Leveldb 教程 | Leveldb MVCC实现细节

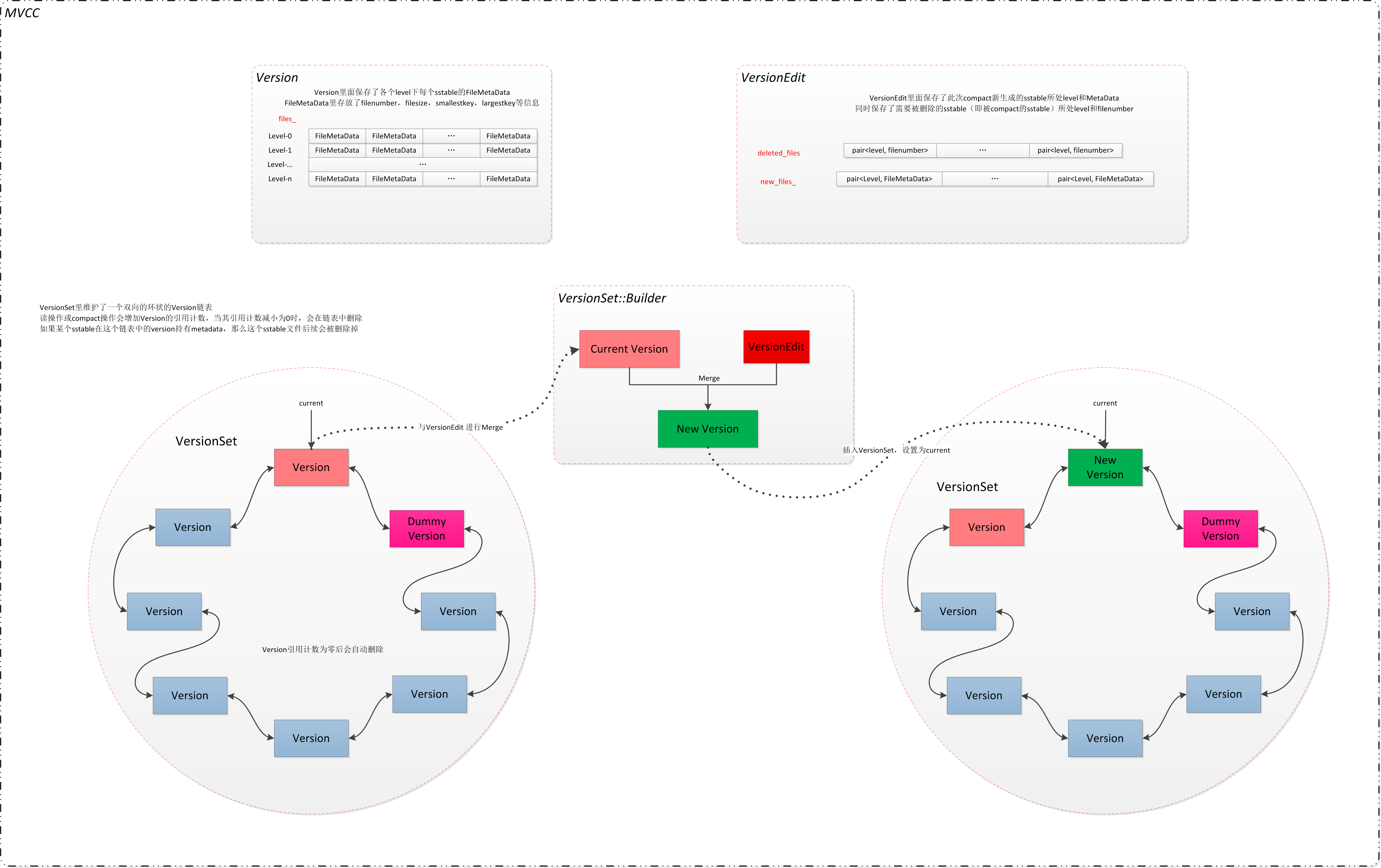
leveldb 使用VersionSet来维护SST的变更记录,SST的变更主要发生在Compaction环节,分为Minor compaction与Major compaction。
Minor compaction发生在MemTable数据容量超过限制溢出到SST。 Manor compaction发生在sst达到了触发合并条件,数据写出到下一层level.
