数据结构 | 树的存储结构

转载自 : 树的三种存储结构 - CSDN博客
定义
树(Tree)是n(n>=0)个结点的有限集。n=0时称为空树。
在任意一棵非空树中:
- 有且仅有一个特定的称为根(Root)的结点;
- 当n>1时,其余结点可分为m(m>O)个互不相交的有限集$T_1,T2,…,T_m$,其中每一个集合本身又是一棵树,并且称为根的子树(SubTree),如图6-2-1所示。

对于树的定义还需要强调两点:
- n>0时根结点是唯一的,不可能存在多个根结点,别和现实中的大树混在一起,现实中的树有很多根须,那是真实的树,数据结构中的树是只能有一个根结点。
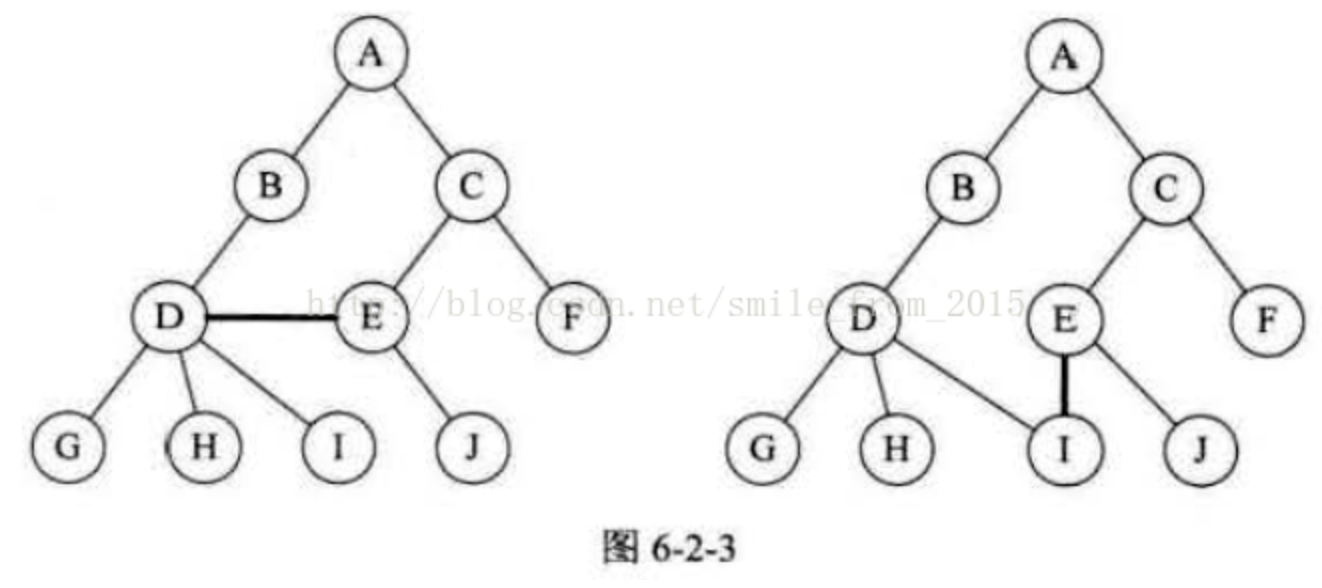
- m>0时,子树的个数没有限制,但它们一定是互不相交的。像图6-2-3中的两个结构就不符合树的定义,因为它们都有相交的子树。
