TCP/IP 教程 | TCP 篇

协议
特性
- 应用数据被分割成TCP认为最适合发送的数据块。这和UDP完全不同,应用程序产生的数据报长度将保持不变。由TCP传递给IP的信息单位称为报文段或段(segment)。
- 当TCP发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
- 当TCP收到发自TCP连接另一端的数据,它将发送一个确认。这个确认不是立即发送,通常将推迟几分之一秒。
- TCP将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP将丢弃这个报文段和不确认收到此报文段(希望发端超时并重发)。
- 既然TCP报文段作为IP数据报来传输,而IP数据报的到达可能会失序,因此TCP报文段的到达也可能会失序。如果必要,TCP将对收到的数据进行重新排序,将收到的数据以正确的顺序交给应用层。
- 既然IP数据报会发生重复,TCP的接收端必须丢弃重复的数据。
- TCP还能提供流量控制。TCP连接的每一方都有固定大小的缓冲空间。TCP的接收端只允许另一端发送接收端缓冲区所能接纳的数据。这将防止较快主机致使较慢主机的缓冲区溢出。
TCP 首部

| 字段 | 解释 |
|---|---|
| 源端和目的端的端口号 | 用于寻找发端和收端应用进程。这两个值加上IP首部中的源端IP地址和目的端IP地址唯一确定一个TCP连接。 |
| 序号 | 从TCP发端向TCP收端发送的数据字节流,它表示在这个报文段中的的第一个数据字节。如果将字节流看作在两个应用程序间的单向流动,则TCP用序号对每个字节进行计数。序号是32 bit的无符号数,序号到达232-1后又从0开始。 |
| 确认序号 | 确认序号包含发送确认的一端所期望收到的下一个序号。因此,确认序号应当是上次已成功收到数据字节序号加1。只有ACK标志为1时确认序号字段才有效。 |
| 窗口大小 | 提供流量控制. 窗口大小为字节数,起始于确认序号字段指明的值,这个值是接收端正期望接收的字节。窗口大小是一个16 bit字段,因而窗口大小最大为65535字节。 |
| 检验和 | 覆盖了整个的TCP报文段:TCP首部和TCP数据。 |
| 紧急指针 | 只有当URG标志置1时紧急指针才有效。紧急指针是一个正的偏移量,和序号字段中的值相加表示紧急数据最后一个字节的序号。TCP的紧急方式是发送端向另一端发送紧急数据的一种方式。 |
标志位

tcp 交互基本
建立链接
1
2
3
ip-172-31-8-39.ec2.internal.22130 > ip-172-31-27-167.ec2.internal.jamlink: Flags [S], cksum 0x8a9f (correct), seq 2513622578, win 26883, options [mss 8961,nop,nop,sackOK,nop,wscale 9], length 0
ip-172-31-27-167.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.22130: Flags [S.], cksum 0x7c33 (incorrect -> 0xe811), seq 3380664571, ack 2513622579, win 26883, options [mss 8961,nop,nop,sackOK,nop,wscale 9], length 0
ip-172-31-8-39.ec2.internal.22130 > ip-172-31-27-167.ec2.internal.jamlink: Flags [.], cksum 0xaf01 (correct), seq 1, ack 1, win 53, length 0
这是一个实际的建立链接的包信息, 链接的建立需要三次对话,也就是我们俗称的三次握手。
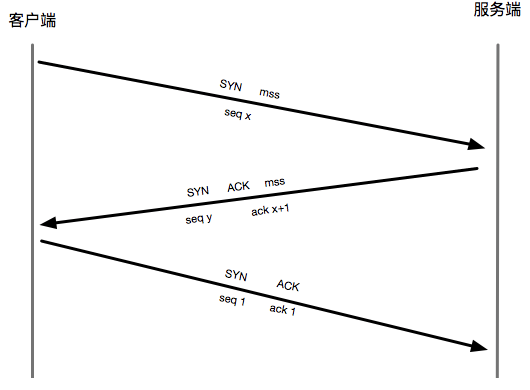
客户端首先发起链接请求, 置 SYN 标志为1, 设置一个随机的序号, 并通告自己的 mss(最长报文信息)。
服务端收到这个 SYN 的信息之后,确认是建立链接的报文请求, 然后设置SYN, ACK 标志, 序列号设置一个随机数, 确认序列号设置为对方序列号加一,表示确定收到对方报文,并通告自己的mss.