VersionSet 里面维护有一个Version双向链表。 来记录每一个版本中的有效SST. 当SST发生变更时,会构造一个VersionEdit来维护SST变更记录。
在逻辑上来说 : New Version = Current Version + VersinEdit
数据结构
Version数据结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
VersionSet* vset_; // 表示这个 verset 隶属于哪一个 verset_set, 在 leveldb 中只有一个 versetset
// 历史版本的双向链表
Version* next_; // Next version in linked list
Version* prev_; // Previous version in linked list
int refs_; // 有多少服务还引用这个版本
/***
* 当前版本的所有数据 -- 二级指针结构
* 第一层代表每一个 level 级别
* 第二层代表同一个 level 级别下面的 sst 文件number
*/
std::vector<FileMetaData*> files_[config::kNumLevels];
// 用于压缩的标记
// 压缩触发条件 1 : 基于文件 seek 的压缩方式
FileMetaData* file_to_compact_; // 用于 seek 次数超过阈值之后需要压缩的文件
int file_to_compact_level_; // 用于 seek 次数超过阈值之后需要压缩的文件所在的level
// 压缩触发条件 2 : 基于文件大小超过阈值的压缩方式
double compaction_score_; // 用于检查 size 超过阈值之后需要压缩的文件
int compaction_level_; // 用于检查 size 查过阈值之后需要压缩的文件所在的 level
主要包含:
- 版本的维护链表
- 当前有效的SST
- compaction条件
VersionEdit数据结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
typedef std::set<std::pair<int, uint64_t>> DeletedFileSet;
std::string comparator_; // 比较器名字
uint64_t log_number_; // 日志编号, 该日志之前的数据均可删除
uint64_t prev_log_number_; // 已经弃用
uint64_t next_file_number_; // 下一个文件编号(ldb, idb, MANIFEST文件共享一个序号空间)
SequenceNumber last_sequence_; // 最后的 Seq_num
bool has_comparator_; //
bool has_log_number_;
bool has_prev_log_number_;
bool has_next_file_number_;
bool has_last_sequence_;
std::vector<std::pair<int, InternalKey>> compact_pointers_; // 存储在本次执行的压缩操作对应的level与压缩的最大的key
DeletedFileSet deleted_files_; // 相比上次 version 而言, 本次需要删除的文件有哪些
std::vector<std::pair<int, FileMetaData>> new_files_; // 相比于上次 version 而言, 本次新增文件有哪些
主要包含 :
- 当前新增的SST集合
- 当前删除的SST集合
- 最新的key SequenceNumber
- 记录每个level当前合并的key位置
Minor Compaction
Minor Compaction 主要发生在MemTable使用达到阈值后,需要将MemTable内容写出到磁盘形成SST.
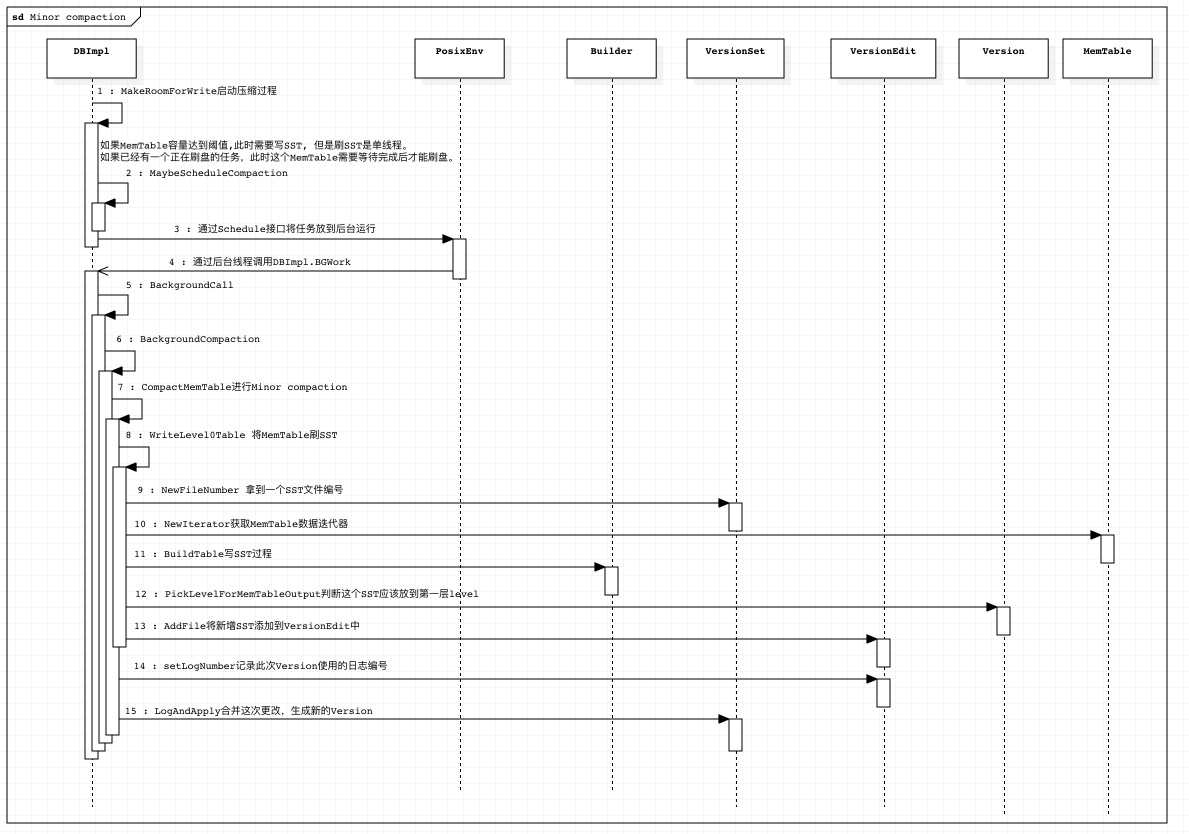
Minor compation的触发流程位于CompactMemTable方法中, 他会首先创建一个VersionEdit 用于记录后续的变更事件。
然后在WriteLevel0Table中进行数据落盘操作。 数据的落盘流程请参考MemTable数据刷盘流程。
数据形成SST后,会进行一个level的判断,尽量将sst推到更高的level中去。
规则如下 :
- 如果落地的SST的key的范围与
level-0层SST范围有重叠, 则数据落地到level-0层(防止新旧数据版本查询不一致) - 如果跟
level+1层数据有重叠,则数据放弃向level+1层落地(因为不能发生merge操作), 最终落地到level层 - 如果跟
level+2层重叠的所有SST总文件大小超过20M(防止后期merge代价太大), 则数据放弃向level+1层落地,最终落地到level层 - level不能超过 2
通过此规则,计算出改SST合适的level. 将记录写入到VersionEdit中
数据落地完成以后,将WAL文件编号记录到VersionEdit中,然后Version合并VersionEdit形成一个新的Version。
Major Compaction
Major Compaction的主要方式:
- SST在落地或者合并过程中level层文件超过阈值
- 某个SST文件多次查询过程中没有找到目标key
- 手动compaction
基于文件大小的压缩阈值判断方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
void VersionSet::Finalize(Version* v) {
int best_level = -1;
double best_score = -1;
// 从level-0到level-(max-1)层进行遍历
for (int level = 0; level < config::kNumLevels - 1; level++) {
double score;
if (level == 0) {
// 我们通过限制文件数量而不是字节数量来特别处理 level==0,原因有两个:
// 1) 对于较大的写缓冲区大小,最好不要进行太多的level=0级压缩。
// 2) level==0 的文件在每次读取时都会合并,因此我们希望避免在单个文件大小较小时出现过多的文件(可能是因为写入缓冲区设置较小,或压缩比非常高,或大量的覆盖/删除)。
// config::kL0_CompactionTrigger == 4
score = v->files_[level].size() / static_cast<double>(config::kL0_CompactionTrigger);
} else {
// level > 1 层 通过数据量来判断 level_bytes / (1M * 10^level)
const uint64_t level_bytes = TotalFileSize(v->files_[level]);
score =static_cast<double>(level_bytes) / MaxBytesForLevel(options_, level);
}
// 找到一个最需要进行合并的层
if (score > best_score) {
best_level = level;
best_score = score;
}
}
v->compaction_level_ = best_level;
v->compaction_score_ = best_score;
}
每次合并形成新的版本以后,需要进行文件量的判断,寻找超过文件量阈值的level,进行压缩。 判断的依据是: current_->compaction_score_ >= 1:
- level0是基于文件数量的,文件数量超过
4(config::kL0_CompactionTrigger)则达到压缩的阈值。 - level>=1是基于level下所有SST总的文件大小的。 文件大小超过($10M^{Level}$)则达到压缩的阈值。
通过此判断最需要压缩的SST进行压缩。
基于文件seek的压缩阈值判断方式
每个SST在刚创建时候会初始化一个seek的值,每当用户提交一个查询请求过来首次定位到SST(通过sst filemeata中key的范围)但是没有查询到目标数据时,会在这个filemeta中递减一个seek.
当文件的seek递减到小于等于0,后表示这个seek需要被合并。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
// version_set.cc
// 这里将特定数量的seek之后自动进行compact操作,假如 :
// 1. 一次 seek 需要 10ms
// 2. 读,写1MB文件消耗 10ms(100MB/s)
// 3. 对1MB文件的compact操作时合计一共做了25MB的IO操作,包括 :
// 从这个level读1MB
// 从下个level读10-12MB
// 向下一个level写10-12MB
// 这一位这25次seek消耗与1MB数据的compact相当。也就是,
// 一次 seek 的消耗与40KB数据的compact消耗近似。这里做一个保守估计,在一次compact之前每16kB的数据大约进行1次seek.
// allow_seeks 数目和文件数量有关
f->allowed_seeks = static_cast<int>((f->file_size / 16384U));
if (f->allowed_seeks < 100) f->allowed_seeks = 100;
static bool Match(void* arg, int level, FileMetaData* f) {
State* state = reinterpret_cast<State*>(arg);
// 在state中记录第一次查找数据但是查找失败的SST
if (state->stats->seek_file == nullptr &&
state->last_file_read != nullptr) {
// 标志第一次用于查找,但是没有找到数据的SST,一般位于第0层
// 也可能不位于第0层
state->stats->seek_file = state->last_file_read;
state->stats->seek_file_level = state->last_file_read_level;
}
state->last_file_read = f; // 将 last_file_read 信息定位到最后一次用于匹配的SST中
state->last_file_read_level = level;
// 从 sst 中查找对应的 internalkey
// table_cache_ 中只返回 >= user_key 的第一个 key ,
// 但是因为 sst 从小大大有序, 所以如果这个不是要寻找的数据, 则此 key 不在数据范围内
state->s = state->vset->table_cache_ ->Get(*state->options, f->number,f->file_size, state->ikey, &state->saver, SaveValue);
if (!state->s.ok()) {
state->found = true;
return false;
}
switch (state->saver.state) {
case kNotFound:
return true; // Keep searching in other files
case kFound:
state->found = true;
return false;
case kDeleted:
return false;
case kCorrupt:
state->s =Status::Corruption("corrupted key for ", state->saver.user_key);
state->found = true;
return false;
}
// Not reached. Added to avoid false compilation warnings of
// "control reaches end of non-void function".
