改此选项仅影响整数的轻量级编码。此标志不会更改更高级别压缩编解码器(如ZLIB)的压缩级别。 |
| orc.compression.strategy | hive.exec.orc.compression.strategy | SPEED | 定义在写入数据时要使用的压缩策略。这会更改更高级别压缩编解码器(如ZLIB)的压缩级别。 |
| orc.block.padding.tolerance | hive.exec.orc.block.padding.tolerance | 0.05 | 定义块填充的容忍度,以stripe大小的小分数表示(例如,默认值0.05表示stripe大小的5%)。对于默认的64Mb ORC Stripe和256Mb HDFS块,5%的默认块填充容忍度将在256Mb块内最多保留3.2Mb的填充空间。在这种情况下,如果块内的可用空间超过3.2Mb,将插入一个新的较小stripe以适应该空间。这将确保写入的任何stripe都不会在块边界上并导致节点本地任务内的远程读取。 |
| orc.use.zerocopy | hive.exec.orc.zerocopy | false | 使用零拷贝技术 |
| orc.skip.corrupt.data | hive.exec.orc.skip.corrupt.data | false | 如果ORC读取器遇到损坏的数据,此值将用于确定是跳过损坏的数据还是引发异常。默认行为是抛出异常 |
| orc.tolerate.missing.schema | hive.exec.orc.tolerate.missing.schema | true | 早于 HIVE-4243 的写入器可能具有不准确的模式元数据。此设置将启用最佳尝试模式演变,而不是拒绝不匹配的模式。 |
| orc.memory.pool | hive.exec.orc.memory.pool | 0.5 | orc write可以使用的堆的最大百分比 |
| orc.dictionary.key.threshold | hive.exec.orc.dictionary.key.size.threshold | 0.8 | 字典编码阈值,如果(字典中不同键的数量/非空行)比例超过这个阈值,则关闭字典 |
| orc.dictionary.early.check | hive.orc.row.index.stride.dictionary.check | true | 如果启用了字典检查,将在第一个行索引步幅(默认为10000行)之后进行字典检查,否则将在写入第一个stripe之前进行字典检查。在两种情况下,此后将保留使用字典与否的决策。 |
| orc.dictionary.implementation | orc.dictionary.implementation | rbtree | 字符串字典编码的具体实现类: rbtree : 在字典的上下文中,红黑树可能用于快速的查找和操作字典中的键值对。hash: 在这个上下文中,提到使用哈希表作为字典的实现方式,表示字典的存储和检索操作是基于哈希表进行的。 |
| orc.bloom.filter.fpp | orc.default.bloom.fpp | 0.05 | 布隆过滤器的默认误报概率 |
| orc.bloom.filter.columns | orc.bloom.filter.columns | ”” | 写入时要为其创建 BloomFile 的列集合 |
| orc.bloom.filter.write.version | orc.bloom.filter.write.version | OrcFile.BloomFilterVersion.UTF8 | BloomFilter 的版本 : original : 可以确保旧的读取器和新的读取器都能够有效地使用布隆过滤器,而不受版本差异的影响。utf8 : 仅支持新版本的Bloom过滤器 |
| orc.bloom.filter.ignore.non-utf8 | orc.bloom.filter.ignore.non-utf8 | false | 设置reader是否忽略非utf8的bloom过滤器编码类型 |
| orc.max.file.length | orc.max.file.length | Long.MAX_VALUE | 查找文件尾部时要读取的文件的最大大小, 这主要用于流式摄取,以便在文件仍然打开时读取中间页脚 |
| orc.mapred.input.schema | null | null | 读取时反序列化的schema, 通过 TypeDescription.fromString 来解析这些字符串 |
| orc.mapred.map.output.key.schema | null | null | 这是关于 MapReduce shuffle key 相关的schema。这里的值是通过 TypeDescription.fromString 进行解释的。 |
| orc.mapred.map.output.value.schema | null | null | 这是关于 MapReduce shuffle value 相关的schema。这里的值是通过 TypeDescription.fromString 进行解释的。 |
| orc.mapred.output.schema | null | null | 用户希望写入的schema。这些值是通过 TypeDescription.fromString 进行解释的。 |
| orc.include.columns | hive.io.file.readcolumn.ids | null | 要读取的列的 ID 列表,用逗号分隔,其中 0 表示第一列,1 表示下一列,依此类推。 |
| orc.force.positional.evolution.level | orc.force.positional.evolution.level | 1 | 要求schema演变匹配通过位置而不是列名定义的级别列数。这提供了与 Hive 2.1 的向后兼容性。 |
| orc.rows.between.memory.checks | orc.rows.between.memory.checks | 5000 | MemoryManager应多久检查一次内存大小?以添加到所有写入器的行为单位进行测量。有效范围为[110000],主要用于测试。将此设置过低可能会对性能产生负面影响。使用 orc.stripe.row。如果值大于orc.stripe.row.count,则改为计数。 |
| orc.overwrite.output.file | orc.overwrite.output.file | false | 如果文件已经存在则是否要覆盖, 默认不覆盖 |
| orc.force.positional.evolution | orc.force.positional.evolution | false | 要求schema演化使用位置而不是列名来匹配顶级列。这提供了与Hive 2.1的向后兼容性 |
| orc.schema.evolution.case.sensitive | orc.schema.evolution.case.sensitive | true | schema 演化过程中是否区分大小写 |
| orc.kryo.sarg | orc.kryo.sarg | null | Kryo 和 Base64 编码的 SearchArgument 用于谓词下推。 |
| orc.kryo.sarg.buffer | null | 8192 | 用于谓词下推的kryo buffer大小 |
| orc.sarg.column.names | org.sarg.column.names | null | 谓词下推的列名 |
| orc.sarg.to.filter | org.sarg.to.filter | false | 用于确定是否允许SArg成为过滤器的布尔标志 |
| orc.filter.use.selected | orc.filter.use.selected | false | 布尔标志,用于确定读取应用程序是否支持向量查询。如果为false,则ORC读取器的输出必须重新应用筛选器,以避免在未选中的行中使用未设置的值 |
| orc.filter.plugin | orc.filter.plugin | false | 允许在读取期间使用插件筛选器。插件过滤器是通过 org.apache.orc.filter.PluginFilterService 的服务发现,如果存在多个过滤器, 则顺序不确定 |
| orc.write.variable.length.blocks | null | false | 关于 ORC 写入器是否应写入可变长度 HDFS 块的布尔标志 |
| orc.column.encoding.direct | orc.column.encoding.direct | ”” | 要跳过字典编码的列 |
| orc.max.disk.range.chunk.limit | hive.exec.orc.max.disk.range.chunk.limit | Integer.MAX_VALUE - 1024 | 要读取超过2GB的strip时,最大的限制块大小 |
| orc.min.disk.seek.size | orc.min.disk.seek.size | 0 | 在确定连续读取时,此大小内的间隙将连续读取而不查找, 默认值为零将禁用此优化 |
| orc.min.disk.seek.size.tolerance | orc.min.disk.seek.size.tolerance | 0.00 | 定义由于 orc.min.disk.seek.size 读取的额外字节的容差。如果(bytesRead-bytesNeeded)/ BytesReeded大于此阈值,则执行额外的工作以在读取之后从内存中删除额外的字节 |
| orc.encrypt | orc.encrypt | null | 要加密的密钥和列的列表 |
| orc.mask | orc.mask | null | 要应用于加密列的掩码 |
| orc.key.provider | orc.key.provider | hadoop | 用于加密的密钥提供程序的类型 |
| orc.proleptic.gregorian | orc.proleptic.gregorian | false | 在读取和写入日期和时间时,我们是否应该使用推进格里高利历而不是混合儒略格里高利历?在 Hive 3.1 之前和 Spark 3.0 之前,它们使用了混合历法。 |
| orc.proleptic.gregorian.default | orc.proleptic.gregorian.default | false | 这个值控制着在 ORC 27 版本之前的文件中使用混合历法还是推进历法。只有 Hive 3.1 和 C++ 库在写入时使用了推进历法,所以混合历法是默认值。 |
| orc.row.batch.size | orc.row.batch.size | 1024 | ORC vector reader batch 中包含的行数 应仔细选择该值,以最小化开销并避免读取数据时出现OOM |
| orc.row.child.limit | orc.row.child.limit | 1024 * 32 | ORC行写入器将批写入文件之前要缓冲的最大子元素数 |