讲过这两次对话, 双方基本信息已经确认。
接下来客户端发送ACK 标志的报文, 设置自己的 序列号为1, 确认序列号为1, 表示要开始发送正式的数据流信息, 并告知服务器下个包从序列号为1开始。
完成双方同步信息。
通信过程
1
2
3
4
5
6
7
ip-172-31-8-39.ec2.internal.22130 > ip-172-31-27-167.ec2.internal.jamlink: Flags [P.], cksum 0x1d15 (correct), seq 1:13, ack 1, win 53, length 12
ip-172-31-27-167.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.22130: Flags [.], cksum 0x7c27 (incorrect -> 0xaef5), seq 1, ack 13, win 53, length 0
ip-172-31-27-167.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.22130: Flags [P.], cksum 0x7c33 (incorrect -> 0x1d09), seq 1:13, ack 13, win 53, length 12
ip-172-31-8-39.ec2.internal.22130 > ip-172-31-27-167.ec2.internal.jamlink: Flags [.], cksum 0xaee9 (correct), seq 13, ack 13, win 53, length 0
ip-172-31-8-39.ec2.internal.22130 > ip-172-31-27-167.ec2.internal.jamlink: Flags [P.], cksum 0x124f (correct), seq 13:2061, ack 13, win 53, length 2048
ip-172-31-27-167.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.22130: Flags [P.], cksum 0x8427 (incorrect -> 0x0a47), seq 13:2061, ack 2061, win 61, length 2048
ip-172-31-8-39.ec2.internal.22130 > ip-172-31-27-167.ec2.internal.jamlink: Flags [P.], cksum 0xe71f (correct), seq 2061:4109, ack 2061, win 61, length 2048
我们在 ip-172-31-27-167.ec2.internal.jamlink 上面开发了一个简单的 echo 服务, 发送了两条数据, 看下现在的情况。
首先 ip-172-31-8-39.ec2.internal 向 ip-172-31-27-167.ec2.internal 发送了长度为12字节的数据, 因为刚建立链接, 所以序列号为1. 然后 ip-172-31-27-167.ec2.internal 接受到数据包之后, 更新确认号为包的序列号+长度, 然后范围ack包。 下一步 ip-172-31-27-167.ec2.internal 将长度为12的包重新返回给客户端, 序列号为1长度为12 ip-172-31-8-39.ec2.internal 接收到包时设置 ack 为13,将确认包返回回去,告知已经接受到。
。。。
从上面的报文中我们发现,当完成链路的建立之后, 数据包中一直设置有ack标签,用来告知对端下一个要发送的包的序号。
链接终止
1
2
3
4
5
6
7
ip-172-31-8-39.ec2.internal.27392 > ip-172-31-27-167.ec2.internal.jamlink: Flags [F.], cksum 0x4843 (correct), seq 1, ack 1, win 53, length 0
1567680405.068498 IP (tos 0x0, ttl 64, id 16579, offset 0, flags [DF], proto TCP (6), length 40)
ip-172-31-27-167.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.27392: Flags [.], cksum 0x7c27 (incorrect -> 0x4843), seq 1, ack 2, win 53, length 0
1567680410.065148 IP (tos 0x0, ttl 64, id 16580, offset 0, flags [DF], proto TCP (6), length 40)
ip-172-31-27-167.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.27392: Flags [F.], cksum 0x7c27 (incorrect -> 0x4842), seq 1, ack 2, win 53, length 0
1567680410.066504 IP (tos 0x0, ttl 255, id 2092, offset 0, flags [DF], proto TCP (6), length 40)
ip-172-31-8-39.ec2.internal.27392 > ip-172-31-27-167.ec2.internal.jamlink: Flags [.], cksum 0x4842 (correct), seq 2, ack 2, win 53, length 0
当一端发起 close 请求时,就触发了终止流程, 因为 tcp 支持半关闭状态,即支持在一段要求关闭后,另一端仍然可以发送数据过来处理。
所以就需要四步来完成终止过程,我们称为链接终止。
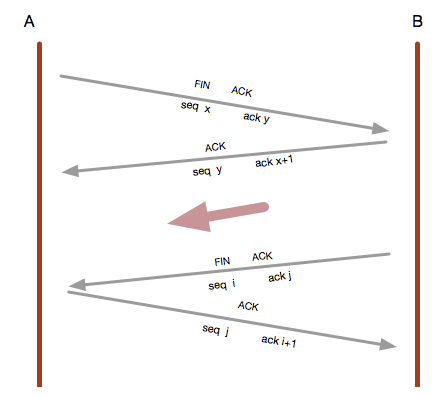
值得注意的是:
对于 FIN 的包, 虽然长度为0, 但是 确认包的确认序列号为对方序列号+1.