1. 结点分类:
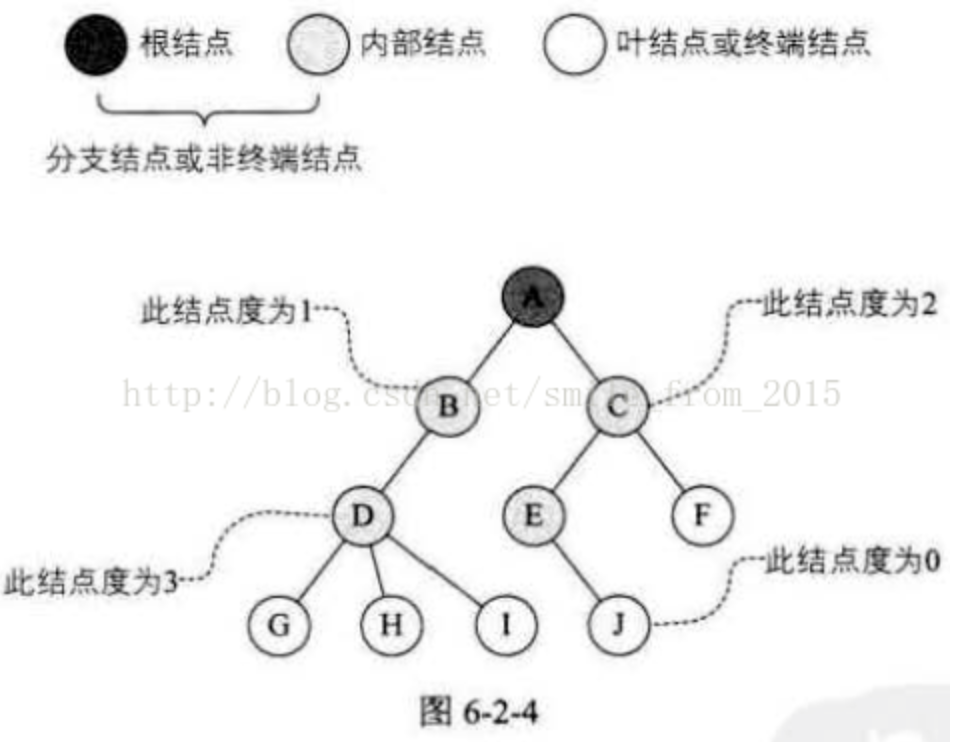
树的结点包含一个数据元素及若干指向其子树的分支。 结点拥有的子树数称为结点的度(Degree)。 度为0的结点称为叶结点(Leaf)或终端结点;度不为0的结点称为非终端结点或分支结点。 除根结点之外,分支结点也称为内部结点。树的度是树内各结点的度的最大值。 如图6-2-4所示,因为这棵树结点的度的最大值是结点D的度,为3,所以树的度也为3。
2. 结点间关系:
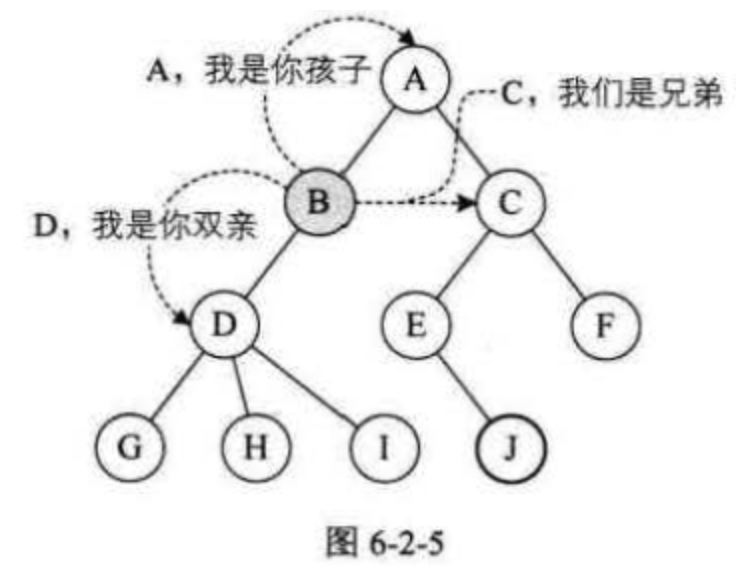
结点的子树的根称为该结点的子节点,相应地,该结点称为孩子的双亲节点。 恩,为什么不是父或母,叫双亲呢?对于结点来说其父母同体,唯一的一个,所以只能把它称为双亲了。 同一个双亲的子节点成为兄弟节点。 