CRC校验算法

背景

CRC即循环冗余校验码:是数据通信领域中最常用的一种查错校验码,其特征是信息字段和校验字段的长度可以任意选定。
循环冗余检查(CRC)是一种数据传输检错功能,对数据进行多项式计算,并将得到的结果附在帧的后面,接收设备也执行类似的算法,以保证数据传输的正确性和完整性。
其根本思想就是先在要发送的数据字节流后面附加几个校验位,生成一个新的字节流发送给接收端。
校验位的生成是通过一个 模二除法 计算得到的。
数据到达接收端后,再把接收到的数据流(原数据+校验码)同样进行模二除法。这时结果应该是没有余数。如果有余数,则表明该帧在传输过程中出现了差错, 由此实现了数据校验。
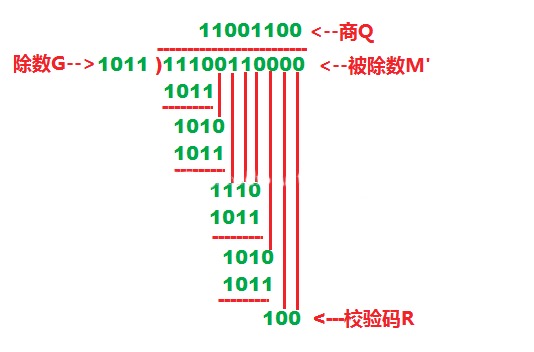
校验码计算方式
- 对于任意需要添加校验的字节流,我们人为选择一个合适的二进制
除数G - 假设
除数G有k位, 则将需要校验的字节流后面补(k-1)位0作为被除数M - 将
被除数M与除数G进行模二除法(模2除法与算术除法类似,但每一位除的结果不影响其它位,即不向上一位借位,所以实际上就是异或) - 将模二除法得到
(k-1)位余数 (不足(k-1)位高位用0不足)便是校验字节流的CRC冗余码。
CRC多项式(除数)
CRC 多项式是除数的一种表达形式:
对于 $G(x)=x^{4}+x^{3}+1$ 的形式,其标识除数为11001
CRC多项式的设计要考虑很多因素,如选择的多项式必须有最大的错误检测能力,同时保证总体的碰撞概率最小等,这里就不再多讲述,可参考下面的链接。

CRC 实现方式
一般来说CRC有多种实现方式,主要列举有 直接生成法 和 查表法 两种。
直接生成法 适用于CRC次幂较小的格式,当CRC次幂逐渐增高时,因为其复杂的 Xor 逻辑运算会拖累系统运行速度,不再建议使用直接生成法,取而代之的是查表法。
查表法是将数据块M的一部分提前运算好,并将结果存入数组中,系统开始执行运算时,相当于省去了之前的操作,直接从类似中间的位置开始计算,所以会提高效率。
在计算CRC时也可以选择 正向校验(Normal) 或者 反向校验(Reversed),由于 Normal 和 Reversed 是镜像关系,两种方法会影响到最后的校验码,使得两种方式最后得到的校验码呈现镜像关系。
但这对CRC 本身的成功率并没有影响,只不过是: 正向走一遍,还是镜像走一遍罢了。
那为什么还会有 Reversed 格式呢? 是因为在大多数硬件系统的传输中,普遍先发送LSB,而Reversed 的CRC 正是满足于这种 LSB First 的格式,因此适用。
直接生成法
多项式 : $x^{8}+x^{5}+x^{4}+x^{0}$ (1 0011 0001)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
uint8_t crc8(const char* data, uint32_t size){
uint8_t crc_val = 0;
uint8_t poly = 0x31 ; // 忽略最高位,减少计算, 但是要求被计算的最高位为1
for(int i = 0 ; i < size ; i++){
const uint8_t temp_val = static_cast<uint8_t>(data[i]);
crc_val ^= temp_val;
for (int j =0; j < 8; j++){
uint8_t flag = crc_val & 0x80;
if(flag){
crc_val <<= 1;
crc_val ^= poly;
} else{
crc_val <<= 1;
}
}
}
return crc_val;
}
查表法 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
const char CRC8Table[]={
0, 94, 188, 226, 97, 63, 221, 131, 194, 156, 126, 32, 163, 253, 31, 65,
157, 195, 33, 127, 252, 162, 64, 30, 95, 1, 227, 189, 62, 96, 130, 220,
35, 125, 159, 193, 66, 28, 254, 160, 225, 191, 93, 3, 128, 222, 60, 98,
190, 224, 2, 92, 223, 129, 99, 61, 124, 34, 192, 158, 29, 67, 161, 255,
70, 24, 250, 164, 39, 121, 155, 197, 132, 218, 56, 102, 229, 187, 89, 7,
219, 133, 103, 57, 186, 228, 6, 88, 25, 71, 165, 251, 120, 38, 196, 154,
101, 59, 217, 135, 4, 90, 184, 230, 167, 249, 27, 69, 198, 152, 122, 36,
248, 166, 68, 26, 153, 199, 37, 123, 58, 100, 134, 216, 91, 5, 231, 185,
140, 210, 48, 110, 237, 179, 81, 15, 78, 16, 242, 172, 47, 113, 147, 205,
17, 79, 173, 243, 112, 46, 204, 146, 211, 141, 111, 49, 178, 236, 14, 80,
175, 241, 19, 77, 206, 144, 114, 44, 109, 51, 209, 143, 12, 82, 176, 238,
50, 108, 142, 208, 83, 13, 239, 177, 240, 174, 76, 18, 145, 207, 45, 115,
202, 148, 118, 40, 171, 245, 23, 73, 8, 86, 180, 234, 105, 55, 213, 139,
87, 9, 235, 181, 54, 104, 138, 212, 149, 203, 41, 119, 244, 170, 72, 22,
233, 183, 85, 11, 136, 214, 52, 106, 43, 117, 151, 201, 74, 20, 246, 168,
116, 42, 200, 150, 21, 75, 169, 247, 182, 232, 10, 84, 215, 137, 107, 53
};
上面这个庞大的数组是根据,CRC8的多项式 $X^8+X^5+X^4+X^0$ 计算出来的,但该数组到底是如何被计算出来的?如果以后想换一个多项式时要怎么办?这就需要我们理解CRC表的计算原理了。
以表的下标为 0x01 作为示例来进行计算:
首先需要明确CRC8常见的表格数据中是按照线传输 LSB,并通过右移寄存器来判断的,因此每次要判断的就是寄存器的最低位LSB。同时要将多项式 $X^8+X^5+X^4+X^0$ (也就是0x131 (0011 0001))按位颠倒后得到 0x8c(1000 1100),在计算过程中做异或运算(为什么0x131中第一个1没有被颠倒?答:因为它是隐藏的)。
具体计算步骤如下 :
- 选择范围
0~255(包含255)范围内的数据,设为temp; - 判断
temp的最低位是否为 1,如果为 1,先将temp右移一位,然后将temp和多项式(0x8c)进行异或运算,结果保存在temp中。如果最低位为0,则将temp右移一位; - 重复第二步,直到
temp中的 8 位数据全部从右移出,然后进入 4 步; - 此时 temp 的值就是 CRC8 校验值。

则由此可知 0x01 使用 CRC8 的反向计算逻辑为 : 94(D), 以此类推,我们可以直接将结果保存到一个表中,减少计算过程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
static uint8_t invert_uint8(uint8_t var)
{
uint8_t tmp = 0;
for (uint8_t i = 0; i < 8; i++){
if (var & (1 << i)){
tmp |= 1 << (7-i);
}
}
return tmp;
}
uint8_t crc8_table(const char* data, uint32_t size){
uint8_t crc_val = 0;
for(int i = 0 ; i < size ; i++){
const uint8_t temp_val = invert_uint8(static_cast<uint8_t>(data[i]));
crc_val = CRC8Table[crc_val^temp_val];
}
return invert_uint8(crc_val);
}