我们看一个半关闭的例子
1
2
3
4
5
6
ip-172-31-8-39.ec2.internal.15301 > ip-172-31-27-167.ec2.internal.jamlink: Flags [F.], cksum 0x01c1 (correct), seq 1, ack 1, win 53, length 0
ip-172-31-27-167.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.15301: Flags [.], cksum 0x7c27 (incorrect -> 0x01c1), seq 1, ack 2, win 53, length 0
ip-172-31-27-167.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.15301: Flags [P.], cksum 0x7c2b (incorrect -> 0x3cd6), seq 1:5, ack 2, win 53, length 4
ip-172-31-8-39.ec2.internal.15301 > ip-172-31-27-167.ec2.internal.jamlink: Flags [.], cksum 0x01bd (correct), seq 2, ack 5, win 53, length 0
ip-172-31-27-167.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.15301: Flags [F.], cksum 0x7c27 (incorrect -> 0x01bc), seq 5, ack 2, win 53, length 0
ip-172-31-8-39.ec2.internal.15301 > ip-172-31-27-167.ec2.internal.jamlink: Flags [.], cksum 0x01bc (correct), seq 2, ack 6, win 53, length 0
状态转换
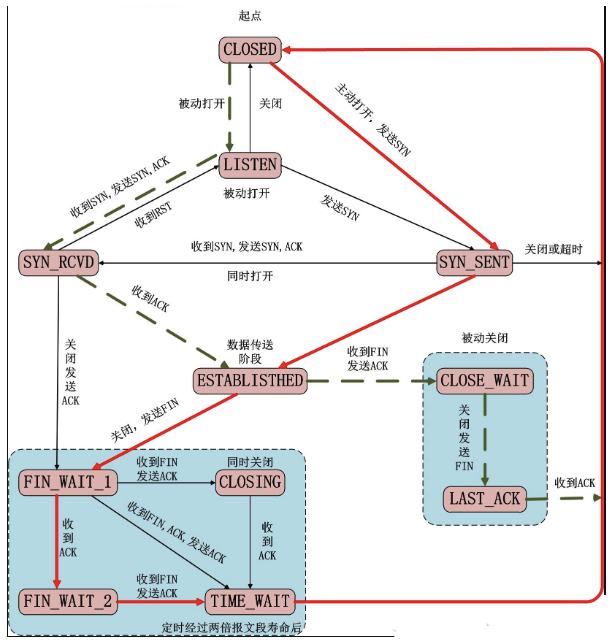
从LISTEN到SYN_SENT的变迁是正确的,但伯克利版的TCP软件并不支持它。
只有当SYN_RCVD状态是从LISTEN状态(正常情况)进入,而不是从SYN_SENT状态(同时打开)进入时,从SYN_RCVD回到LISTEN的状态变迁才是有效的。这意味着如果我们执行被动关闭(进入LISTEN),收到一个SYN,发送一个带ACK的SYN(进入SYN_RCVD),然后收到一个RST,而不是一个ACK,便又回到LISTEN状态并等待另一个连接请求的到来。
最常用的状态演变为
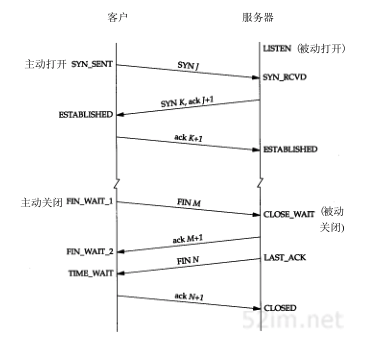
TIME_WAIT
TIME_WAIT状态也称为2MSL等待状态。每个具体TCP实现必须选择一个报文段最大生存时间MSL(Maximum Segment Lifetime)。它是任何报文段被丢弃前在网络内的最长时间。
RFC 793 [Postel 1981c]指出MSL为2分钟。然而,实现中的常用值是30秒,1分钟,或2分钟。
对一个具体实现所给定的MSL值,处理的原则是:当TCP执行一个主动关闭,并发回最后一个ACK,该连接必须在TIME_WAIT状态停留的时间为2倍的MSL。 这样可让TCP再次发送最后的ACK以防这个ACK丢失(另一端超时并重发最后的FIN)。
尽管许多具体的实现中允许一个进程重新使用仍处于2MSL等待的端口(通常是设置选项SO_REUSEADDR),但TCP不能允许一个新的连接建立在相同的socket上。
TCP 特性
超时与重传
TCP提供可靠的运输层。 它的实现方式之一就是确认从另一端收到的数据, 我们从上面的报文中例子中也可以看到, 对应每一个报文都有一个ack标志. 确认序号为下次对方发送报文的序列号。
对于一个确认序号为 n+1 的报文,它用来告诉主机,对方已经收到了前 n 字节的数据。

但数据和确认都有可能会丢失。TCP通过在发送时设置一个定时器来解决这种问题。如果当定时器溢出时还没有收到确认,它就重传该数据。
对任何实现而言,关键之处就在于超时和重传的策略,即怎样决定超时间隔和如何确定重传的频率。
一个超时重传的例子

从第6行我们可以看到, bsdi 主机发送了一个报文没有得到确认, 往后总共重传了12次。
现在检查连续重传之间不同的时间差,它们取整后分别为1、3、6、12、24、48和多个64秒。这个倍乘的等待关系被称为“指数退避(exponential backoff)”。
往返时间测量 RTT
解决的问题:
- 设长了,重发就慢,丢了老半天才重发,没有效率,性能差;
- 设短了,会导致可能并没有丢就重发。于是重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
TCP超时与重传中最重要的部分就是对一个给定连接的往返时间(RTT)的测量。由于路由器和网络流量均会变化,因此我们认为这个时间可能经常会发生变化,TCP应该跟踪这些变化并相应地改变其超时时间。