结点的祖先是从根到该结点所经分支上的所有结点。 所以对于H来说,D、B、A都是它的祖先。 反之,以某结点为根的子树中的任一结点都称为该结点的子孙。B的子孙有D、G、H、I,如图6-2-5所示。
3. 树的其他相关概念
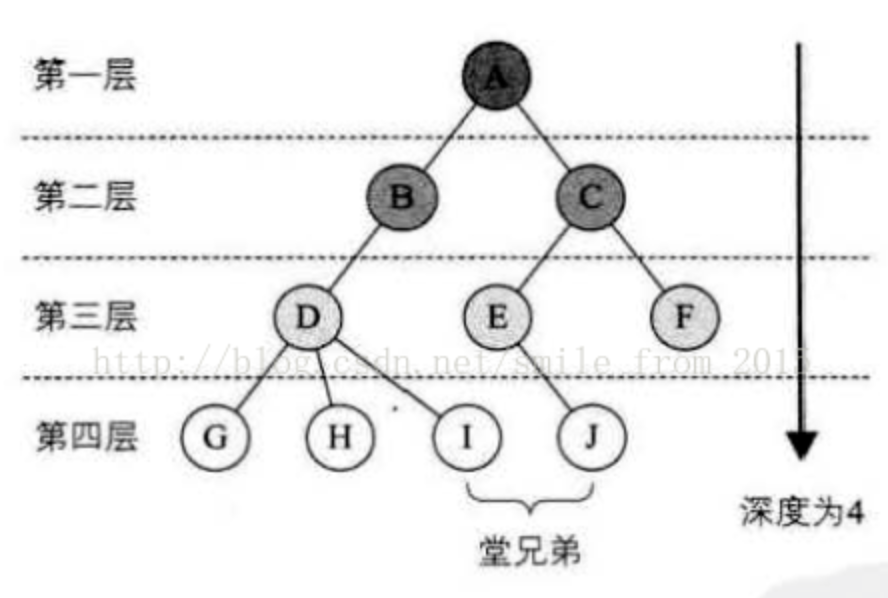
- 深度: 结点的层次(Level)从根开始定义起,根为第一层,根的孩子为第二层。若某结点在第l层,则其子树的根就在第1+1层。其双亲在同一层的结点直为堂兄弟。显然图6-2-6中的D、E、F是堂兄弟,而G、H、I、J也是。
树中结点的最大层次称为树的深度(Dep th),当前树的深度为4。
- 有序树与无序树:
如果将树中结点的各子树看成从左至右是有次序的,不能互换的,则称该树为有序树,否则称为无序树。
对比线性表与树的结构,它们有很大的不同,如图6-2-7所示:

树的存储结构:
树中某个结点的孩子可以有多个,这就意味着,无论按何种顺序将树中所有结点存储到数组中,结点的存储位置都无法直接反映逻辑关系,你想想看,数据元素挨个的存储,谁是谁的双亲,谁是谁的孩子呢?简单的顺序存储结构是不能满足树的实现要求的。
不过充分利用顺序存储和链式存储结构的特点,完全可以实现对树的存储结构的表示。我们这里要介绍三种不同的表示法:双亲表示法、孩子表示法、孩子兄弟表示法。
1. 双亲表示法:
我们假设以一组连续空间存储树的结点,同时在每个结点中,附设一个指示器指示其双亲结点到链表中的位置。也就是说,每个结点除了知道自己是谁以外,还知道它的双亲在哪里。它的结点结构为表6-4-1所示。
其中data是数据域,存储结点的数据信息。而parent是指针域,存储该结点的双亲在数组中的下标。

由于根结点是没有双亲的,所以我们约定根结点的位置域设置为-1,这也就意味着,我们所有的结点都存有它双亲的位置。如图6-4-1中的树结构和表6-4-2中的树双亲表示所示。

这样的存储结构,我们可以根据结点的parent指针很容易找到它的双亲结点,所用的时间复杂度为O(1),直到parent为-1时,表示找到了树结点的根。可如果我们要知道结点的孩子是什么,对不起,请遍历整个结构才行。
这真是麻烦,能不能改进一下呢?
当然可以。我们增加一个结点最左边孩子的域,不妨叫它长子域,这样就可以很容易得到结点的孩子。如果没有孩子的结点,这个长子域就设置为-1,如表6-4-3所示。(表中下标为0的firstchild应该为1)

对于有0个或1个孩子结点来说,这样的结构是解决了要找结点孩子的问题了。甚至是有2个孩子,知道了长子是谁,另一个当然就是次子了。
另外一个问题场景,我们很关注各兄弟之间的关系,双亲表示法无法体现这样的关系,那我们怎么办?嗯,可以增加一个右兄弟域来体现兄弟关系,也就是说,每一个结点如果它存在右兄弟,则记录下右兄弟的下标。同样的,如果右兄弟不存在,则赋值为-1 ,如表6-4-4所示。

但如果结点的孩子很多,超过了2个。我们又关注结点的双亲、又关注结点的孩子、还关注结点的兄弟,而且对时间遍历要求还比较高,那么我们还可以把此结构扩展为有双亲域、长子域、再有右兄弟域。存储结构的设计是一个非常灵活的过程。一个存储结构设计得是否合理,取决于基于该存储结构的运算是否适合、是否方便,时间复杂度好不好等。注意也不是越多越好,有需要时再设计相应的结构。
2. 孩子表示法:
换一种完全不同的考虑方法. 由于树中每个结点可能有多棵子树,可以考虑用多重链表,即每个结点有多个指针域,其中每个指针指向一棵子树的根结点,我们把这种方法叫做多重链表表示法。
不过,树的每个结点的度,也就是它的孩子个数是不同的。所以可以设计两种方案来解决。
方案一 :
一种是指针域的个数就等于树的度,复习一下,树的度是树各个结点度的最大值。其结构如表6-4-5所示。

其中data是数据域。childl到childd是指针域,用来指向该结点的孩子结点。
对于图6-4-1的树来说,树的度是3,所以我们的指针域的个数是3,这种方法实现如图6-4-2所示。

这种方法对于树中各结点的度相差很大时,显然是很浪费空间的,因为有很多的结点,它的指针域都是空的。不过如果树的各结点度相差很小时,那就意味着开辟的空间被充分利用了,这时存储结构的缺点反而变成了优点。
既然很多指针域都可能为空,为什么不按需分配空间呢。于是我们有了第二种方案。
方案二 :
第二种方案每个结点指针域的个数等于该结点的度,我们专门取一个位置来存储结点指针域的个数,其结构如表6-4-6所示。

