数据结构 | B树与B+树

转载自:B-树的详解 - CSDN博客
B 树:
1.背景
磁盘中有两个机械运动的部分,分别是盘片旋转和磁臂移动。盘片旋转就是我们市面上所提到的多少转每分钟,而磁盘移动则是在盘片旋转到指定位置以后,移动磁臂后开始进行数据的读写。那么这就存在一个定位到磁盘中的块的过程,而定位是磁盘的存取中花费时间比较大的一块,毕竟机械运动花费的时候要远远大于电子运动的时间。当大规模数据存储到磁盘中的时候,显然定位是一个非常花费时间的过程,但是我们可以通过B树进行优化,提高磁盘读取时定位的效率。
为什么B类树可以进行优化呢?我们可以根据B类树的特点,构造一个多阶的B类树,然后在尽量多的在结点上存储相关的信息,保证层数尽量的少,以便后面我们可以更快的找到信息,磁盘的I/O操作也少一些,而且B类树是平衡树,每个结点到叶子结点的高度都是相同,这也保证了每个查询是稳定的。
2. 简介:
这里的B树,也就是英文中的B-Tree,一个 m 阶的B树满足以下条件:
- 每个结点至多拥有m棵子树;
- 根结点至少拥有两颗子树(存在子树的情况下);
- 除了根结点以外,其余每个分支结点至少拥有 m/2 棵子树;
- 所有的叶结点都在同一层上;
- 有 k 棵子树的分支结点则存在 k-1 个关键码,关键码按照递增次序进行排列;
- 关键字数量需要满足$ceil(m/2)-1 \le n \le m-1$;
每一个节点的存储格式如下:
1
2
3
4
5
typedef struct{
int Count; // 当前节点中关键元素数目
ItemType Key[m-1]; // 存储关键字元素的数组
long Branch[m]; // 伪指针数组,(记录数目)方便判断合并和分裂的情况