\[Err = M-A\] \[A = A+gErr\] \[D = D + h(|Err|-D)\] \[RTO = A+4D\]这里的A是被平滑的RTT(均值的估计器),而D则是被平滑的均值偏差. Err 是刚得到的测量结果与当前的RTT估计器之差。
A和D均被用于计算下一个重传时间(RTO)。
增量g起平均作用,取为1/8(0.125)。偏差的增益是h,取值为0.25。
当RTT变化时,较大的偏差增益将使RTO快速上升。
当定时器超时后还没有收到已发送报文的ack时候,将会重传改数据

延时确认
通常TCP在接收到数据时并不立即发送ACK
相反,它推迟发送,以便将ACK与需要沿该方向发送的数据一起发送(有时称这种现象为数据捎带ACK)。
绝大多数实现采用的时延为200 ms,也就是说,TCP将以最大200 ms的时延等待是否有数据一起发送。
滑动窗口
为了能够控制数据的发送速度,还有当数据发送超时时对数据做出重传的动作。
窗口大小单位为字节数, 这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。
发送方也参照发送窗口维护已经发送成功但是未被ack的数据,用来支持数据的丢失重传。
- 发送窗口
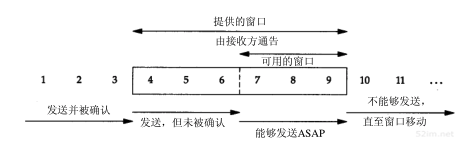
发送窗口由接收方提供的窗口大小定义,
- 接收窗口
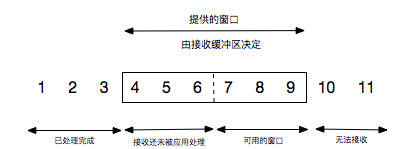
每一次报文发送时, 发送服务会将自己的接收窗口发送告知给数据接收方, 用来限制对方下次发送报文的大小, 依次来进行流量控制。
零窗口事件
当数据处理赶不上数据发送时, 就会触发零窗口事件。当出口大小变为0时,此时发送方将不再发送数据到接收方。
解决这个问题,TCP使用了Zero Window Probe技术,缩写为ZWP,也就是说,发送端在窗口变成0后,会发ZWP的包给接收方,让接收方来ack他的Window尺寸。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
08:50:47.474779 IP ip-172-31-8-39.ec2.internal.44266 > ip-172-31-40-158.ec2.internal.jamlink: Flags [P.], seq 1:12, ack 1, win 1500, length 11
08:50:47.474783 IP ip-172-31-40-158.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.44266: Flags [.], ack 12, win 1489, length 0
08:50:59.171532 IP ip-172-31-8-39.ec2.internal.44266 > ip-172-31-40-158.ec2.internal.jamlink: Flags [P.], seq 12:38, ack 1, win 1500, length 26
08:50:59.171537 IP ip-172-31-40-158.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.44266: Flags [.], ack 38, win 1463, length 0
08:51:11.220630 IP ip-172-31-8-39.ec2.internal.44266 > ip-172-31-40-158.ec2.internal.jamlink: Flags [P.], seq 38:431, ack 1, win 1500, length 393
08:51:11.220642 IP ip-172-31-40-158.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.44266: Flags [.], ack 431, win 1070, length 0
08:51:21.162774 IP ip-172-31-8-39.ec2.internal.44266 > ip-172-31-40-158.ec2.internal.jamlink: Flags [P.], seq 431:824, ack 1, win 1500, length 393
08:51:21.162790 IP ip-172-31-40-158.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.44266: Flags [.], ack 824, win 677, length 0
08:51:26.099710 IP ip-172-31-8-39.ec2.internal.44266 > ip-172-31-40-158.ec2.internal.jamlink: Flags [P.], seq 824:1217, ack 1, win 1500, length 393