其中data为数据域,degree为度域,也就是存储该结点的孩子结点的个数,child1到childd为指针域,指向该结点的各个孩子的结点。
对于图6-4-2的树来说,这种方法实现如图6-4-3所示。
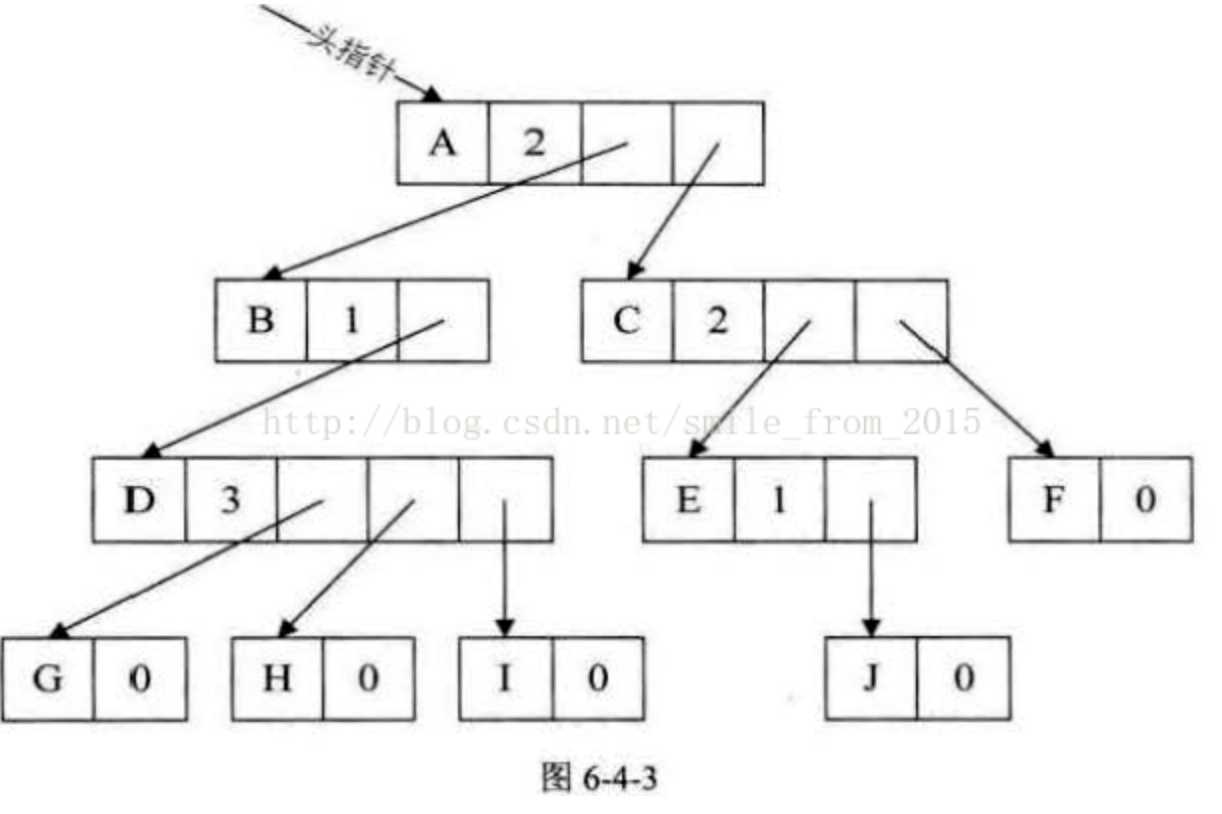
这种方法克服了浪费空间的缺点,对空间利用率是很高了,但是由于各个结点的链表是不相同的结构,加上要维护结点的度的数值,在运算上就会带来时间上的损耗。
3. 双亲孩子表示法:
具体方法是:
把每个结点的孩子结点排列起来,以单链表作存储结构,则n个结点有n个孩子链表,如果是叶子结点则此单链表为空。 然后n个头指针又组成一个线性表,采用顺序存储结构,存放进一个一维数组中,如图6-4-4所示

为此,设计两种结点结构,一个是孩子链表的孩子结点,如表6-4-7所示。
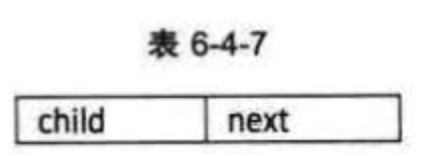
其中child是数据域,用来存储某个结点在表头数组中的下标。next是指针域,用来存储指向某结点的下一个孩子结点的指针。
另一个是表头数组的表头结点,如表6-4-8所示。