} NodeType;
- | Key1 | + | Key2 | + | … | Keym-1 | + — | — | — | — | — | — | — | —
树结构如下:

3. B 树的插入:
其实B-树的插入是很简单的,它主要是分为如下的两个步骤:
- 使用之前介绍的查找算法查找出关键字的插入位置,如果我们在B-树中查找到了关键字,则直接返回。否则它一定会失败在某个最底层的终端结点上。
- 然后,我就需要判断那个终端结点上的关键字数量是否满足:n<=m-1,如果满足的话,就直接在该终端结点上添加一个关键字,否则我们就需要产生结点的“分裂”。
分裂的方法是:
生成一新结点。把原结点上的关键字和k(需要插入的值)按升序排序后,从中间位置把关键字(不包括中间位置的关键字)分成两部分。左部分所含关键字放在旧结点中,右部分所含关键字放在新结点中,中间位置的关键字连同新结点的存储位置插入到父结点中。 如果父结点的关键字个数也超过(m-1),则要再分裂,再往上插。直至这个过程传到根结点为止。
下面我们来举例说明,首先假设这个B-树的阶为:3。树的初始化时如下:
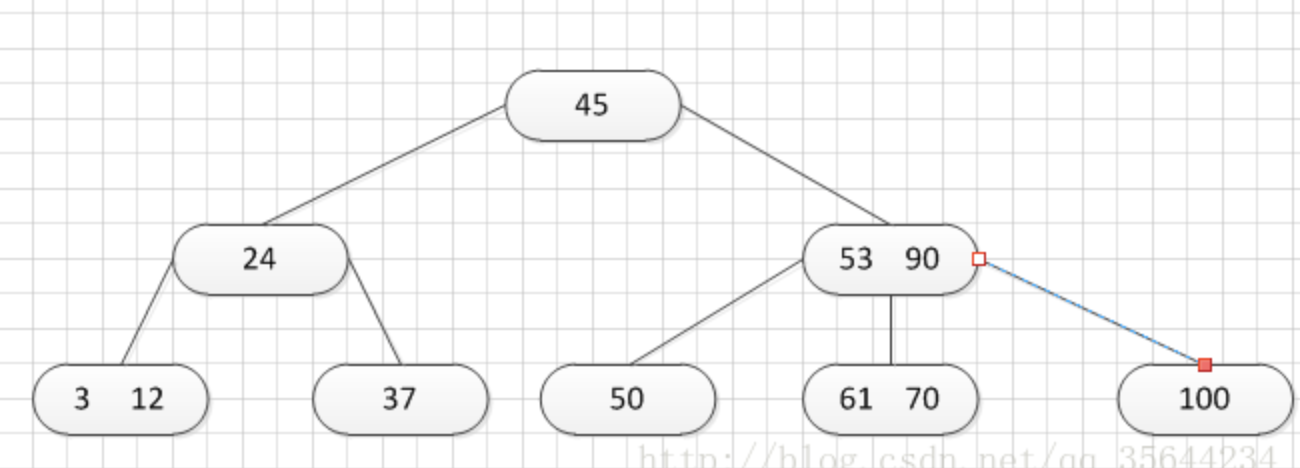
首先,我需要插入一个关键字:30,可以得到如下的结果:

再插入26,得到如下的结果:

OK,此时如图所示,在插入的那个终端结点中,它的关键字数已经超过了m-1=2,所以我们需要对结点进分裂。 我们先对关键字排序,得到:26 30 37 ,所以它的左部分为(不包括中间值):26,中间值为:30,右部为:37,左部放在原来的结点,右部放入新的结点,而中间值则插入到父结点。 并且父结点会产生一个新的指针,指向新的结点的位置,如下图所示:
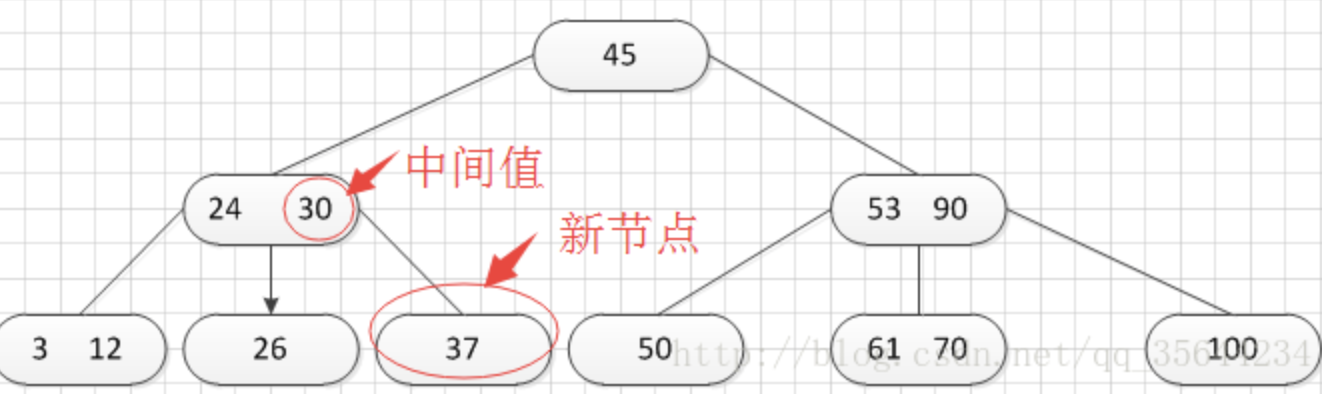
OK,然后我们继续插入新的关键字:85,得到如下图结果:

正如图所示,我需要对刚才插入的那个结点进行“分裂”操作,操作方式和之前的一样,得到的结果如下:
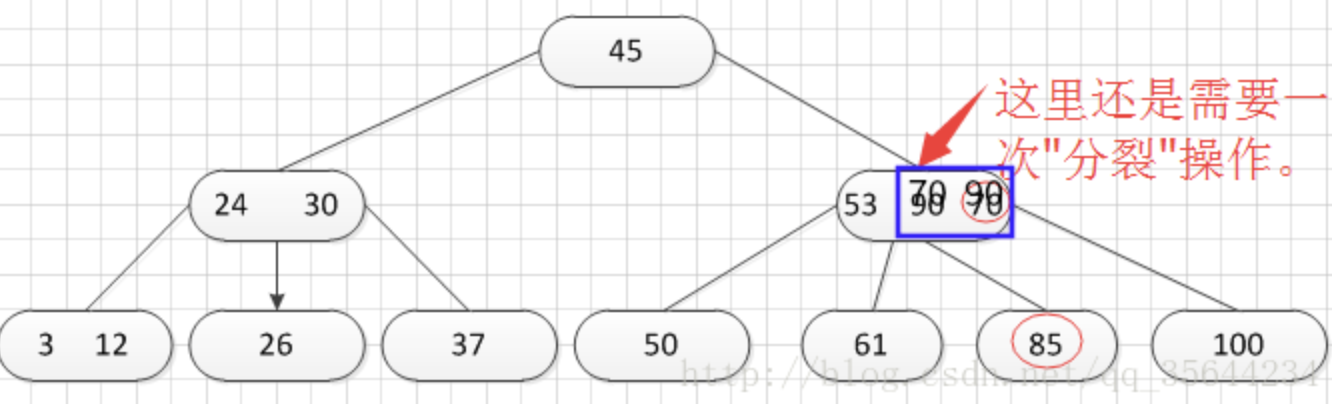
哦,当我们分裂完后,突然发现之前的那个结点的父亲结点的度为4了,说明它的关键字数超过了m-1,所以需要对其父结点进行“分裂”操作,得到如下的结果:

好,我们继续插入一个新的关键字:7,得到如下结果:
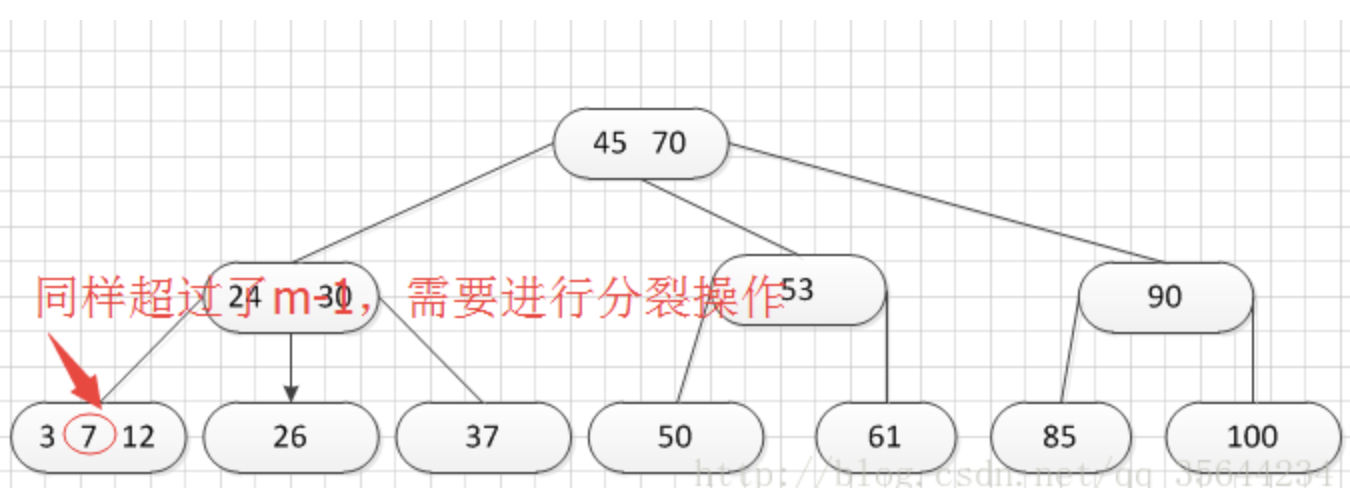
哦,当我们分裂完后,突然发现之前的那个结点的父亲结点的度为4了,说明它的关键字数超过了m-1,所以需要对其父结点进行“分裂”操作,得到如下的结果:
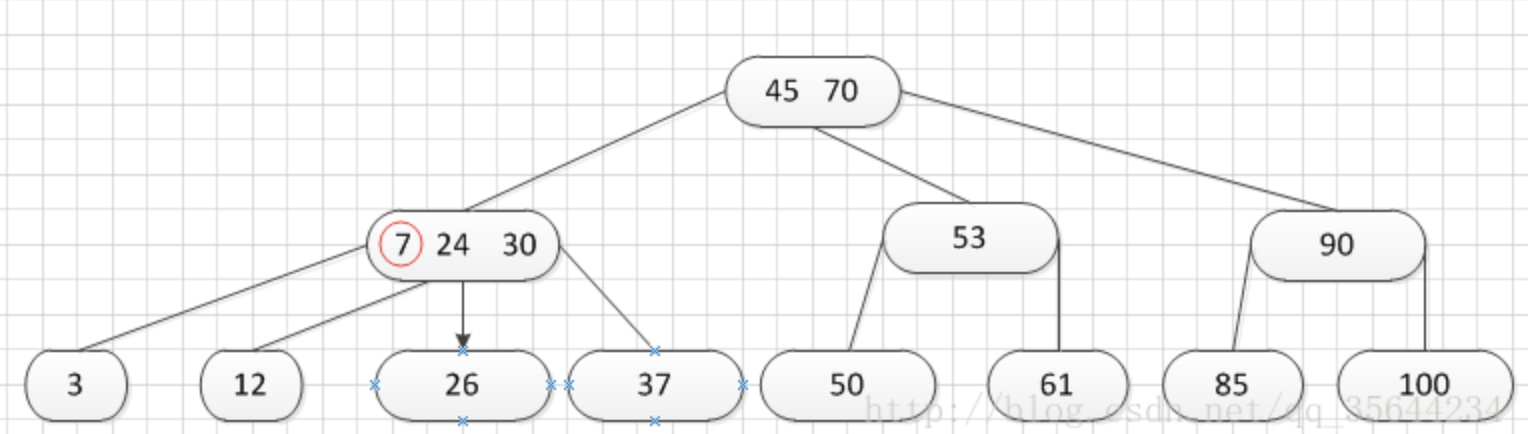
到了这里,我就需要继续对我们的父亲结点进行分裂操作,因为它的关键字数超过了:m-1.
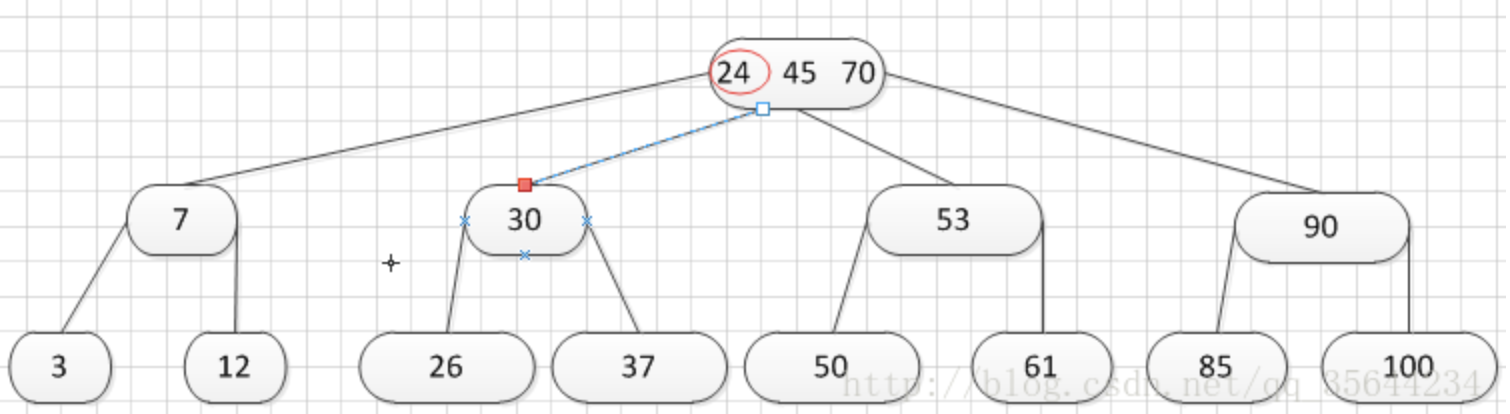
哦,终于遇到这种情况了,我们的根结点出现了关键子数量超过m-1的情况了,这个时候我们需要对父亲结点进行分列操作,但是根结点没父亲啊,所以我们需要重新创建根结点了。

4. B树的删除操作
B-树的删除操作同样是分为两个步骤:
- 利用前述的B-树的查找算法找出该关键字所在的结点。然后根据 k(需要删除的关键字)所在结点是否为叶子结点有不同的处理方法。如果没有找到,则直接返回。
- 若该结点为非叶结点,且被删关键字为该结点中第i个关键字key[i],则可从指针son[i]所指的子树中找出最小关键字Y,代替key[i]的位置,然后在叶结点中删去Y。