08:51:26.099722 IP ip-172-31-40-158.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.44266: Flags [.], ack 1217, win 284, length 0
08:51:32.644612 IP ip-172-31-8-39.ec2.internal.44266 > ip-172-31-40-158.ec2.internal.jamlink: Flags [P.], seq 1217:1501, ack 1, win 1500, length 284
08:51:32.644618 IP ip-172-31-40-158.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.44266: Flags [.], ack 1501, win 0, length 0
08:51:32.848615 IP ip-172-31-8-39.ec2.internal.44266 > ip-172-31-40-158.ec2.internal.jamlink: Flags [.], ack 1, win 1500, length 0
08:51:32.848622 IP ip-172-31-40-158.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.44266: Flags [.], ack 1501, win 0, length 0
08:51:33.256576 IP ip-172-31-8-39.ec2.internal.44266 > ip-172-31-40-158.ec2.internal.jamlink: Flags [.], ack 1, win 1500, length 0
08:51:34.072608 IP ip-172-31-8-39.ec2.internal.44266 > ip-172-31-40-158.ec2.internal.jamlink: Flags [.], ack 1, win 1500, length 0
08:51:34.072614 IP ip-172-31-40-158.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.44266: Flags [.], ack 1501, win 0, length 0
08:51:35.708557 IP ip-172-31-8-39.ec2.internal.44266 > ip-172-31-40-158.ec2.internal.jamlink: Flags [.], ack 1, win 1500, length 0
08:51:35.708563 IP ip-172-31-40-158.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.44266: Flags [.], ack 1501, win 0, length 0
08:51:38.984569 IP ip-172-31-8-39.ec2.internal.44266 > ip-172-31-40-158.ec2.internal.jamlink: Flags [.], ack 1, win 1500, length 0
08:51:38.984577 IP ip-172-31-40-158.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.44266: Flags [.], ack 1501, win 0, length 0
08:51:45.528586 IP ip-172-31-8-39.ec2.internal.44266 > ip-172-31-40-158.ec2.internal.jamlink: Flags [.], ack 1, win 1500, length 0
08:51:45.528598 IP ip-172-31-40-158.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.44266: Flags [.], ack 1501, win 0, length 0
08:51:58.616585 IP ip-172-31-8-39.ec2.internal.44266 > ip-172-31-40-158.ec2.internal.jamlink: Flags [.], ack 1, win 1500, length 0
08:51:58.616590 IP ip-172-31-40-158.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.44266: Flags [.], ack 1501, win 0, length 0
08:52:24.760630 IP ip-172-31-8-39.ec2.internal.44266 > ip-172-31-40-158.ec2.internal.jamlink: Flags [.], ack 1, win 1500, length 0