其中data是数据域,存储某结点的数据信息。firstchild是头指针域,存储该结点的孩子链表的头指针。
这样的结构对于我们要查找某个结点的某个孩子,或者找某个结点的兄弟,只需要查找这个结点的孩子单链表即可。对于遍历整棵树也是很方便的,对头结点的数组循环即可。
但是,这也存在着问题,我如何知道某个结点的双亲是谁呢?比较麻烦,需要整棵树遍历才行,难道就不可以把双亲表示法和孩子表示法综合一下吗?当然是可以。如图6-4-5所示。
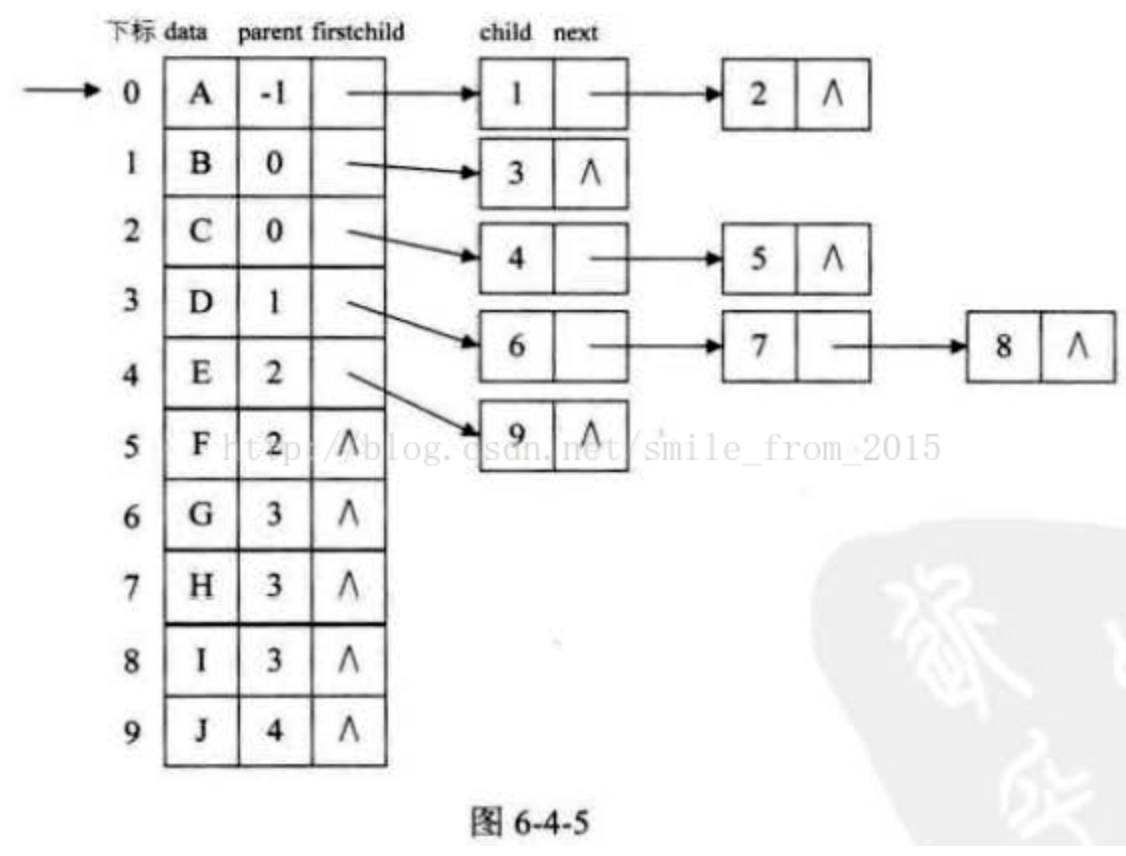
我们把这种方法称为双亲孩子表示法,应该算是孩子表示法的改进。
3. 孩子兄弟表示法:
刚才我们分别从双亲的角度和从孩子的角度研究树的存储结构,如果我们从树结点的兄弟的角度又会如何呢?
当然,对于树这样的层级结构来说,只研究结点的兄弟是不行的,我们观察后发现,任意一棵树,它的结点的第一个孩子如果存在就是唯一的,它的右兄弟如果存在也是唯一的。
因此,我们设置两个指针,分别指向该结点的第一个孩子和此结点的右兄弟。结点结构如表6-4-9所示。