如果是叶子结点的话,需要分为下面三种情况进行删除:
- 如果被删关键字所在结点的原关键字个数 n>=[m/2] ( 上取整),说明删去该关键字后该结点仍满足B-树的定义。这种情况最为简单,只需删除对应的关键字:k和指针:A 即可。
- 如果被删关键字所在结点的关键字个数n等于( 上取整)[ m/2 ]-1,说明删去该关键字后该结点将不满足B-树的定义,需要调整。
调整过程为:
如果其左右兄弟结点中有“多余”的关键字,即与该结点相邻的右兄弟(或左兄弟)结点中的关键字数目大于( 上取整)[m/2]-1。则可将右兄弟(或左兄弟)结点中最小关键字(或最大的关键字)上移至双亲结点。而将双亲结点中小(大)于该上移关键字的关键字下移至被删关键字所在结点中。
被删关键字所在结点和其相邻的兄弟结点中的关键字数目均等于(上取整)[m/2]-1。假设该结点有右兄弟,且其右兄弟结点地址由双亲结点中的指针Ai所指,则在删去关键字之后,它所在结点中剩余的关键字和指针,加上双亲结点中的关键字Ki一起,合并到 Ai所指兄弟结点中(若没有右兄弟,则合并至左兄弟结点中)。
下面,我们给出删除叶子结点的三种情况:
**第一种:关键字的数不小于(上取整)[m/2],如下图删除关键字:12 **
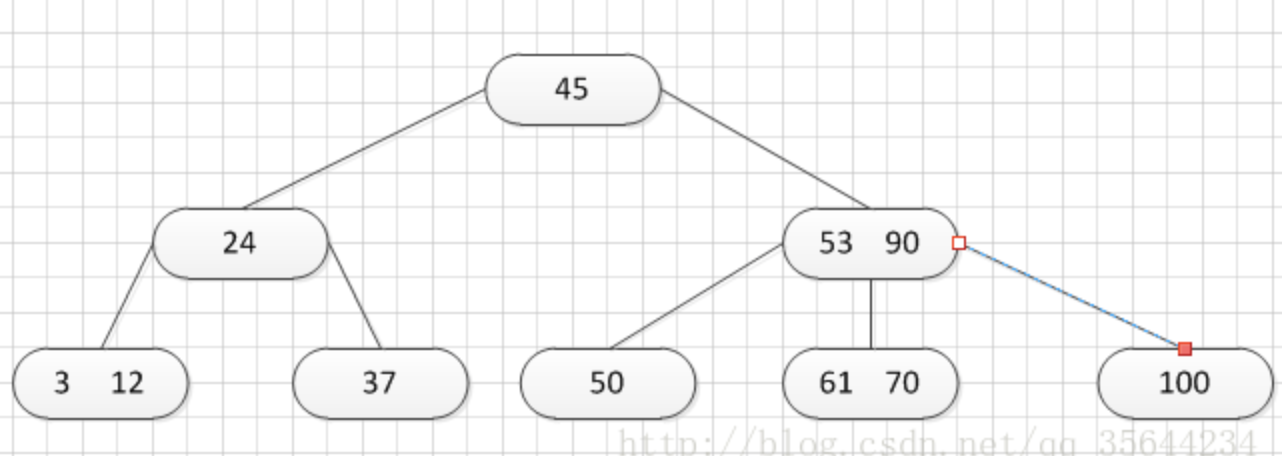
删除12后的结果如下,只是简单的删除关键字12和其对应的指针。
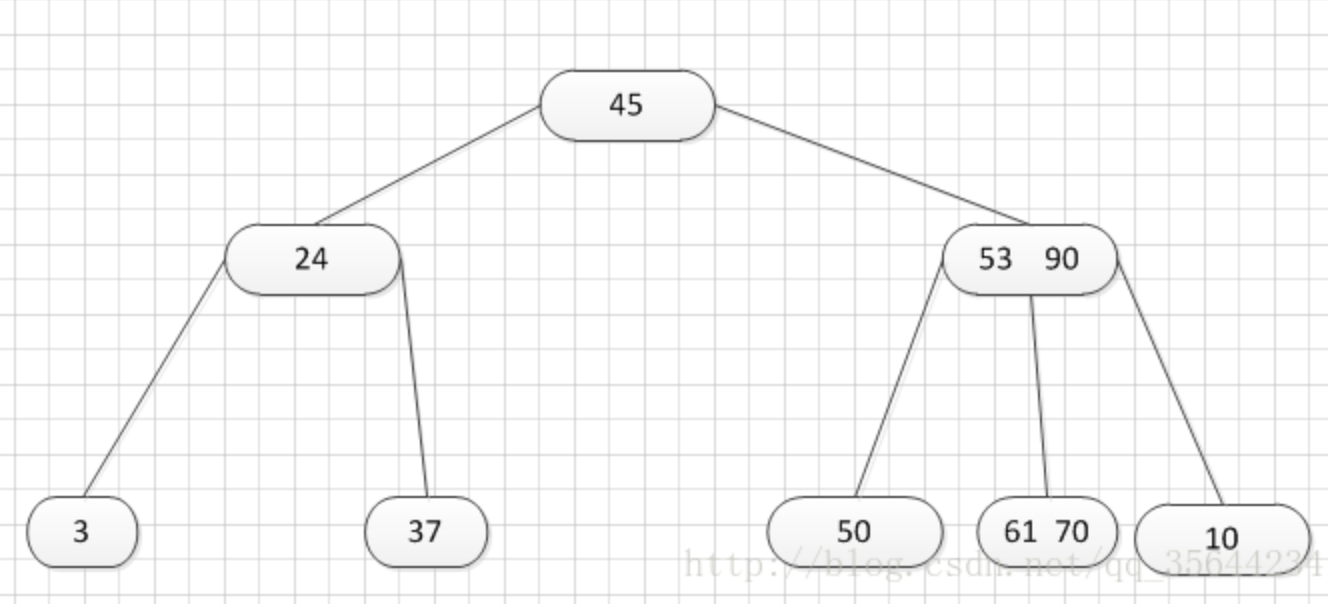
第二种:关键字个数n等于( 上取整)[ m/2 ]-1,而且该结点相邻的右兄弟(或左兄弟)结点中的关键字数目大于( 上取整)[m/2]-1.