08:52:24.760638 IP ip-172-31-40-158.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.44266: Flags [.], ack 1501, win 0, length 0
08:53:17.112668 IP ip-172-31-8-39.ec2.internal.44266 > ip-172-31-40-158.ec2.internal.jamlink: Flags [.], ack 1, win 1500, length 0
08:53:17.112675 IP ip-172-31-40-158.ec2.internal.jamlink > ip-172-31-8-39.ec2.internal.44266: Flags [.], ack 1501, win 0, length 0
注意 :
只要有等待的地方都可能出现DDoS攻击,Zero Window也不例外,一些攻击者会在和HTTP建好链发完GET请求后,就把Window设置为0,然后服务端就只能等待进行ZWP,于是攻击者会并发大量的这样的请求,把服务器端的资源耗尽。
拥塞处理
虽然发送方与接收方使用了窗口来进行流量控制,但是无法控制网络传输的问题,如果网络上的延时突然增加,那么,TCP对这个事做出的应对只有重传数据,但是,重传会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,于是,这个情况就会进入恶性循环被不断地放大。试想一下,如果一个网络内有成千上万的TCP连接都这么行事,那么马上就会形成“网络风暴”,TCP这个协议就会拖垮整个网络。
对此TCP的设计理念是:TCP不是一个自私的协议,当拥塞发生的时候,要做自我牺牲。就像交通阻塞一样,每个车都应该把路让出来,而不要再去抢路了。
拥塞控制主要是四个算法:1)慢启动,2)拥塞避免,3)拥塞发生,4)快速恢复。

慢启动
慢启动为发送方的TCP增加了另一个窗口:拥塞窗口(congestion window),记为cwnd。cwnd 的值为在收到对方ack时, 发送方最大能连续发送的报文段数量。
慢启动的算法如下(cwnd全称Congestion Window):
- 连接建好的开始先初始化 $cwnd=1$,表明可以传一个MSS大小的数据。
- 每当收到一个ACK,$cwnd++$; 呈线性上升
- 每当过了一个RTT,$cwnd = cwnd*2$; 呈指数让升
- 还有一个 ssthresh(slow start threshold),是一个上限,当 $cwnd >= ssthresh$ 时,就会进入“拥塞避免算法”(后面会说这个算法)
1
2
3
1. 最开始cwnd=1,发送方只发送一个mss大小的数据包,在一个rtt后,会收到一个ack,cwnd加一,cwnd=2
2.此时cwnd=2,则发送方要发送两个mss大小的数据包,发送方会收到两个ack,则cwnd会进行两次加一的操作,则也就是cwnd+2,则cwnd=4,也就是cwnd = cwnd * 2
3.此时cwnd=4,则发送方要发送四个mss大小的数据包,发送方会收到四个ack,则cwnd会加4,则 cwnd = 8,也就是cwnd = cwnd * 2.
拥塞避免算法
从慢启动可以看到,cwnd可以比较快的增长,但是不能一直无限增长,需要某个限制,TCP使用了 ssthresh 的变量,当cwnd超过这个值后,慢启动过程结束,进入拥塞避免阶段。 拥塞避免的主要思想是让cwnd的值线性增加,此时当窗口中所有的报文段都被确认是,cwnd的大小才加1. cwnd的值随着RTT线性增加,这样就可以避免增长过快导致网络拥塞,慢慢的增加到网络的最佳值。
如下算法:
- 收到一个ACK时: $cwnd = cwnd + 1/cwnd$
- 当每过一个RTT时: $cwnd = cwnd + 1$
拥塞发生
当网络中出现拥塞状况时, 会出现丢包的现象, 会有两种情况:
等到RTO超时,重传数据包。TCP认为这种情况太糟糕,反应也很强烈。
- $sshthresh=cwnd /2$
- $cwnd=1$
- 进入慢启动过程
Fast Retransmit算法,也就是在收到3个duplicate ACK时就开启重传,而不用等到RTO超时。
- TCP Tahoe 的实现和RTO超时一样。
- TCP Reno的实现是
- $cwnd = cwnd/2$
- $sshthresh=cwnd$
- 进入快速恢复算法——Fast Recovery
快速恢复算法
当sender这边收到了3个Duplicated Acks,进入Fast Retransimit模式,开发重传重复Acks指示的那个包。如果只有这一个包丢了,那么,重传这个包后回来的Ack会把整个已经被sender传输出去的数据ack回来。如果没有的话,说明有多个包丢了。我们叫这个ACK为Partial ACK。
一旦Sender这边发现了Partial ACK出现,那么,sender就可以推理出来有多个包被丢了,于是乎继续重传sliding window里未被ack的第一个包。直到再也收不到了Partial Ack,才真正结束Fast Recovery这个过程
参考内容: