Leveldb 教程 | SSTable 文件格式

前言
leveldb 将持久化的数据分成若干个sst文件来保存, sst 分成若干层,最高到第7层[0,1,2,3,4,5,6]
sst文件名格式为 {file_number}.ldb,

如上所示, leveldb定期将内存中存满的数据落地到磁盘形成SST
- 因为level0层SST是从MemTable中dump下来的,所以SST之间数据可能存在重叠,但是它也有新旧之分,sst文件编码越大,代表sst被刷盘的时间越新。
- 其他level层同层的sst之间数据是不会重叠的切有序排列,形如 :
[0-49], [50-70], [71-100] - 对于指定的
key进行查询时,需要从最低的level往上查询, 因为对于指定的key来说,他所在sst的level越大,表示数据越旧。
leveldb 中的每个sst主要有一下功能:
- 数据体 : 包含多个 key->value 的数据集合, sst 中的数据是按照 key, 由 小到大进行排序。
- 数据校验: 使用
crc校验数据完整性 - BloomFilter : 用来快速判断对于要查询的 key 是否在这个 sst 中
- 数据索引: 对于要查询的key, 如果存在本 sst 中,则使用数据索引快速定位
组成部分
SST 主要由 5 部分组成 :
- data_block : 内部存储多个 key, value 的数据实体
- filter_block : 存储
BloomFilter内容部分 - meta_index_block : 存储
filter_block索引 - index_block : 存储
data_block的索引 - footer : 存储
index_block,meta_index_block的索引
1
2
3
4
5
6
7
8
9
10
11
12
13
/*****
* table_format :
* <beginning_of_file>
* [data block 1]
* [data block 2]
* ...
* [data block n]
* [filter block]
* [metaindex block]
* [index block]
* [Footer] (fixed size; starts at file_size - sizeof(Footer))
* <end_of_file>
*/

DataBlock
DataBlock 用来存储数据实体, 一个 SST 中可能会存在一到多个 DataBlock。
每个 DataBlock 中的数据按照 key 有序排序。
DataBlock 的数据格式如下:
1
2
3
4
5
6
7
8
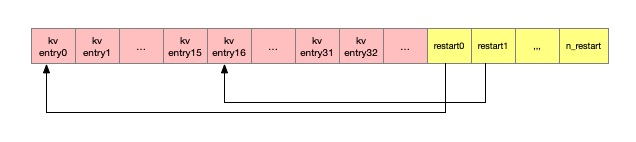
| shared_length(Varint32) | unshared_length(Varint32) | value_length(Varint32) | delta_key(string) | value(string) |
| shared_length(Varint32) | unshared_length(Varint32) | value_length(Varint32) | delta_key(string) | value(string) |
。。。。
| shared_length(Varint32) | unshared_length(Varint32) | value_length(Varint32) | delta_key(string) | value(string) |
| restarts_[0](Fixed32) | restarts_[1](Fixed32) | restarts_[2](Fixed32) | ... | restarts_[k](Fixed32) |
| restarts_size(Fixed32) |
为了减少数据存储,每个Key-Value在 SST 中并不是独立存储,而是引入了共享key的概念。
每一个 Key-Value 存储格式为 :

shared_length: 共享key长度unshared_length: 非共享 key 长度value_length: value 长度delta_key: 非共享 key内容value: value 内容
每一个 Key-Value 的获取需要首先知道上一个 key 的值, 然后基于 shared_length, unshared_length, delta_key 三个字段便可以求出这个 key.
同一个datablock中,每隔一部分需要重置共享Key(shared_length := 0), 这个值(多少个key重置重启点)收到 Options.block_restart_interval 控制, 默认16个key. 每当发生重置时,下一个数据存储delta_key是完整的key数据, 此时数据结构如下 :
1
2
3
4
5
shared_length := 0
unshared_length := len(key)
value_length := len(value)
delta_key := key
value := value
一个 datablock 中具有 restart_number 个重置点, 每个重置点的位置位于restart_[]数组中。
这样设计的作用
- 数据压缩: 基于共享key的方式,可以减少多数key的数据存储空间,实现数据压缩。
- 高效查询: 重启点的存在是为了提高查询效率, 重启点的位置是完整的key, 这样基于重启点的二分查找,首先能粗略定位到key的大致位置,然后在从重启点位置遍历,依次找到key的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
/***
* buffer : 保存要写入到磁盘的序列化字节流
* restarts_ : 保存位于 buffer 的每个重置点的偏移位置
*/
void BlockBuilder::Add(const Slice& key, const Slice& value) {
Slice last_key_piece(last_key_); // 得到上次的key
assert(!finished_);
assert(counter_ <= options_->block_restart_interval);
assert(buffer_.empty() // No value
|| options_->comparator->Compare(key, last_key_piece) > 0);
size_t shared = 0;
// block_restart_interval 控制着重启点之间的距离
if (counter_ < options_->block_restart_interval) {
// 记录相同 key 的位置
const size_t min_length = std::min(last_key_piece.size(), key.size());
while ((shared < min_length) && (last_key_piece[shared] == key[shared])) {
shared++;
}
} else {
// Restart compression
// 重启过程中 key 相当于置空 -> share=0
restarts_.push_back(buffer_.size()); // 记录重启点的 buffer 偏移
counter_ = 0;
}
const size_t non_shared = key.size() - shared; // 非共享 key 的长度
// 存储数据长度
PutVarint32(&buffer_, shared); // 写入共享 key 长度 -- 变长 32 位
PutVarint32(&buffer_, non_shared); // 写入非共享 key 长度 -- 变长 32 位
PutVarint32(&buffer_, value.size()); // 写入 value 长度 -- 变长 32 位
// 存储真实数据
buffer_.append(key.data() + shared, non_shared); // 非共享 key 部分的存储
buffer_.append(value.data(), value.size()); // 数据存储
// 更新 last_key 表示为 上次插入的key
last_key_.resize(shared);
last_key_.append(key.data() + shared, non_shared);
assert(Slice(last_key_) == key);
counter_++; // 计数加一
}
当数据写入完成后,会在将所有重启点位置与重启点的数量填充到最后,形成 DataBlock
1
2
3
4
5
6
7
8
9
Slice BlockBuilder::Finish() {
// Append restart array
for (size_t i = 0; i < restarts_.size(); i++) {
PutFixed32(&buffer_, restarts_[i]); // 填充所有的重启点到 buffer
}
PutFixed32(&buffer_, restarts_.size()); // 填充重启点的数量到 buffer
finished_ = true;
return Slice(buffer_); // 返回整个 buffer
}
说明
DataBlock 数据不能无限增长,它的大小上限收到Options.block_size参数控制, 默认大小4KB.
如果在数据写入过程中超过了大小上限,此时将重新开一个DataBlock继续写。
所以一个SST中可能会有多个DataBlock.
FilterBlock

FilterBlock 用来存储 DataBlock 中的 BloomFilter 值,每个 DataBlock 对应有一个 BloomFilter 存放在这个 FilterBlock 中。
每当 DataBlock 刷盘时, 会构建一个 BloomFilter, 将这个 DataBlock 中所有的 key 加入到这个 BloomFilter 中。
所以有多少个 DataBlock 就有多少个 BloomFilter, 这些 BloomFilter 会拼接到一起。
他们使用 filter_offsets_[] 来记录下每个 bloomFilter 偏移。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
/***
* Bloom 过滤器构建过程 :
* keys_ : 将所有的key都平铺拼接在一起
* start_ : 每个 key 的偏移位置
* result : 存放得到的过滤器结果, 具有多个过滤器
* filter_offsets_ : 每个过滤器的偏移量
*/
void FilterBlockBuilder::GenerateFilter() {
const size_t num_keys = start_.size(); // 获取 key 的数量
if (num_keys == 0) {
filter_offsets_.push_back(result_.size());
return;
}
// Make list of keys from flattened key structure
start_.push_back(keys_.size()); // 因为每次都是填充上一次的key, 所以这次记录总得key的长度
// 提取出所有的 key 使用 vector 存储
tmp_keys_.resize(num_keys);
for (size_t i = 0; i < num_keys; i++) {
const char* base = keys_.data() + start_[i];
size_t length = start_[i + 1] - start_[i];
tmp_keys_[i] = Slice(base, length);
}
// 存储上次 Bloom 过滤器写入后的数据大小
filter_offsets_.push_back(result_.size());
// 计算 Bloom 过滤器的值, 并追加到 result 中
policy_->CreateFilter(&tmp_keys_[0], static_cast<int>(num_keys), &result_);
// 清空 key
tmp_keys_.clear();
keys_.clear();
start_.clear();
}
当所有的 DataBlock 落盘后, FilterBlock 构造完成开始落盘 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Slice FilterBlockBuilder::Finish() {
// 如果有 key 没有还没有计算完bloomFilter 则触发计算
if (!start_.empty()) {
GenerateFilter();
}
// Append array of per-filter offsets
const uint32_t array_offset = result_.size();
for (size_t i = 0; i < filter_offsets_.size(); i++) {
// 填充每个bloom过滤器的偏移
PutFixed32(&result_, filter_offsets_[i]);
}
// 填充总的Bloom过滤器的长度
PutFixed32(&result_, array_offset);
// 填充 11
result_.push_back(kFilterBaseLg); // Save encoding parameter in result
return Slice(result_);
}
小技巧
为了提高基于 DataBlock 在文件中的偏移位置来定位 BloomFilter 的速度, 并不是 BloomFilter的数量与 filter_offsets_ 的个数一一对应。
每次 DataBlock 写完, 假设下次写入的 DataBlock偏移量为 next_datablock_offset。
则这次 DataBlock 的 filter_offsets_ 要填充到(next_datablock_offset/1<<11)-1,保证下个DataBlock的 BloomFilter 从 (next_datablock_offset/1<<11)处开始填充。
1
2
3
4
5
6
7
8
9
10
void FilterBlockBuilder::StartBlock(uint64_t block_offset) {
uint64_t filter_index = (block_offset / kFilterBase); // 现在需要的 filter_offset 数量
assert(filter_index >= filter_offsets_.size());
// 存在的意义是为了多写几个无效的偏移
// 然后用于快速基于 block_offset 快速定位 filter_offsets
while (filter_index > filter_offsets_.size()) {
GenerateFilter();
}
}
这样我们拿到DataBlock的偏移位置datablock_offset后。BloomFilter将位于FilterBlock的filter_offsets_[datablock_offset/1<<11]位置。
读取逻辑 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
bool FilterBlockReader::KeyMayMatch(uint64_t block_offset, const Slice& key) {
// 基于 block_offset 定位到 offset_[index]
uint64_t index = block_offset >> base_lg_; // 等同于 block_offset/kFilterBase
if (index < num_) {
// 截取 Bloom 过滤器
uint32_t start = DecodeFixed32(offset_ + index * 4);
uint32_t limit = DecodeFixed32(offset_ + index * 4 + 4);
if (start <= limit && limit <= static_cast<size_t>(offset_ - data_)) {
Slice filter = Slice(data_ + start, limit - start);
// 匹配查找
return policy_->KeyMayMatch(key, filter);
} else if (start == limit) {
// Empty filters do not match any keys
return false;
}
}
return true; // Errors are treated as potential matches
}
MetaIndexBlock
MetaIndexBlock 主要用来记录 FilterBlock 的在文件中的偏移位置, 充当 FilterBlock 的索引