如上图,所示,我们需要删除50这个关键字,所以我们需要把50的右兄弟中最小的关键字:61上移到其父结点,然后替换小于61的关键字53的位置,53则放至50的结点中。然后,我们可以得到如下的结果:

第三种:关键字个数n等于( 上取整)[ m/2 ]-1,而且被删关键字所在结点和其相邻的兄弟结点中的关键字数目均等于(上取整)[m/2]-1
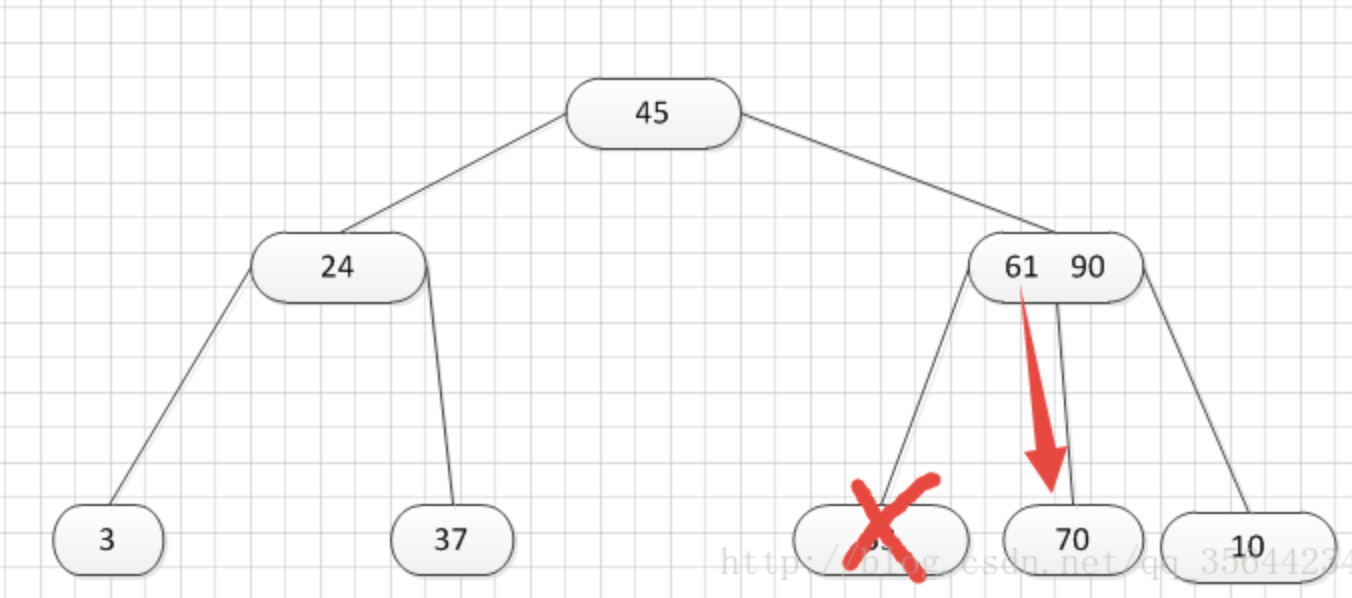
如上图所示,我们需要删除53,那么我们就要把53所在的结点其他关键字(这里没有其他关键字了)和父亲结点的61这个关键字一起合并到70这个关键字所占的结点。得到如下所示的结果:
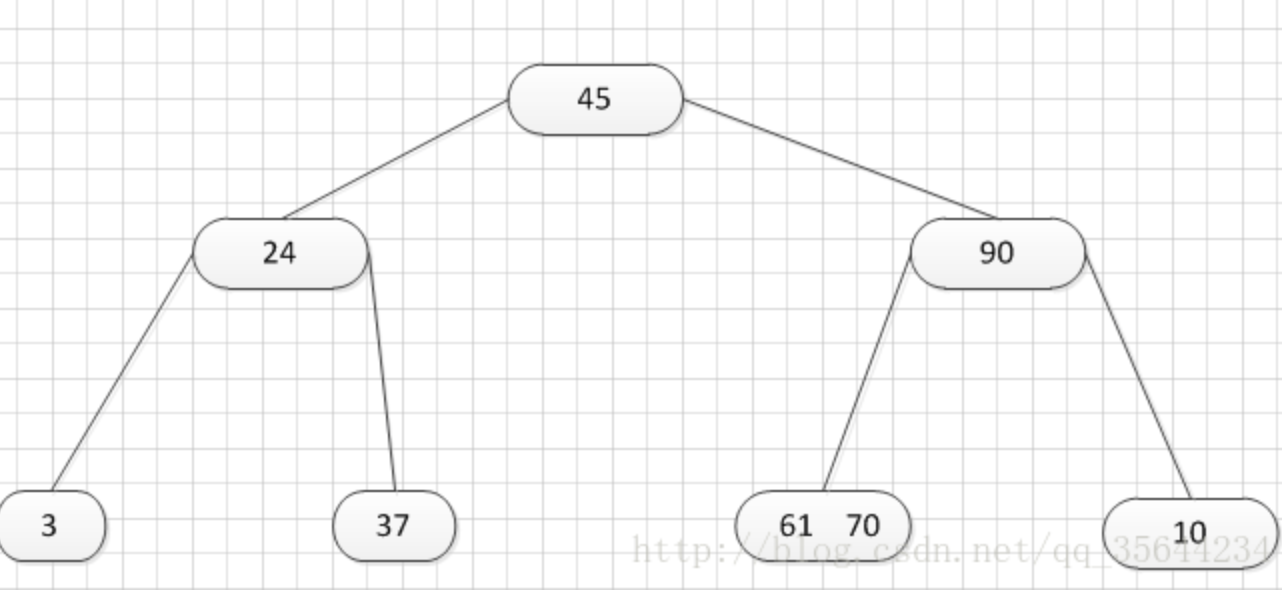
Ok,我已经分别对上述的四种删除的情况都做了举例,大家如果还有什么不清楚的,可以看看代码,估计就可以明白了
5. B-树的基本操作的代码实现
BTree.h文件的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
#ifndef BMT_H_
#define BMT_H_
#include<iostream>
#include<cstdlib>
using namespace std;
#define m 3
typedef int KeyType;
typedef struct BMTNode {
int keynum;
BMTNode * parent;
KeyType key[m + 1];
BMTNode * ptr[m + 1];
BMTNode() : keynum(0), parent(NULL) {
for (int i = 0; i <= m; ++i) {
key[i] = 0;
ptr[i] = NULL;
}//endfor
}//endctor
}*BMT;
typedef struct Node {
int keynum; //关键字的数量
Node * parent; //父亲结点
KeyType key[m + 1]; //记录关键字,但是0号单元不用
Node * ptr[m + 1]; //记录孩子结点的指针
Node() :keynum(0), parent(NULL) {
for (int i = 0; i <= m; i++)
{
key[i] = 0;
ptr[i] = NULL;
}//endfor
}//endcontruct
};
class BTree {
private:
Node * head;
int search(Node *& T, KeyType K); //查找关键字
void insert(Node * & T, int i, KeyType K, Node * rhs); //插入关键字的位置
bool split(Node *& T, int s, Node * & rhs, KeyType & midK); //结点分裂
bool newroot(Node * & T, Node * & lhs, KeyType midK, Node * & rhs);
void RotateLeft(Node * parent, int idx, Node * cur, Node * rsilb);
void RotateRight(Node * parent, int idx, Node * cur, Node * lsilb);
void Merge(Node * parent, int idx, Node * lsilb, Node * cur);
void DeleteBalance(Node * curNode);
void Delete(Node * curNode, int curIdx);
public:
BTree();
Node * gethead();
bool searchKey_BTree(KeyType K, Node * & recNode, int & recIdx);
bool insert_BTree(KeyType k);
bool Delete_BTree(KeyType K);
void Destroy(Node * & T);
void WalkThrough(Node * & T);
};
#endif /* BMT_H_ */
BTree.cpp文件的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
#include"BTree.h"
BTree::BTree() {
this->head = NULL;
}
//结点中,查找关键字序列,是否存在k,私有方法
int BTree::search(Node * & t,KeyType k) {
int i = 0;
for (int j = 1; j <= t->keynum; ++j) {
if (t->key[j] <= k) {
i = j;
}
}
return i;
}
//遍历整个树,查找对应的关键字,公有方法,
bool BTree::searchKey_BTree(KeyType k, Node * & recNode, int & recIdx) {
if (!head) {
//cerr << "树为空" << endl;
return false;
}
Node * p = head;
Node * q = NULL;
