数据结构 | 图的遍历

图的深度优先遍历(DFS)
深度优先搜索(depth-first search)是对先序遍历(preorder traversal)的推广。我们从某个顶点 v 开始处理 v,然后递归地遍历所有与 v 邻接的顶点。
实现思想:
在深度优先搜索中,对于最新发现的顶点,如果它还有以此为起点而未探测到的边,就沿此边继续探测下去,当节点 v 的所有边都已被探寻过,探索将回溯到发现节点 v 有那条边的始节点,这一过程一直进行到已发现从源节点可达的所有节点位置。
如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个过程反复进行直到所有节点都被发现为止。


结合上图说明:左图是邻接表形式,按照上面的实现思想: 假定我们首先发现顶点0, 然后发现它还有以此为顶点而未探测到的边(0,1),(0,4), 探测完毕后,就回溯到始节点,然后到下一个节点1, (1,0)已探测过(无向图) ,则直接探测(1,4),然后以此类推。
为避免图中的圈造成的无限循环,当我们访问一个顶点 v 的时候,由于我们已经到达了该点处,因此需要将该点标记为已访问,对于未被标记的所有邻接顶点递归调用深度优先搜索。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
#include <iostream>
#include <list>
using namespace std;
class graph
{
public:
graph(int v) :vertex(v){
adj = new list<int>[v];
}
void addEdge(int v, int w);
void DFS();
void DFS(int v);
private:
int vertex;
list<int> *adj;
void DFSUtil(int v, bool visited[]);
};
//v:边的首顶点;w:边的尾顶点
void graph::addEdge(int v, int w)
{
adj[v].push_back(w);
}
void graph::DFSUtil(int v, bool visited[])
{
visited[v] = true;//置位
cout << v << " ";
list<int>::iterator iter;
for (iter = adj[v].begin(); iter != adj[v].end(); ++iter)
{
if (!visited[*iter])//表明未被访问过
DFSUtil(*iter, visited);//跳转到*iter
}
}
//vStart:搜索的起始顶点
//指定的起始顶点必须位于图内可达到的顶点
//如果图不连通,有可能访问不到某些节点
void graph::DFS(int vStart)
{
bool *visited = new bool[vertex];
memset(visited, false, vertex);
DFSUtil(vStart, visited);
}
//不需要指定起始顶点
//不管图的结构如何,都可以搜索到所有节点
void graph::DFS()
{
bool *visited = new bool[vertex];
memset(visited, false, vertex);
//从V0开始深度优先遍历,Vk-1是最后一次深度优先遍历开始的顶点
for (int i = 0; i < vertex; ++i)
{
if (!visited[i])
DFSUtil(i, visited);
}
}
int main()
{
graph g(5);
g.addEdge(0, 1);//生成无向图
g.addEdge(0, 4);
g.addEdge(1, 0);
g.addEdge(1, 4);
g.addEdge(1, 2);
g.addEdge(1, 3);
g.addEdge(2, 1);
g.addEdge(2, 3);
g.addEdge(3, 1);
