杂谈 | socket 服务器编程里的那些事

面向 TCP 的 socket 开发现在场景比较普及,我们常见的像 tomcat, jetty 之类的 web 服务, 还有linux 的 sshd 用户认证服务, mysql server 等等, 他们使用到的都是 tcp 通信技术。
在基于tcp的 socket 开发里面, 服务端开发是比较复杂的一点,主要是它不但要正确处理用户来的请求消息, 还要及时处理异常的用户访问状态,并且要保障服务吞吐。 如何才能很好的解决上面的问题是我们比较关注的事情。
有关TCP的基础问题可以参考 TCP/IP TCP 篇 - 董涛的博客 - Aiden Blog
我们下面就讨论下在基于 tcp 的 socket 服务器编程里一些基本原理与常见的问题与思路。
LISTEN
tcp socket server 端的开发第一件事就是建立 socket 并进入 LISTEN 状态。
在 linux 系统开发中, 一个 socket 进入 LISTEN 状态需要三步。
第一步建立 socket : int socket(int domain, int type, int protocol); 第二步 bind 端口 : int bind(int socket, const struct sockaddr *address, socklen_t address_len); 第三步 listen : int listen(int socket, int backlog);
到了第四步服务端已经准备好,当客户端连接到达时, 进行 accept 建立对话 : int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
1
2
3
4
5
6
7
8
9
10
11
int socketfd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
struct sockaddr_in server_address;
memset(&server_address, 0, sizeof(server_address));
server_address.sin_family = AF_INET;
server_address.sin_port = htons(port);
inet_pton(AF_INET, "0.0.0.0", &server_address.sin_addr.s_addr);
bind(socketfd, (struct sockaddr *) &server_address, sizeof(server_address));
listen(socketfd, 128);
在用 Java 开发过程中, 由于封装了这些细节上的处理, 所以你可以直接这样
1
2
ServerSocket serverSocket = new ServerSocket();
serverSocket.bind(new InetSocketAddress(8080), 128);
类似这样, 建立 LISTEN 方式还有很多, 但是有些细节问题需要我们了解。
字节序的问题
很多上层开发人员其实一直不太了解, 网络字节序跟主机字节序是不一致的。 网络中使用大端字节序, 而在主机中使用的是小端字节序。
什么意思呢? 举个例子:
1
2
3
4
5
值 : 0x3fe8f2ac
主机序列 : |ac|f2|e8|3f|
网络序列 : |3f|e8|f2|ac|
低地址 <--|--|--|--|--|--> 高地址
可以看出,大端小端的变化是以字节为整体,在排列上是有差异的。 有关字节序的细节问题大家可以参考下 [理解字节序 - 阮一峰的网络日志]
由于网络处理过程中数据包都是采用大端字节序来处理的, 为了能够在传输过程中正确解读报头信息并且传输无误,有关地址,端口等的数据包包头信息都需要将主机字节序转成大端字节序,然后设置到包头里面。
系统提供了若干的字节序转换函数,可以方便我们对2字节,4字节,8字节数值的相互转化。
如果在我们发的信息中如果有数值上的传输, 为了防止不同系统主机的字节序不一致,我们也可以使用这种转换方式,保证解读准确。
bind 的问题
Java 上如果 bind 端口时,地址没有填写地址信息, 结果也是地址信息填写为 0.0.0.0.
0.0.0.0 其实并不是一个有效的地址, 但服务器一般情况都填写这个值, 它被内核处理为 绑定本机上的所有网络接口。
通常情况下,通过 ifconfig 命令我们能看到本机有多少个网络接口。
我们调用 bind 时候, 系统允许我们将服务监听在哪个端口上面, 比如我要监听本地环回接口。 我可以将地址设置为 127.0.0.1.
这时候我们调用listen的时候。
1
2
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:8080 0.0.0.0:* LISTEN 1533/./socket_serve
这个表示我的服务在环回接口上监听8080端口, 我的服务只能获取到从这个网卡过来的数据。
如果我的服务想获取到这个主机上所有网卡过来的请求消息, 那么我就可以设置成0.0.0.0.
1
2
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 1598/./socket_serve
这里还有一个问题就是, 我如果有一个服务在网卡A上监听了某个端口, 现在是否可以在网卡B上开另一个服务监听此端口呢?