bool found = false;
int i=0;
while (p && !found) {
i = this->search(p, k); //记住i返回两种情况:第一种是找到对应的关键字
//第二次是找到了最后一个小于k的关键字下标(主要作用与插入时)
if (i > 0 && p->key[i] == k) {
//找到了记录结点和结点中关键字的下标
recIdx = i;
recNode = p;
return true;
}//endif
else {
recNode = p; // 记录p的值,方便返回
recIdx = i;
p = p->ptr[recIdx]; // 查找下一个结点,
}//endelse
}//endw
return false;
}
//这是在结点的关键字序列中,插入一个而关键字,私有方法
void BTree::insert(Node * & t, int i, KeyType k, Node * rhs) {
//我们需要把关键字序列往后移动,然后插入新的关键字
for (int j = t->keynum; j >= i + 1; --j) {
t->key[j + 1] = t->key[j];
t->ptr[j + 1] = t->ptr[j];
}
//插入新的关键字
t->key[i + 1] = k;
t->ptr[i + 1] = rhs;
++t->keynum;
}
//对对应的结点进行分裂处理,对t结点进行分裂处理,私有方法
bool BTree::split(Node * & t, int s, Node * & rhs, KeyType & midk) {
rhs = new Node;
//rhs为新建的结点,用于保存右半部分的。
if (!rhs) {
overflow_error;
return false;
}
//我们们把t分裂的,所以rhs是t的兄弟结点,有相同的父母
rhs->parent = t->parent;
//其中关键字序列的中间值为
midk = t->key[s];
t->key[s] = 0;
//这个通过画图,就可以知道rhs的0号孩子的指针,就是t的s号结点指针
rhs->ptr[0] = t->ptr[s];
//如果原来的t的s号孩子指针,现在的rhs的0号孩子指针不为空,则需要改变孩子的的父亲结点
if (rhs->ptr[0]) {
rhs->ptr[0]->parent = rhs;
}//endif
t->ptr[s] = NULL;
for (int i = 1; i <= m - s; ++i) {
//现在是把右半部分全部复制到到rhs中
rhs->key[i] = t->key[s + i]; t->key[s + i] = 0;
rhs->ptr[i] = t->ptr[s + i]; t->ptr[s + i] = NULL;
//理由和刚才的理由一样
if (rhs->ptr[i]) {
rhs->ptr[i]->parent = rhs;
}//endif
}//endfor
rhs->keynum = m - s;
t->keynum = s - 1;
return true;
}
//新建一个新的结点,私有方法
bool BTree::newroot(Node * & t, Node * & lhs, KeyType midk, Node * & rhs) {
Node * temp = new Node;
if (!temp) {
overflow_error;
return false;
}
temp->keynum = 1;
temp->key[1] = midk;
temp->ptr[0] = lhs;
//左孩子不为空
if (temp->ptr[0]) {
temp->ptr[0]->parent = temp;
}
temp->ptr[1] = rhs;
//右孩子不为空
if (temp->ptr[1]) {
temp->ptr[1]->parent = temp;
}
t = temp;
return true;
}
//插入一个k(public方法)
bool BTree::insert_BTree(KeyType k) {
Node * curNode = NULL;
int preIdx = 0;
if (this->searchKey_BTree(k, curNode, preIdx)) {
cout << "关键已经存在" << endl;
return false;
}
else {
//没有找到关键字
KeyType curk = k;
Node * rhs = NULL;
bool finished = false;
while (!finished && curNode) {
//不管是否合法,直接先插入刚才找到的那个关键字序列中
this->insert(curNode, preIdx, curk, rhs);
if (curNode->keynum < m) {//满足条件,直接退出
finished = true;
}
else {
int s = (m + 1) / 2; //s为中间值的下标
if (!this->split(curNode, s, rhs, curk)) {
//分裂失败,直接返回
return false;
}
if (curNode->parent == NULL) {