它的数据结构跟 DataBlock 一样,不过他只有一个 Key-Value, 只有一个Block.
- Key :
filter.leveldb.BuiltinBloomFilter2 - Value : BloomFilter 在文件中的索引(起始位置,大小)
IndexBlock
IndexBlock 数据结构与 DataBlock 相同,它有多个 Key-Value 组成,只有一个Block.
他用来索引DataBlock, 每一个DataBlock在IndexBlock中具有一个键值对数据。
- Key : DataBlock 比这个DataBlock最后一个key稍大,但小于下一个DataBlock(如果存在的话)第一个key的字符串.
- Value : DataBlock 的索引(起始位置,大小)
Footer
Footer 在SST 的末尾, 他由固定的 48 字节构成。

第一部分为 MetaIndexBlock 的索引构成(起始位置,大小), 第二部分为 IndexBlock的索引构成(起始位置,大小)。
如果这两部分加起来长度不足40,则补零填充到40字节。
最后填充8字节的幻数,完成SST的填充。
总结
SST 是一个包含数据,索引,过滤的一个数据结构。
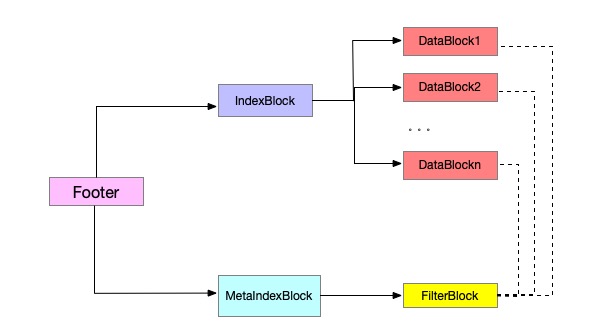
第一层索引位于Footer结构中。它位于文件末尾占据48个字节。它内部维护有 IndexBlock 与 MetaIndexBlock 的位置索引
IndexBlock 中维护 DataBlock 的位置索引, MetaIndexBlock维护了FilterBlock的位置索引。
数据在进行查找到此SST时, 首先通过IndexBlock,找到第一个大于查找key的数据(因为数据是递增的)。
如果已经找到对应的数据,则其value就是对应DataBlock的文件位置, 此时通过FilterBlock基于DataBlock偏移位置快速定位到BloomFilter值,通过BloomFilter判断数据是否在这个DataBlock中。
如果数据存在DataBlock中, 则通过偏移位置读取DataBlock, 先通过基于重启点的二分查找,定位到数据的粗略位置,在缩短范围,从定位到的重启点处顺序比较,进行精确查找。