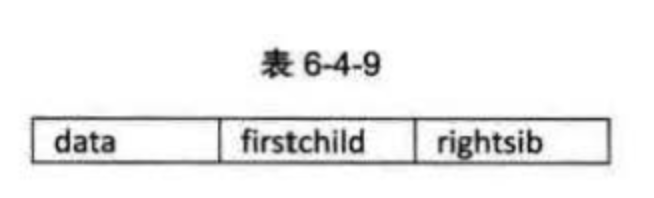
其中data是数据域,firstchild为指针域,存储该结点的第一个孩子结点的存储地址,rightsib是指针域,存储该结点的右兄弟结点的存储地址。
对于图6-4-1的树来说,这种方法实现的示意图如图6-4-6所示。
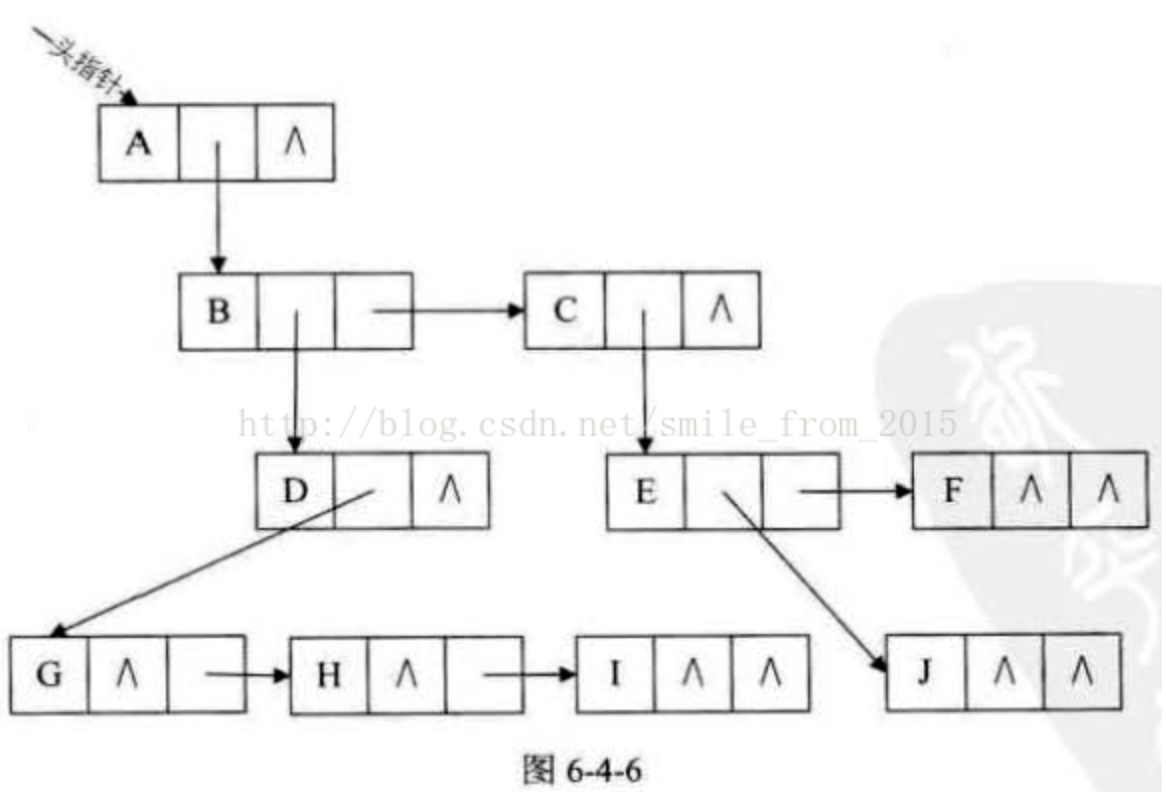
这种表示法,给查找某个结点的某个孩子带来了方便,只需要通过firstchild找到此结点的长子,然后再通过长子结点的rightsib找到它的二弟,接着一直下去,直到找到具体的孩子。
当然,如果想找某个结点的双亲,这个表示法也是有做陷的,那怎么办呢?
对,如果真的有必要,完全可以再增加一个parent指针域来解决快速查找双亲的问题,这里就不再细谈了。
其实这个表示法的最大好处是它把一棵复杂的树变成了一棵二叉树。我们把图6-4-6变变形就成了图6-4-7这个样子。

这样就可以充分利用二叉树的特性和算法来处理这棵树了。