抱歉,不可以。这个端口门牌号是主机层面的。
并且这个 port 我们通过协议也可以看出, 是两个字节大小, 所以允许我们的端口绑定范围是 1~65535, 并且 1~1024普通用户没有绑定权限。
listen 里面也需要注意
我们调用 listen 的时候服务这时候正式建立监听。 listen 系统调用参数比较少, 而且基本不会产生 errno 所以大家很容易会忽略这个。
其实这里面也有几个点需要关注一下。
listen 过程内核里维护了一个数据结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
struct request_sock_queue {
struct request_sock *rskq_accept_head; // 全连接队列链表头
struct request_sock *rskq_accept_tail; // 全连接队列链表尾
rwlock_t syn_wait_lock;
u8 rskq_defer_accept;
struct listen_sock *listen_opt; // 半连接结构指针
struct fastopen_queue *fastopenq;
};
struct listen_sock {
u8 max_qlen_log;
u8 synflood_warned;
/* 2 bytes hole, try to use */
int qlen;
int qlen_young;
int clock_hand;
u32 hash_rnd;
u32 nr_table_entries;
struct request_sock *syn_table[0];
};
struct request_sock {
struct request_sock *dl_next; /* Must be first member! */
u16 mss;
u8 retrans;
u8 cookie_ts; /* syncookie: encode tcpopts in timestamp */
/* The following two fields can be easily recomputed I think -AK */
u32 window_clamp; /* window clamp at creation time */
u32 rcv_wnd; /* rcv_wnd offered first time */
u32 ts_recent;
unsigned long expires;
const struct request_sock_ops *rsk_ops;
struct sock *sk;
u32 secid;
u32 peer_secid;
};
这里面有两个数据结构值得我们关注一下,一个是半连接队列, 另一个是全连接队列。
全连接的队列长度为 : min(backlog, somaxconn) 半连接的长度为 : max(8, min(backlog、somaxconn、tcp_max_syn_backlog))
net.core.somaxconn 默认为128. net.ipv4.tcp_max_syn_backlog 默认为 256.
这两个队列有什么用呢? 图像说明一下。

当调用 listen 之后, 服务器开始在指定端口上进入监听状态, 这时候便允许用户来进行 connnect.
connect 过程需要进行三次握手,建立会话。当客户端第一次发送 SYN 到服务器时候, 服务器内核这时候会自动返回 SYN/ACK 并将这个会话结构request_sock 放入到半连接队列里。
当完成三次握手后, 内核在把半链接里的这个结构放入到全链接里面, 等待服务器 accept.
如果半链接队列被占满, 来自客户端的 SYN 消息将被服务器忽略, 客户端因为收不到对方的SYN/ACK定时器超时后会进行重试, 多次重试无过后引发 connect time out.
如果全链接队列被占满,来自客户端对SYN/ACK 的 ACK 的处理方式取决于 tcp_abort_on_overflow 的值, 如果 tcp_abort_on_overflow=1 则向客户端发送 RST 错误。 否则这个ACK就被丢弃,这个时候客户端无法感知,以为成功建立了链接,状态将转变为 ESTABLISHED 状态。
但是发送的数据包将被服务端丢弃, 客户端最终等待超时。
所以为了防止并发请求太大导致系统来不及处理引发队列溢出的现象,我们应该适当调整我们的队列大小。
SYN Flood
SYN Flood 是DOS 攻击的一种常见手法, 用户恶意对服务器进行三次握手请求, 当收到服务的应答后忽略消息, 以此来不断占用服务器半连接队列,直至打满。