//如果curNode已经是根节点了,则可以直接退出了
break;
}
else {
//如果有那个父亲结点的话,此时curk指向的是原来这个结点中间值
//所以需要和父亲结点融合
curNode = curNode->parent;
preIdx = this->search(curNode, curk);
}
}
}
//如果head为空树,或者根结点已经分裂为结点curNode和rhs了,此时是肯定到了
//根结点了
if (!finished && !this->newroot(head, curNode, curk, rhs)) {
cerr << "failed to create new root" << endl;
exit(EXIT_FAILURE);
}
}
}
//删除结点k,找到合适的结点(public方法)
bool BTree::Delete_BTree(KeyType k) {
Node * curNode = NULL;
int curIdx = 0;
if (this->searchKey_BTree(k, curNode, curIdx)) {
this->Delete(curNode, curIdx);
return true;
}
else {
return false;
}
}
//删除对应的进入结点,去删除关键字
void BTree::Delete(Node * curNode, int curIdx) {
//curIdx不合法法时,直接返回
if (curIdx<0 || curIdx>curNode->keynum) {
return;
}
while (true) {//这里的步骤不是很清楚,等下来讨论
//此时说明我们是处于非叶子结点
if (curNode->ptr[curIdx - 1] && curNode->ptr[curIdx]) {
//使用右子树中最小的关键字替换对应当前的关键的,然后删除那个最小的关键字
Node * p1 = curNode->ptr[curIdx];
while (p1->ptr[0]) {
p1 = p1->ptr[0];
}
int res = p1->key[1];
this->Delete_BTree(p1->key[1]);
curNode->key[curIdx] = res;
break;
}
else if (!curNode->ptr[curIdx - 1] && !curNode->ptr[curIdx])
{ // is leaf
for (int i = curIdx; i <= curNode->keynum; ++i) {
curNode->key[i] = curNode->key[i + 1];
// all ptr are NULL , no need to move.
}//end for.
--curNode->keynum;
this->DeleteBalance(curNode);
break;
}
else { //debug
cerr << "Error" << endl;
}
}//endw
}
//删除对应关键字后,我们需要对删除后的树进行调整
void BTree::DeleteBalance(Node * curNode) {
int lb = (int)m / 2;
Node * parent = curNode->parent;
while (parent && curNode->keynum < lb) {//说明删除了关键字后,原来的那个结点已经不
//符合B-树的最小结点要求,这个不懂可以回去看看条件
int idx = 0;
//找到curNode在其父亲节点中的位置
for (int i = 0; i <= parent->keynum; ++i) {
if (parent->ptr[i] == curNode) {
idx = i;
break;
}
}
Node * lsilb = NULL; Node * rsilb = NULL;
if (idx - 1 >= 0) {//如果当前结点有左兄弟
lsilb = parent->ptr[idx - 1];
}
if (idx + 1 <= parent->keynum) {//说明当前结点有右兄弟
rsilb = parent->ptr[idx + 1];
}
//只要右兄弟存在,而且满足rsilb->keynum > lb,即是删除的调整的情况2
if (rsilb && rsilb->keynum > lb) {
this->RotateLeft(parent, idx, curNode, rsilb);
break;
}//如果右兄弟不满足,而左兄弟满足,同样可以
else if (lsilb && lsilb->keynum > lb) {
this->RotateRight(parent, idx, curNode, lsilb);
break;
}//如果左右兄弟都不满足,那就是情况3了,
else {
//合并到左兄弟,
if (lsilb)
this->Merge(parent, idx, lsilb, curNode);
else//没有左兄弟,合并到右兄弟
this->Merge(parent, idx + 1, curNode, rsilb);
// potentially causing deficiency of parent.