g.addEdge(3, 4);
g.addEdge(3, 2);
g.addEdge(4, 3);
g.addEdge(4, 0);
g.addEdge(4, 1);
g.DFS();
return 0;
}
图的广度优先遍历
该方法按层处理顶点:距开始点最近的那些顶点首先被访问,而最远的那些顶点最后被访问。这很像对树的层序遍历。
为方便后面的介绍,重新贴一下邻接表的存储方式图:
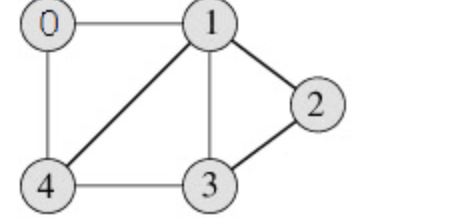
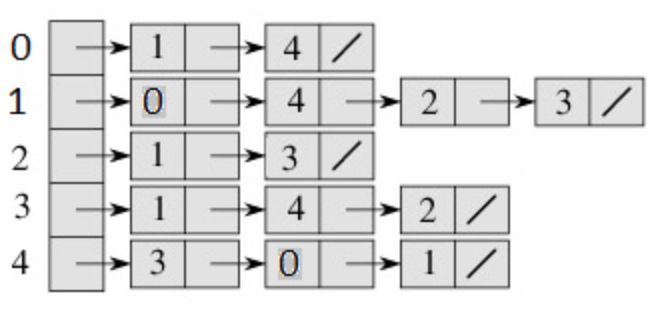
我们以上图的邻接表存储方式为例对广度优先搜索进行说明: 按照前面BFS的定义,我们首先访问所有与开始顶点最近的顶点,然后访问所有距离递增的顶点,最远的顶点则是最后被访问。 假定开始顶点为1,与顶点1最近的顶点有四个:0、4、2、3。邻接表存储有个好处就是,所有最近且距离相等的顶点都位于该顶点位置的链表中。 首先我们访问完所有与开始顶点1最近的顶点(0、4、2、3),很容易得知,与开始顶点次近(距离增1)的顶点恰好是最近顶点的最近顶点,也就是与(0、4、2、3)顶点最近的顶点。前面可理解为不断的替换开始顶点,已经访问过的顶点坐标记,保证不会被重复访问,否则进入无限循环。这样依次推进,直至访问完所有顶点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
//vStart:搜索的起始顶点
//指定的起始顶点必须位于图内可达到的顶点
void graph::BFS(int vStart)
{
bool *visited = new bool[vertex];
memset(visited, false, vertex);
list<int> queue;//利用链表构建一个队列
visited[vStart] = true;//表示开始访问
queue.push_back(vStart);//开始顶点入队
list<int>::iterator iter;
while (!queue.empty())
{
vStart = queue.front();//这里有个优先级,邻接表中链表的头节点优先级最高,依次降低
cout << vStart << " ";
queue.pop_front();//已访问顶点出队
//将与开始顶点最近的顶点,也就是链表中的顶点依次入队
for (iter = adj[vStart].begin(); iter != adj[vStart].end(); ++iter)
{
if (!visited[*iter])
{
visited[*iter] = true;//标记即将访问,事实上,进入队列了就是要访问的
queue.push_back(*iter);//从链表头节点到尾节点依次入队
}
}
}
}
深度优先搜索与广度优先搜索的区别:
深度优先搜索是按照一定的顺序先查找完一个分支,再查找另一个分支,直到找到目标,或是访问完所有节点(连通);广度优先搜索是从初始状态一层一层向下找,直到找到目标,或是访问完所有节点(连通)。
深度优先搜索通过栈来实现,而广度优先搜索通过队列来实现。
通常深度优先搜索不全部保留结点,扩展完的结点从数据库中弹出删去,这样,一般在数据库中存储的结点数就是深度值,因此它占用空间较少。所以,当搜索树的结点较多,用其它方法易产生内存溢出时,深度优先搜索不失为一种有效的求解方法。 广度优先搜索算法,一般需存储产生的所有结点,占用的存储空间要比深度优先搜索大得多,因此,程序设计中,必须考虑溢出和节省内存空间的问题。但广度优先搜索法一般无回溯操作,即入栈和出栈的操作,所以运行速度比深度优先搜索要快些。
上面说的通俗点就是:广度优先搜索是从中心点层层向外推进,走完最里层房间,然后走第二层的所有房间,直到第二层的所有房间全部走完,再走第三层的房间(这里不同的是同一层的所有房间之间是可以跳转的)。而深度优先搜索则是走死胡同,从中心点开始走,一路走,直到最后无路可走,然后退回来一层,再进入下一层的一间房间(只有同层的房间可以跳转,不同层的房间需要退回来),再走其余房间。