SYN Cookie 是对TCP服务器端的三次握手做一些修改,专门用来防范 SYN Flood 攻击的一种手段。它的原理是,在TCP服务器接收到 TCP SYN 包并返回 TCP SYN|ACK 包时,不分配一个专门的数据区,而是根据这个SYN包计算出一个cookie值。这个cookie作为将要返回的SYN ACK包的初始序列号。 当客户端返回一个ACK包时,根据包头信息计算cookie,与返回的确认序列号(初始序列号 + 1)进行对比,如果相同,则是一个正常连接,然后,分配资源,建立连接。
这种方式虽然能够解决链接被打满的情况, 但是也是存在一些问题, 比如交互过程不能有任何选项, 而且会降低系统性能,所以也要妥善处理。
请求处理
当客户端跟服务器完成握手建立链接之后, 双方便可以进行通信。
socket 是属于全双工通信方式, 这就意味着,双方的信息发送与接受完全自由,任何一个时间都可以进行信息的发送与接受。
有两个需要解决的问题:
- 如何处理你的发送与接受逻辑

用一个形象的例子就相当于打电话, 我们说话与收听就是一个全双工的方式, 但是为了沟通有效, 我们得有一个正确的合理的交互方式, 如果同一个时间,大家一起说话,或者大家一起在收听对方意见,那么这个信息交互就显得很混乱。
- 如何保证交互的信息完整性

在 tcp 里面是面向流的通信, 意思是说,tcp 只能告知你收到的数据是准确无误的, 但是没法对数据做分割,当接收到一条信息时,没有办法去标识一个信息的完整性。
在有些地方说的粘包(虽然我不太认同这个说法), 它的意思其实就是说没有处理好信息完整性造成的现象。
面对上面的两个问题, 我们需要在开发中定义好自己的应用层协议, 来保证我们的交互质量。
HTTP 服务里的通信协议
我们列举一下 http 服务是如何处理上面的问题的。
首先 http server 是请求应答式的, http 服务建立起来后,需要等待客户端链接并且告知服务器请求的资源内容, 然后服务器根据客户端请求的内容去下发资源。
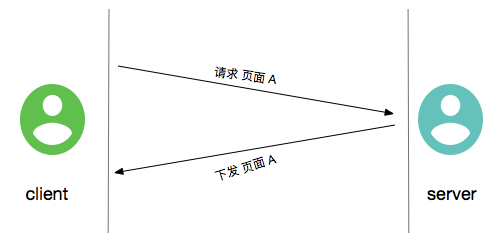
为了标识一个请求或应答的完整性, http 将协议分为三部分: 协议部分,头部部分,内容部分。
HTTP 请求协议

1
2
3
4
5
6
7
8
GET / HTTP/1.1
User-Agent: curl/7.40.0
Host: localhost:18082
Accept: */*
Content-Length: 11
Content-Type: application/x-www-form-urlencoded
hello world
HTTP 响应协议

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
HTTP/1.1 404 Not Found
Date: Tue, 24 Sep 2019 08:04:11 GMT
Cache-Control: must-revalidate,no-cache,no-store
Content-Type: text/html;charset=iso-8859-1
Content-Length: 317
Server: Jetty(9.4.10.v20180503)
<html>
<head>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8"/>
<title>Error 404 Not Found</title>
</head>
<body><h2>HTTP ERROR 404</h2>
<p>Problem accessing /. Reason:
<pre> Not Found</pre></p><hr><a href="http://eclipse.org/jetty">Powered by Jetty:// 9.4.10.v20180503</a><hr/>
</body>
</html>
从上面我们可以看出, 对于一个请求来说, 当接受到 \r\n\r\n 时, 表示一个请求或者响应信息的协议部分跟头部部分已经结束,每一行可以使用\r\n来区分从中可以解析出响应的字段。
如果除了这两部分外包信息还有数据部分, 那么头部中有一个特殊的头部名称Content-Length用来标志有数据部分, 并且指出数据部分的字节数。
通过这两个部分, 我们就可以确认我们获得的信息是不是完整的请求或者响应信息了。
如果拿到的数据并不完整,我们 可以使用 cache 来维护这部分请求数据, 当数据完整之后在一次返回给逻辑处。

但这样子也有一个风险。 如果有恶意用户利用这一点, 不停的向我们的服务提供这种不完整的数据, 这样子我们的服务内存很容易打满。
应对这种情况的发生,我们可以给每一个请求一个保活时间。外加一个请求的包体大小上限。
并发问题
server 端同一时间不能仅仅只服务于一个对象, 这样当大量的请求到达时, 多数的请求短时间内无法得到满足,效率很低, 所以一般采取并发处理的措施。
简单并发处理