curNode = parent;
parent = curNode->parent;
}
}
if (curNode->keynum == 0) {
// root is empty,此时树为空
head = curNode->ptr[0];
delete curNode;
}//endif
}
void BTree::RotateLeft(Node * parent, int idx, Node * cur, Node * rsilb) {
//这个是在右兄弟存在的情况下,而且满足rsilb->keynum > lb,则我们需要从把
//右兄弟结点中的最小关键字移动到父亲结点,而父亲结点中小于该右兄弟的关键字的关键字
//就要下移到刚刚删除的那个结点中。
//父亲结点中某个结点下移
cur->key[cur->keynum + 1] = parent->key[idx + 1];
cur->ptr[cur->keynum + 1] = rsilb->ptr[0]; //
if (cur->ptr[cur->keynum + 1]) {
cur->ptr[cur->keynum + 1]->parent = cur;
}
rsilb->ptr[0] = NULL;
++cur->keynum;
parent->key[idx + 1] = rsilb->key[1];
rsilb->key[idx] = 0;
//右兄弟上移一个结点到父亲结点,
for (int i = 0; i <= rsilb->keynum; ++i) {//删除最靠右的那个结点
rsilb->key[i] = rsilb->key[i + 1];
rsilb->ptr[i] = rsilb->ptr[i + 1];
}
rsilb->key[0] = 0;
--rsilb->keynum;
}
void BTree::RotateRight(Node * parent, int idx, Node * cur, Node * lsilb) {
//这个是在左兄弟存在的情况下,而且满足lsilb->keynum > lb,则我们需要从把
//左兄弟结点中的最大关键字移动到父亲结点,而父亲结点中大于该左兄弟的关键字的关键字
//就要下移到刚刚删除的那个结点中。
//因为是在左边插入
for (int i = cur->keynum; i >= 0; --i) {//因为左边的都比右边小,所以要插入第一个位置
cur->key[i + 1] = cur->key[i];
cur->ptr[i + 1] = cur->ptr[i];
}
//在第一个位置插入父亲结点下移下来的结点
cur->key[1] = parent->key[idx];
cur->ptr[0] = lsilb->ptr[lsilb->keynum];
if (cur->ptr[0])
cur->ptr[0]->parent = cur;
lsilb->ptr[lsilb->keynum] = NULL;
++cur->keynum;
// from lsilb to parent.
parent->key[idx] = lsilb->key[lsilb->keynum];
lsilb->key[lsilb->keynum] = 0;
--lsilb->keynum;
}
void BTree::Merge(Node * parent, int idx, Node * lsilb, Node * cur) {
//函数实现都是往lsilb上合并,首先是先把cur中的剩余部分,全部合到左兄弟中个,
for (int i = 0; i <= cur->keynum; ++i) {
lsilb->key[lsilb->keynum + 1 + i] = cur->key[i];
lsilb->ptr[lsilb->keynum + 1 + i] = cur->ptr[i];
if (lsilb->ptr[lsilb->keynum + 1 + i])
lsilb->ptr[lsilb->keynum + 1 + i] = lsilb;
}
//然后再把父亲结点中的idx对应的内容添加到左兄弟
lsilb->key[lsilb->keynum + 1] = parent->key[idx];
lsilb->keynum = lsilb->keynum + cur->keynum + 1;
delete cur;
//然后更新我们的父亲结点内容
for (int i = idx; i <= parent->keynum; ++i) {
parent->key[i] = parent->key[i + 1];
parent->ptr[i] = parent->ptr[i + 1];
}//end for.
--parent->keynum;
}
void BTree::Destroy(Node * & T) { //是否空间
if (!T) { return; }
for (int i = 0; i <= T->keynum; ++i)
Destroy(T->ptr[i]);
delete T;
T = NULL;
return;
}
void BTree::WalkThrough(Node * &T) {
if (!T) return;
static int depth = 0;
++depth;
int index = 0;
bool running = true;
while (running) {
int ans = 0;
if (index == 0) {
ans = 2;
}
else {
cout << "Cur depth: " << depth << endl;
cout << "Cur Pos: " << (void*)T << "; "
<< "Keynum: " << T->keynum << "; " << endl;
cout << "Index: " << index << "; Key: " << T->key[index] << endl;
do {
cout << "1.Prev Key; 2.Next Key; 3.Deepen Left; 4.Deepen Right; 5.Backup << endl;
cin >> ans;
if (1 <= ans && ans <= 5)
break;
} while (true);
}
switch (ans) {
case 1:
if (index == 1)
cout << "Failed." << endl;
else
--index;
break;
case 2:
if (index == T->keynum)
cout << "Failed" << endl;
else
++index;
break;
case 4:
if (index > 0 && T->ptr[index])
WalkThrough(T->ptr[index]);
else
cout << "Failed" << endl;
break;
case 3:
if (index > 0 && T->ptr[index - 1])
WalkThrough(T->ptr[index - 1]);
else
cout << "Failed" << endl;
break;
case 5:
running = false;
break;
}//endsw
}//endw
--depth;
}
Node * BTree::gethead() {
return this->head;
}
B+树
1.为什么要B+树
由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引,而B树则常用于文件索引。
2.简介
同样的,以一个m阶树为例:
- 根结点只有一个,分支数量范围为[2,m];
- 分支结点,每个结点包含分支数范围为[ceil(m/2), m];
- 分支结点的关键字数量等于其子分支的数量减一,关键字的数量范围为[ceil(m/2)-1, m-1],关键字顺序递增;
- 所有叶子结点都在同一层;
3. 操作
其操作和B树的操作是类似的,不过需要注意的是,在增加值的时候,如果存在满员的情况,将选择结点中的值作为新的索引. 还有在删除值的时候,索引中的关键字并不会删除,也不会存在父亲结点的关键字下沉的情况,因为那只是索引。
4.B树和B+树的区别
这都是由于B+树和B具有这不同的存储结构所造成的区别,以一个m阶树为例。
- 关键字的数量不同;B+树中分支结点有m个关键字,其叶子结点也有m个,其关键字只是起到了一个索引的作用,但是B树虽然也有m个子结点,但是其只拥有m-1个关键字。
- 存储的位置不同;B+树中的数据都存储在叶子结点上,也就是其所有叶子结点的数据组合起来就是完整的数据,但是B树的数据存储在每一个结点中,并不仅仅存储在叶子结点上。
- 分支结点的构造不同;B+树的分支结点仅仅存储着关键字信息和儿子的指针(这里的指针指的是磁盘块的偏移量),也就是说内部结点仅仅包含着索引信息。
- 查询不同;B树在找到具体的数值以后,则结束,而B+树则需要通过索引找到叶子结点中的数据才结束,也就是说B+树的搜索过程中走了一条从根结点到叶子结点的路径。