return false;
}
bool Version::UpdateStats(const GetStats& stats) {
FileMetaData* f = stats.seek_file;
if (f != nullptr) {
f->allowed_seeks--;
// 表示如果allowed_seeks <= 0, 则seek数量超过指定阈值,需要被合并
if (f->allowed_seeks <= 0 && file_to_compact_ == nullptr) {
file_to_compact_ = f;
file_to_compact_level_ = stats.seek_file_level;
return true;
}
}
return false;
}
压缩过程
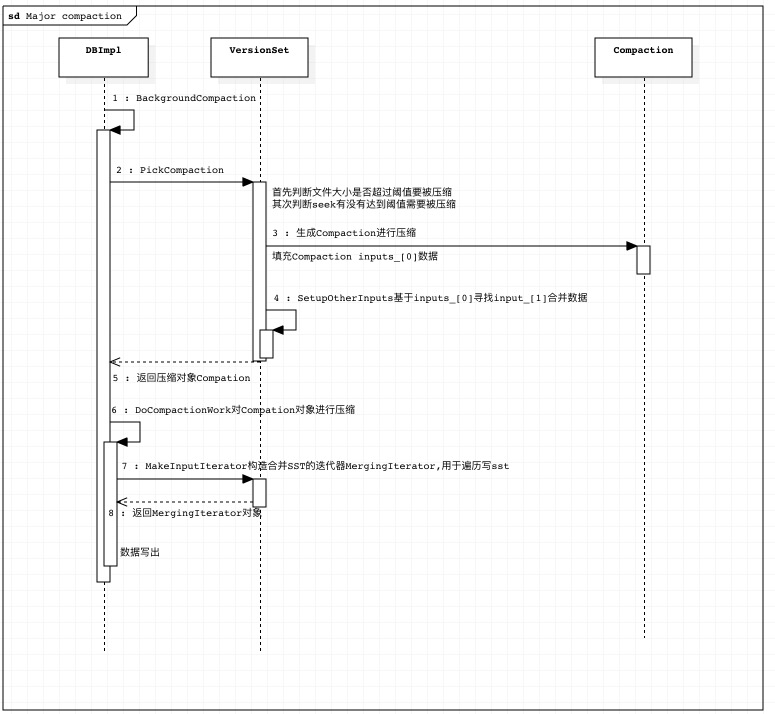
Compaction构造 PickCompaction
PickCompaction会基于压缩阈值来构造Compaction。 在这里有一个先后顺序:
- 首先判断level层文件是否超出阈值有需要压缩。
- 其次判断seek有无超过阈值需要压缩。
这里每次只能进行一种压缩。
这里会将待压缩文件放入Compaction::inputs_[0]中,这里触发压缩的只会添加一个文件进来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
// 如果时文件大小超过了阈值需要合并
// 优先基于大小进行压缩,只选择一个文件
// size 触发的 compaction 稍微复杂一点, 他需要上一次 compaction 做到了哪一个 key, 什么地方,然后大于改key
// 的第一个文件即为 level n 的所选文件
if (size_compaction) {
level = current_->compaction_level_; // 设置需要合并的 level 层
assert(level >= 0);
assert(level + 1 < config::kNumLevels);
c = new Compaction(options_, level);
// 遍历当前level层的所有sst文件
for (size_t i = 0; i < current_->files_[level].size(); i++) {
FileMetaData* f = current_->files_[level][i];
// 基于上次 level 的压缩位置, 然后标识本次从哪里开始压缩
if (compact_pointer_[level].empty() || icmp_.Compare(f->largest.Encode(), compact_pointer_[level]) > 0) {
c->inputs_[0].push_back(f);
break;
}
}
if (c->inputs_[0].empty()) {
// 标识上次如果压缩到最后了, 在从最开始压缩
c->inputs_[0].push_back(current_->files_[level][0]);
}
} else if (seek_compaction) {
level = current_->file_to_compact_level_;
c = new Compaction(options_, level);
c->inputs_[0].push_back(current_->file_to_compact_); // 直接压入 seek 对应的文件
} else {
return nullptr;
}
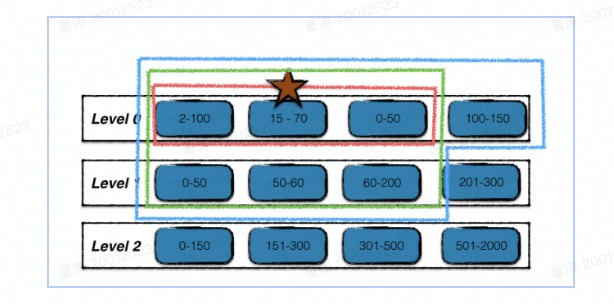
需要注意的是,如果是要合并的这个sst是level0层sst。需要考虑到同层重叠sst问题,进一步扩大inputs_[0]层sst, 将重叠sst合并进来(上图红色部分)。
1
2
3
4
5
6
7
8
9
10
// 因为 level == 0数据存在重叠, 如果指定的数据被合并到下一层,
// 那么有可能 level==0中, 版本比合并的sst老的数据会优先查询到
// 所以在选择压缩的时候,先基于对应的 sst , 并且找到这个 sst 的上下限
// 基于重叠的数据, 找到所有重叠的 sst 放入到 inputs_[0] 中一起合并
if (level == 0) {
InternalKey smallest, largest;
GetRange(c->inputs_[0], &smallest, &largest);
current_->GetOverlappingInputs(0, &smallest, &largest, &c->inputs_[0]);
assert(!c->inputs_[0].empty());
}
这里还有一个同一个user_key跨sst的问题, 因为在判断重叠是是基于InternalKey的范围来判断的,但是同一个user_key跨了两个sst.从逻辑上看是没有重叠, 但是如果只将sst1进行合并,那么在后续查询中,会优先查到sst2。造成了数据错误, 所以需要解决这个问题。
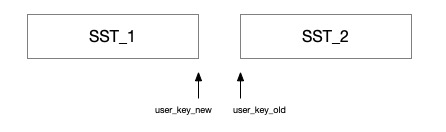
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
void AddBoundaryInputs(const InternalKeyComparator& icmp,
const std::vector<FileMetaData*>& level_files,
std::vector<FileMetaData*>* compaction_files) {
InternalKey largest_key;
// 找到要压缩的 sst 的最大的 user_key
if (!FindLargestKey(icmp, *compaction_files, &largest_key)) {
return;
}
// 对于同一个user_key跨越sst的问题需要扩充
bool continue_searching = true;
while (continue_searching) {
FileMetaData* smallest_boundary_file = FindSmallestBoundaryFile(icmp, level_files, largest_key);
// If a boundary file was found advance largest_key, otherwise we're done.
if (smallest_boundary_file != NULL) {
compaction_files->push_back(smallest_boundary_file); // 需要扩充要压缩的文件
largest_key = smallest_boundary_file->largest;
} else {
continue_searching = false;
}
}
}
FileMetaData* FindSmallestBoundaryFile(const InternalKeyComparator& icmp,
const std::vector<FileMetaData*>& level_files,
const InternalKey& largest_key) {
const Comparator* user_cmp = icmp.user_comparator();
FileMetaData* smallest_boundary_file = nullptr;
// 遍历所有的sst 文件
for (size_t i = 0; i < level_files.size(); ++i) {
FileMetaData* f = level_files[i];
// 意思就是说 f->smallest 跟 largest_key 是相同的 user_key
// 仅仅是 largest_key 版本比 f->smallest 版本大
if (icmp.Compare(f->smallest, largest_key) > 0 && user_cmp->Compare(f->smallest.user_key(), largest_key.user_key()) ==0) {
// 记录一个版本最小的
if (smallest_boundary_file == nullptr || icmp.Compare(f->smallest, smallest_boundary_file->smallest) < 0) {
smallest_boundary_file = f;
}
}
}
return smallest_boundary_file;
}
添加完需要合并的inputs_[0]文件之后,需要从level+1层找到覆盖文件一起参与合并。
1
2
3
GetRange(c->inputs_[0], &smallest, &largest);
current_->GetOverlappingInputs(level + 1, &smallest, &largest,&c->inputs_[1]);
AddBoundaryInputs(icmp_, current_->files_[level + 1], &c->inputs_[1]);
到这里需要合并的level层与level+1层基本完成,但leveldb在这里又做了一层优化,在不改变level+1层sst的现状情况下,尽量扩展level层的sst.如上的蓝色部分。这样保证在一次压缩过程中,争取压缩更多的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
// inputs_1 非空情况下(空可能是因为这个sst与level+2层重叠的文件超过2M)
if (!c->inputs_[1].empty()) {
std::vector<FileMetaData*> expanded0;
// 基于level层与level+1层的所有合并的sst的user_key的上下限
// 重新查找level层的sst,想将更多的sst加入到合并列中
current_->GetOverlappingInputs(level, &all_start, &all_limit, &expanded0);
AddBoundaryInputs(icmp_, current_->files_[level], &expanded0);
const int64_t inputs0_size = TotalFileSize(c->inputs_[0]); // 拿到level层合并的sst的文件量
const int64_t inputs1_size = TotalFileSize(c->inputs_[1]); // 拿到level+1层合并的sst的文件量
const int64_t expanded0_size = TotalFileSize(expanded0); // 拿到level层的扩展sst的文件大小
if (expanded0.size() > c->inputs_[0].size() // 表示扩展sst是压缩的level层sst的超集
&& inputs1_size + expanded0_size < ExpandedCompactionByteSizeLimit(options_)) { // level1+level0扩展的合并数据量少于 50M
InternalKey new_start, new_limit;
// 获取扩展后的sst的user_key的上下限
GetRange(expanded0, &new_start, &new_limit);
// 重新定位涉及到的level+1层的sst
std::vector<FileMetaData*> expanded1;
current_->GetOverlappingInputs(level + 1, &new_start, &new_limit, &expanded1);
AddBoundaryInputs(icmp_, current_->files_[level + 1], &expanded1);
// 表示扩展的 user_key 并不会改变 level+1层的要合并的sst的数量
if (expanded1.size() == c->inputs_[1].size()) {
Log(options_->info_log,
"Expanding@%d %d+%d (%ld+%ld bytes) to %d+%d (%ld+%ld bytes)\n",
level, int(c->inputs_[0].size()), int(c->inputs_[1].size()),
long(inputs0_size), long(inputs1_size), int(expanded0.size()),
int(expanded1.size()), long(expanded0_size), long(inputs1_size));
smallest = new_start;
largest = new_limit;
c->inputs_[0] = expanded0; // 加入扩展
c->inputs_[1] = expanded1;
GetRange2(c->inputs_[0], c->inputs_[1], &all_start, &all_limit);
}
}
}
如上逻辑,构造完需要合并的level层sst与level+1层sst.
level层sst对应inputs_[0], level+1层sst对应inputs_[1]封装成我们需要的Compaction。
数据Compaction
在compaction对象构造完成以后,接下来需要将待压缩数据合并形成新的sst。
如果在Compaction里面待压缩对象只在inputs_[0]且只有一个sst,表示level+1层没有覆盖的sst. 则考虑直接将此sst移动到level+1层。
1
2
3
4
5
6
7
8
FileMetaData* f = c->input(0, 0); // 拿到文件
// 将SST从level层直接移动到level+1层
c->edit()->RemoveFile(c->level(), f->number);
c->edit()->AddFile(c->level() + 1, f->number, f->file_size, f->smallest, f->largest);
// 更新一个版本
status = versions_->LogAndApply(c->edit(), &mutex_);
如果存在多个待压缩的sst. 则调用DoCompactionWork启动压缩。
这里对应多个sst会产生一个MergingIterator用来基于key顺序同时迭代多个sst.
然后启动迭代写sst过程。
需要注意的是:
- 合并过程中每一个
user_key会保留有效版本 - 写的过程中新的sst如果超过2M,则关闭重新开一个新的sst.
- 写的过程中如果与
level+2层重叠超过20M则关闭重新开一个新的sst.
剩余部分则与MemTable刷sst过程大致相同。