最直接的方式是,当一个链接到达时,我们启用一个进程或者线程去单独处理这部分的请求, 当完成请求时我们再关闭请求,释放掉这个进程或线程。
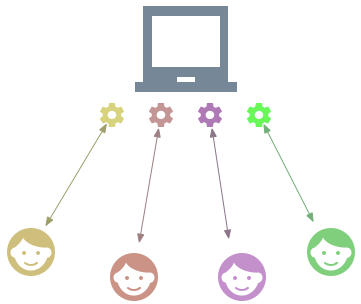
值得说明的是, 使用多进程也是可以实现这种并发处理的。 一种方式是accept 之后 fork 子进程,通过子进程共享父进程打开文件描述符的方式。 另一种方式是通过 unix 域套接字发送描述符来实现。
使用这种模型的优点是逻辑实现方便,不太用考虑与其他线程的同步问题。
对于频繁建立连接,断开连接的短链接来说,这种场景会造成线程频繁创建与释放, 这些操作造成了较高的系统开销。 如果这种场景很常见,我们可以采用线程池的概念, 预开一部分线程。使用通信机制来通知线程处理请求, 线程资源紧张时,增加线程池容量, 当线程资源长时间空闲时,释放一些不必要的线程。
对于部分长连接,使用这种模型也不太合适。 长连接应用多数时间在静默状态,这样会一直占用一个线程,对系统资源造成浪费。
多路复用IO的使用场景
对于长连接的场景,我们推荐多路复用 IO 模型来处理用户请求。
多路复用IO 是将与客户端连接的socket 交给内核去监听, 如果发现内核发现 socket 有请求到达,再通知给服务进程, 转到进程处理。
多路复用IO 类型主要有 select, poll, epoll(linux), kqueue(freeBsD) 等几种类型。
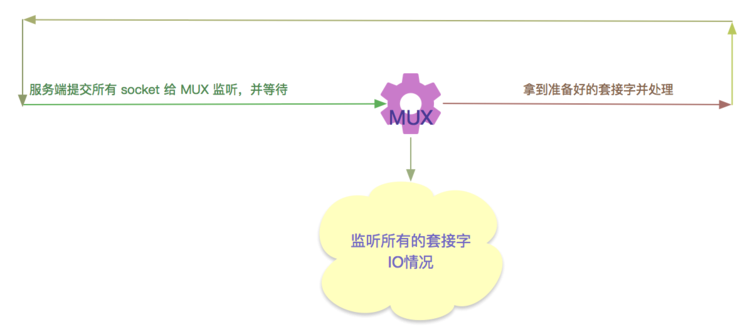
我们主要介绍下 select 与 epoll 的原理, poll 与 select 大致类似, epoll 与 kqueue 大致类似。
select
select 接口 int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
fd_set 结构为我们要监控的描述符集合。 nfds 需要设置为最大的文件描述符集合加一。 readfds, writefds, exceptfds 可以分别设置需要监听的 读事件, 写事件, 异常事件 集合。 timeout 为监听的等待时间上限, 如果时间超时没有消息,仍然会返回。
在每次调用select前, 需要使用 void FD_SET(int fd, fd_set *set); 宏定义将要监听描述符放入到 fd_set 结构集合里, 然后调用 select 监听。
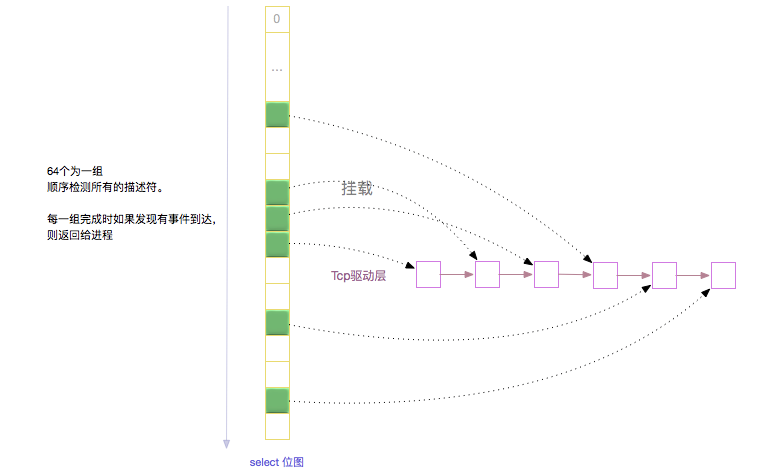
select 方法的执行过程大致为 : select -> SYSCALL_DEFINE5() -> core_sys_select() -> do_select()
select 系统调用转到内核层, 需要拷贝参数到内核空间,为了存放这些监听标志位大致需要 6*nfds byte 大小的空间(2*(readfds + writefds + exceptfds) 剩下的一半用来存放范围的标志)。 在内核里面有一个 stack_fds栈空间, 如果 6*nfds 需要的空间小于这个栈空间, 那么就需要启用kmalloc申请一个连续物理块堆空间来存放这些数据。
select 核心位于 do_select 里面. do_select 在死循环里面轮询校验这些监听描述符, 第一次循环校验描述符时需要把这个描述符挂到驱动的等待队列中,并检测事件又没有到达,后续循环只监测事件。 当每校验完一组描述符后如果发现超时时间到了或者发现有事件到达, 则将结果位图返回给用户传入参数的地址空间中。
用户层需要自己拿描述符去位图比对int FD_ISSET(int fd, fd_set *set);, 才可以确认描述符是否有事件到达。
epoll
epoll 系统调用接口如下:
1
2
3
int epoll_create(int size); // 创建一个 epoll 句柄
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); // 向 epoll 注册事件
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); // 等待并获取
使用 epoll_create 为我们创建一个epoll文件描述符 epfd, 后面我们可以 epoll_ctl 为这个 epoll 注册或者删除指定的监控事件。
epoll_wait 用来从epoll中拿到当前就绪的事件。
epoll的高效就在于,当我们调用epoll_ctl往里塞入百万个句柄时,epoll_wait仍然可以飞快的返回,并有效的将发生事件的句柄给我们用户。
这是由于我们在调用 epoll_create 时,内核除了帮我们在epoll文件系统里建了个file结点,在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket外,还会再建立一个list链表,用于存储准备就绪的事件.
当我们执行epoll_ctl时,除了把socket放到epoll文件系统里file对象对应的红黑树上之外,还会给内核中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪list链表里。所以,当一个socket上有数据到了,中断触发的回调就来把socket插入到准备就绪链表里了。
红黑树结构使我们的插入删除操作都是 O(1)
回调将事件的处理交给了相应的驱动部分, 减少了主动轮询的消耗。所以当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。
有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。所以,epoll_wait非常高效。
调用链为 :
epoll_create -> SYSCALL_DEFINE1(epoll_create, int, size) -> sys_epoll_create1 -> SYSCALL_DEFINE1(epoll_create1, int, flags)
epoll_ctl -> SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd, struct epoll_event __user *, event) -> ep_insert, ep_remove, ep_modify, ep_find
epoll_wait -> SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events, int, maxevents, int, timeout) -> ep_poll
比较
从上面来看 epoll 要比 select 显得高效, 主要表现在 :
- 从监听上来看,select 每次都要主动去轮询查看所有的描述符, 而 epoll 只是去看就绪链中是否有数据。
- select 每次都需要将整个位图信息返回到应用程序里, 应用层还需要轮询检查所有的描述符是否被置位,epoll 则只返回有事件到达的描述符集合。
Netty 中使用多路复用的实例
netty 是 java 网络编程中一个成熟的框架, 其内部也是结合多线程与多路复用来实现的。
netty 里面的服务模型主要依靠 NioEventLoopGroup来实现的 。
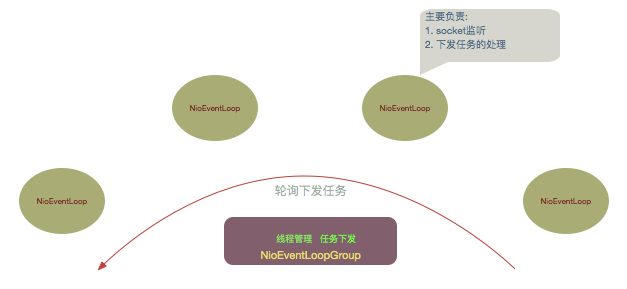
NioEventLoopGroup 使用数组形式维护了一个 NioEventLoop 线程池集合. 而 NioEventLoop 使用多路复用技术(linux下为epoll实现)来监听所有的描述符。
为了使得每个NioEventLoop线程能够负载均衡, socket 的注册使用了轮询方式以此挂载到每一个 NioEventLoop 的 select 中, 对监听到的客户端请求的处理也轮询到了这些 NioEventLoop中。
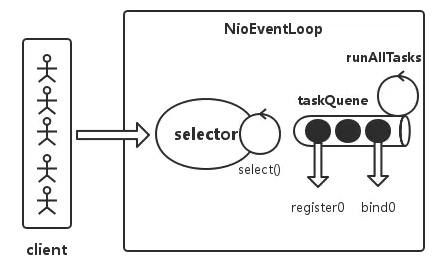
所以 NioEventLoop 的任务主要有两部分:
- 监听 select 中事件的发生。
- 对来自客户端请求的事件进行处理。
netty 还允许我们灵活的控制处理这两种事件的时间比例 ioRatio,默认为50,表示允许两种任务执行的时间相等。