Linux 教程 | 内存管理篇之内存寻址

内存地址:
现代操作系统为了实现程序的运行时动态链接, 动态运行时的装入方式, 保护模式 和 虚拟内存 等技术, 在程序的内存寻址方面采用逻辑地址替代物理地址。
- 运行时动态链接 : 是指将程序运行时所需要的链接库暂时驻留在磁盘中, 当程序执行到需要的库函数时,才将库链接到内存中,加入程序的地址空间。
- 动态运行时的装入方式 : 是指装入程序在把装入模块装入内存后,并不立即把装入模块中的相对地址转换为绝对地址,而是把这种地址转换推迟到程序真正要执行时才进行。
由于这种功能的支持导致程序实现不能确定每一个指令或者操作数的物理地址, 寻址上造成困难,所以引入逻辑地址来标识每一个指令或操作数的位置。
而现在操作系统的硬件级别已经支持了一种内存控制单元(MMU) 的地址转换器用来实现逻辑地址到物理地址的转换。
MMU 先通过分段单元的硬件电路把一个逻辑地址转换成线性地址, 然后通过分页单元的硬件电路把线性地址换成一个物理地址。

逻辑地址:
包括在机器语言指令中指定操作数或者一条指令的地址。每个逻辑地址都由一个段选择符和偏移量组成,偏移量指明了从段开始的地方到实际地址的距离。
线性地址:
也称为虚拟地址,32位或64位的无符号整数,在32位系统中可以用来表示高达4GB的地址。
物理地址:
芯片级内存单元寻址。与从微处理器的地址引脚发送到内存总线上的电信号相对应。地址空间大小由微处理器地址引脚数决定,无符号整数表示。
分段技术:
分段单元是用于实现逻辑地址到线性地址的转换
分段单元:

分段单元(segmentation)执行下列操作:
- 定位 GDT/LDT 表的起始位置
先检查段选择符中的TI字段,以决定段描述符保存在哪一个描述符表中,TI=1则在LDT中,TI=0则在GDT中。如果在GDT中,分段单元从gdtr寄存器中得到GDT的线性地址,否则从ldtr寄存器中得到LDT的线性地址。
- 定位段描述符的位置(距离起始位置偏移量)
将段选择符的地址与gdtr或ldtr的内容相加。
- 计算线性地址:
把逻辑地址的偏移量与段描述符的Base字段的值相加就得到了线性地址。
段选择符:
一个逻辑地址由两部分组成:一个段标识符 和一个指定段内相对地址的偏移量 。段标识符是一个16位长的字段,称为段选择符(Segment Selector),而偏移量是一个32位长的字段。

| 字段名 | 描述 |
|---|---|
| 索引 | 指定了放在GDT或LDT中的相应段描述符 |
| TI | TI(Table Indicator)标志,指明段描述符是在GDT中(TI=0)或在LDT中(TI=1) |
| RPL | 请求者特权级,当相应的段选择符装入到cs寄存器中时指示出CPU当前的特权级,它还可以用于在访问数据段时有选择地削弱处理器的特权级。 Linux 只用 0 和 3.用来表示用户态和内核态。 |
为了快速方便地找到段选择符,处理器提供段寄存器,段寄存器地唯一目的是存放段选择符。这些段寄存器称为cs、ss、ds、es、fs和gs。尽管只有6个段寄存器,但程序可以把同一个段寄存器用于不同地目的,这6个段寄存器3个有专门的用途:
- cs:代码段寄存器,指向包含程序指令的段。
- ss:栈段寄存器,指向包含当前程序栈的段。
- ds:数据段寄存器,指向包含静态数据或者全局数据段
其他3个段寄存器作一般用途,可以指向任意的数据段。cs寄存器还有一个很重要的功能:它含有一个 两位的字段,用以指明CPU的 当前特权级(Current Privilege Level, CPL)。0代表最高优先级——内核态,而3代表最低优先级——用户态。
段描述符表
段描述符表是用来存放段描述符的一个数据结构,段表分为全局描述符表(Global Descriptor Table, GDT)或 局部描述符表(Local Descriptor Table, LDT) .
GDT在主存中的地址和大小存放在 gdtr控制寄存器 中,当前正被使用的LDT地址和大小放在 ldtr控制寄存器 中。
由 GDT 映射的地址空间称为全局地址空间,由 LDT 映射的地址空间则称为局部地址空间,而这两者构成了虚拟地址的空间。
Linux GDT :
在操作系统中,每一个cpu对应一个GDT. GDT 为一个长度为32的段描述符数组:extern struct desc_struct cpu_gdt_table[NR_CPUS][GDT_ENTRIES];
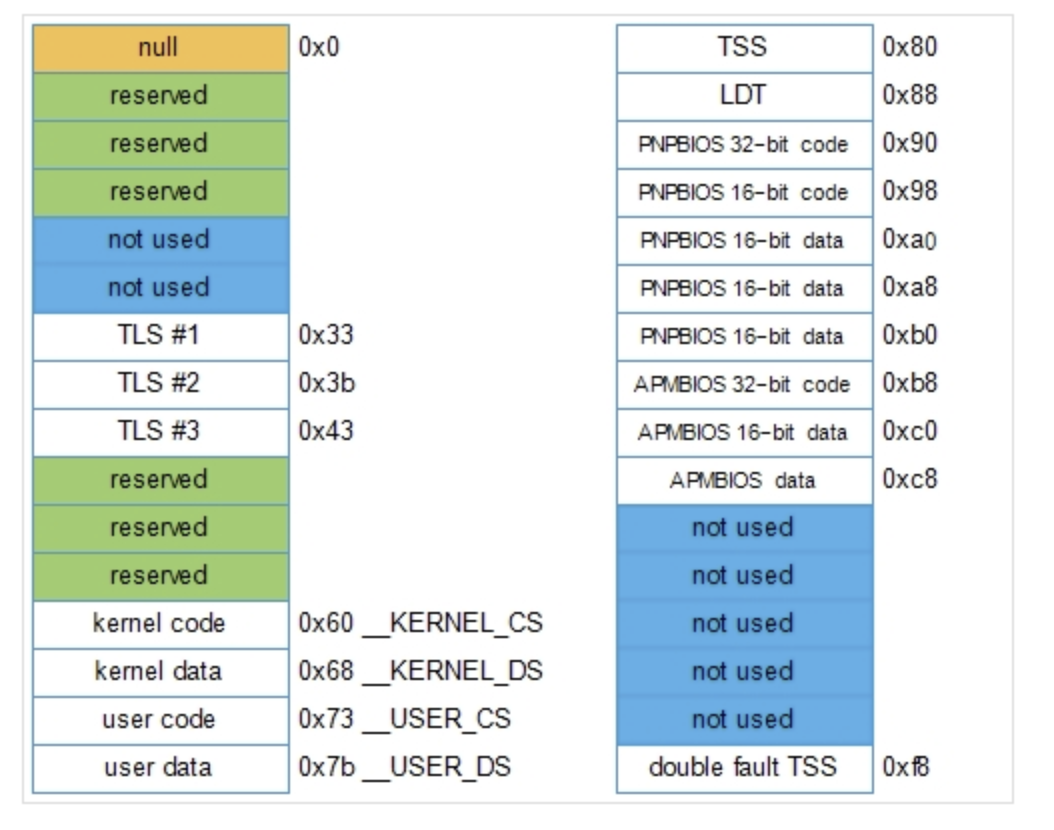
- 用户态和内核态下的代码段和数据段,共4个。
- 任务状态段(TSS),每个处理器有1个。每个TSS相应的线性地址空间都是内核数据段相应线性地址空间的一个小子集。所有的任务状态段都顺序地存放在init_tss数组中,值得特别说明的是,第n个CPU的TSS描述符的Base字段指向init_tss数组的第n个元素。G(粒度)标志被清0,而Limit字段置为0xeb, 因为TSS段是236字节长。Type字段置为9或11(可用的32位TSS),且DPL置 为0,因为不允许用户态下的进程访问TSS段。
- 1个包括缺省局部描述符表的段,这个段通常被所有进程共享。
- 3个局部线程存储(Thread-Local Storage, TLS)段:这种机制允许多线程应用程序使用最多3个局部于线程的数据段。系统使用set_thread_area()和get_thread_area()分别为正在执行的进程创建和撤销一个TLS段。
- 与高级电源管理(APM)相关的3个段:由于BIOS代码使用段,所以当Linux APM驱动程序调用BIOS函数来获取或者设置APM设备的状态时,就可以使用自定义的代码段和数据段。
- 与支持即插即用(PnP)功能的BIOS服务程序相关的5个段。
- 被内核用来处理“双重错误”异常(处理一个异常时可能会引发另一个异常)的特殊TSS段。
Linux LDT :
大多数用户态下的Linux程序不使用局部描述符表,因此内核就定义了一个缺省的LDT供大多数进程共享。缺省的局部描述符表存放在default_ldt数组中。它包含5个项,但内核仅仅有效地使用了其中的两个项:用于iBCS执行文件的调用门和Solaris/x86可执行文件的调用门。调用门是80x86微处理器提供的一种机制,用于在调用预定义函数时改变CPU的特权级(参考Intel文档以获取更多详情)
段描述符:
段描述符表中的每一项为一个段描述符
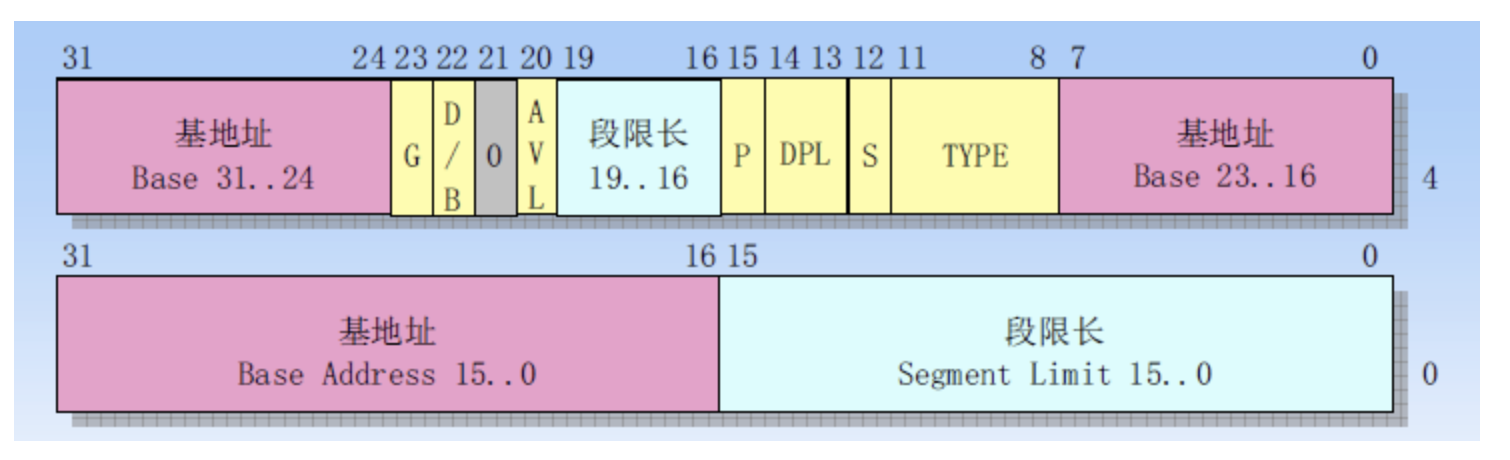
| 字段名 | 描述 |
|---|---|
| 基地址(Base) | 包含段的首字节的线性地址 (32 bit) |
| G | 粒度标志;置0,则段大小以字节为单位,否则以4096字节的倍数计 |
| Limit | 最大段偏移量,段的长度(20 bit)。如果G被置为0,则一个段的大小在1个字节到1MB之间变化;否则,将在4KB到4GB之间变化 |
| S | 系统标志;置0,系统段,存储诸如LDT这种关键的数据结构,否则它是一个普通的代码段或数据段 |
| Type | 描述了段的类型特征和它的存取权限(数据段为2, 代码段为10) |
| DPL | 描述符特权级(Descriptor Privilege Level)字段;用于限制对这个段的存取。表示访问这个段要求的CPU最小的优先级, 用户段为3, 内核段为0 |
| P | Segment-Present标志;为0表示段当前不在主存中。Linux总是把这个标志(第47位)设为1,因为它从来不把整个段交换到磁盘上去 |
| D或B | 取决于是代码段还是数据段 |
| AVL | 操作系统使用,但被Linux忽略 |
主要的Linux 段的描述符字段值:
| 段 | Base | G | Limit | S | Type | DPL | D/B | P |
|---|---|---|---|---|---|---|---|---|
| 用户代码段 | 0x00000000 | 1 | 0xfffff | 1 | 10 | 3 | 1 | 1 |
| 用户数据段 | 0x00000000 | 1 | 0xfffff | 1 | 2 | 3 | 1 | 1 |
| 内核代码段 | 0x00000000 | 1 | 0xfffff | 1 | 10 | 0 | 1 | 1 |
| 内核数据段 | 0x00000000 | 1 | 0xfffff | 1 | 2 | 0 | 1 | 1 |
linux 中的分段小说明:
2.6的Linux只在x86下需要分段,而且这个分段实际上是个面子工程。Linux用户态的所有进程使用相同的段对指令和数据寻址,内核态所有进程也使用相同的段来对指令和数据寻址。
所有的段都是0~0xFFFFFFFF 4G的寻址空间,也就是说它们共享同一片虚拟地址空间。换句话说,对于Linux来说,逻辑地址和线性地址是一致的,这也是为什么逻辑地址并不广为人知的原因,Linux的设计让他的存在感微乎其微。
区别之处在于DPL不同,这很好理解。数据段的Type为2也就是0010B,它表示可读可写,尚未受到访问。而代码段Type为10也就是1010B,表示可读可执行,尚未受到访问。CPU映射过程中会核对这些项。如果DPL为0,CS中RPL为3,对不起,不允许。
4个段的段选择符由宏 __USER_CS, __USER_DS, __KERNEL_CS, __KERNEL_DS 分别定义。当对内核代码段寻址时,内核只需要把 __KERNEL_CS 宏值装入cs即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
/**
* asm-i386/segment.h
*/
#define GDT_ENTRY_DEFAULT_USER_CS 14
#define __USER_CS (GDT_ENTRY_DEFAULT_USER_CS * 8 + 3) // 0x73
#define GDT_ENTRY_DEFAULT_USER_DS 15
#define __USER_DS (GDT_ENTRY_DEFAULT_USER_DS * 8 + 3) // 0x7b
#define GDT_ENTRY_KERNEL_BASE 12
#define GDT_ENTRY_KERNEL_CS (GDT_ENTRY_KERNEL_BASE + 0) // 0x60
#define __KERNEL_CS (GDT_ENTRY_KERNEL_CS * 8)
#define GDT_ENTRY_KERNEL_DS (GDT_ENTRY_KERNEL_BASE + 1) // 0x68
#define __KERNEL_DS (GDT_ENTRY_KERNEL_DS * 8)
CPU的CPL反映了进程实在用户态还是内核态,由存放在cs寄存器的RPL字段指定。当CPL改变时,一些段寄存器必须更新。这一点很好理解,当cs寄存器的RPL字段是3,也就是说CPL为3,表示当前进程是用户态进程,那么此时ds寄存器就应该包含的是用户数据段的段选择符,也就是__USER_DS,而当cs寄存器RPL切换到0时,ds寄存器也要切换到内核态数据段。除了ds,ss亦是如此。Linux每个进程都有内核栈和用户栈,ring0和ring3之间的切换也会导致系统栈的切换。
有关 Linux GDT 定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
/**
* i386/head/head.S
*/
ENTRY(cpu_gdt_table)
.quad 0x0000000000000000 /* NULL descriptor */
.quad 0x0000000000000000 /* 0x0b reserved */
.quad 0x0000000000000000 /* 0x13 reserved */
.quad 0x0000000000000000 /* 0x1b reserved */
.quad 0x0000000000000000 /* 0x20 unused */
.quad 0x0000000000000000 /* 0x28 unused */
.quad 0x0000000000000000 /* 0x33 TLS entry 1 */
.quad 0x0000000000000000 /* 0x3b TLS entry 2 */
.quad 0x0000000000000000 /* 0x43 TLS entry 3 */
.quad 0x0000000000000000 /* 0x4b reserved */
.quad 0x0000000000000000 /* 0x53 reserved */
.quad 0x0000000000000000 /* 0x5b reserved */
.quad 0x00cf9a000000ffff /* 0x60 kernel 4GB code at 0x00000000 */
.quad 0x00cf92000000ffff /* 0x68 kernel 4GB data at 0x00000000 */
.quad 0x00cffa000000ffff /* 0x73 user 4GB code at 0x00000000 */
.quad 0x00cff2000000ffff /* 0x7b user 4GB data at 0x00000000 */
.quad 0x0000000000000000 /* 0x80 TSS descriptor */
.quad 0x0000000000000000 /* 0x88 LDT descriptor */
/* Segments used for calling PnP BIOS */
.quad 0x00c09a0000000000 /* 0x90 32-bit code */
.quad 0x00809a0000000000 /* 0x98 16-bit code */
.quad 0x0080920000000000 /* 0xa0 16-bit data */
.quad 0x0080920000000000 /* 0xa8 16-bit data */
.quad 0x0080920000000000 /* 0xb0 16-bit data */
/*
* The APM segments have byte granularity and their bases
* and limits are set at run time.
*/
.quad 0x00409a0000000000 /* 0xb8 APM CS code */
.quad 0x00009a0000000000 /* 0xc0 APM CS 16 code (16 bit) */
.quad 0x0040920000000000 /* 0xc8 APM DS data */
.quad 0x0000000000000000 /* 0xd0 - unused */
.quad 0x0000000000000000 /* 0xd8 - unused */
.quad 0x0000000000000000 /* 0xe0 - unused */
.quad 0x0000000000000000 /* 0xe8 - unused */
.quad 0x0000000000000000 /* 0xf0 - unused */
.quad 0x0000000000000000 /* 0xf8 - GDT entry 31: double-fault TSS */
分页技术
当由逻辑地址转换到线性地址后,下一步线性地址经过 分页单元 来将线性地址转换为物理地址。
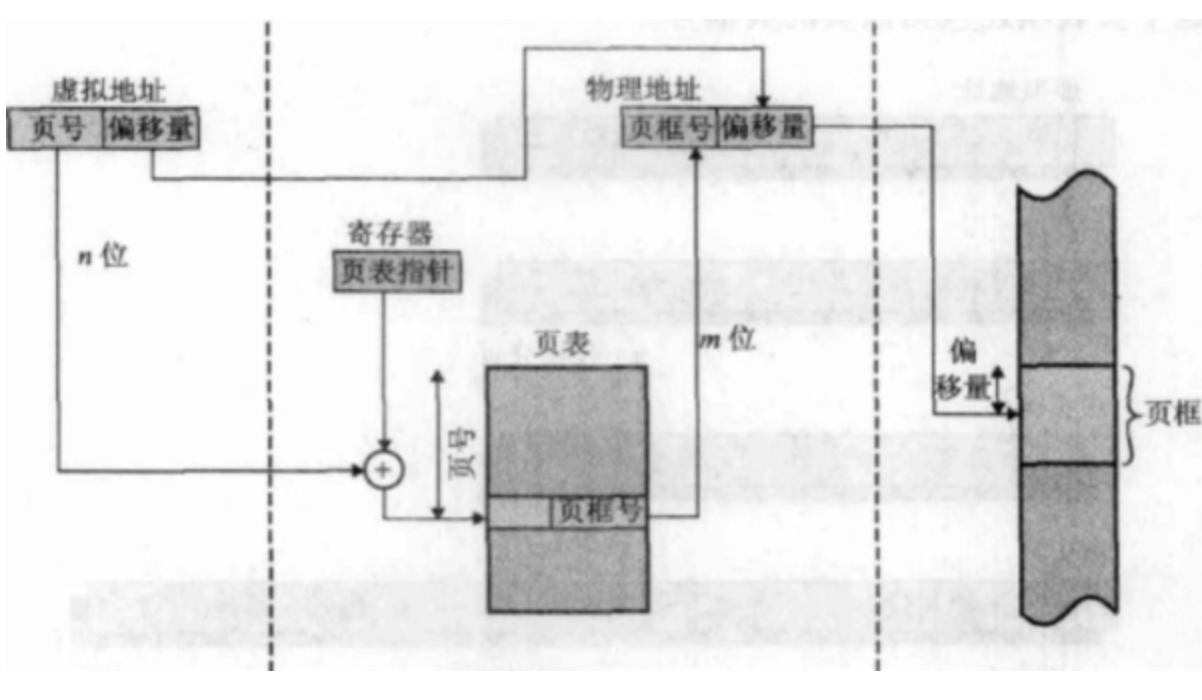
操作系统的分页逻辑大致如此,整个内存空间分成n个大小相等物理块(页框),并且进程的内存空间是由若干与物理块大小相等的页组成。每个页有一个页编号,从 0 开始,如第 0 页、第 1 页等。
线性地址大致分成两部分:
- 第一部分为页号, 即选定的内存区位于第几页上。
- 第二部分为页内偏移量, 指内存单元在内存页的距离页起始位置的偏移量。
当我们知道页号之后还不足以知道这个页所在的实际物理位置, 完成由内存页到物理块的映射的部分称为页表。 每个进程具有一组页表, 顺序排列按照位置第几个页表项既代表第几页,每个页表项中记录物理块号的位置来完成映射关系。 页表项的位置存储在cr3寄存器中。
Linux中的页与页表项:
Linux 每一页大小为 4KB($2^{12} B$), 页内偏移量一般占线性地址低12位。页偏移量长度使用 PAGE_SHIFT定义
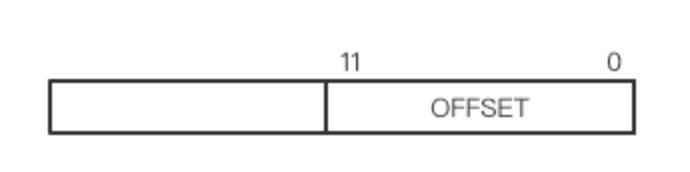
每一个页表项包含的信息为:
| 页表项字段 | 介绍 |
|---|---|
| Present | 虚拟地址对应的物理页面不在内存中,比如页被交换出去,此时页表项的其他部分通常会代表不同的含义,因为不需要描述页在物理内存中的地址,相反,需要信息来找到换出的页。 |
| Field | 物理地址的高位字段(物理地址总地址长度-PAGE_SHIFT),由于每页大小为 2^{PAGE_SHIFT}, 所以总共可以分 2^{总地址长度} / 2^{PAGE_SHIFT}. |
| Accessed | 每次分页单元访问页面时,都会自动设置Accessed位,内核会定期检查该位,以便确定页的活跃程度,内核会选择不活跃的页面swapout到交换空间。注意分页单元只负责置位,清除位操作要内核自己执行。 |
| Dirty | 仅仅存在于页表项,每当向页帧写入数据分页单元都会设置dirty标志,swap进程可以通过这个位来决定是否选择这个页面进行交换。记住,分页单元不会清除这个标记,所以必须由操作系统来清除这个标记。 |
| Read/Write | 包含了页面的读写权限,如果设置为0,那么只有读权限;设置为1,则有读写权限。 |
| User/Supervisor | User允许用户空间代码访问该页;Supervisor只有内核才可以访问。 |
| Exec | 在较新的64bit处理器上,分页单元支持No eXec位,因此2.6.11内核开始加入了这个标志。 |
| Page Size | 应用于页目录项,如果设置为1,则表示启用大页. |
但是在实际的 linux 中并不是只有这两部分,如果每个页大小为4KB($2^{12}$), 则对于 4G 的内存空间,最多需要有$2^{20}$ 张页既$2^{20}$ 个页项,每个页项空间大小为4B,则需要 4MB的连续空间才能存储。远超过物理块大小。
所以一般采取多级分页,每个页表大小为一个页,在页表之上在建立页目录,记录页表所在物理块位置。
Linux 提供了一种同时适用于32位和64位系统的四级分页模型分页模型

这四种页表分别为 :
- 页全局目录(PGD)
- 页上级目录(PUD)
- 页中间目录(PMD)
- 页表(PT)
寻址过程为:
- 首先读取 cr3 寄存器,获取 页全局目录 PGD 的位置
- 根据线性地址中的GLOBAL 部分的值计算找到指定的目录项,获取到页上级目录 PUD的地址。
- 根据线性地址中的UPPER 部分的值计算找到指定的目录项, 获得页中间目录 PMD的地址。
- 根据线性地址中的MIDDLE 部分的值计算找到指定目录项, 获得页表 PT 的地址。
- 根据线性地址中的 TABLE 部分的值计算找到指定目录项, 计算找到指定的页地址。
- OFFSET 为实际地址在页内偏移量。
有关分页的宏定义:
| 宏定义 | 说明 |
|---|---|
| PAGE_SHIFT | Offset 字段长度 |
| PAGE_SIZE | 页大小 |
| PAGE_MASK | 屏蔽Offset 所有位 |
| PMD_SHIFT | Offset+Table总位数 |
| PMD_SIZE | Offset + Table 映射的总页大小 |
| PMD_MASK | 屏蔽 Offset + PMD 所有位 |
| PUD_SHIFT | Offset + Table + Middler 总位数 |
| PUD_SIZE | Offset + Table + Middler 映射的总页大小 |
| PUD_MASK | 屏蔽 Offset + Table + Middler 所有位 |
| PGDIR_SHIFT | Offset + Table + Middler + Upper 总位数 |
| PGDIR_SIZE | Offset + Table + Middler + Upper 映射的总页大小 |
| PGDIR_MASK | 屏蔽 Offset + Table + Middler + Upper 所有位 |
| PTRS_PER_PGD | 页全局目录表中的表项个数 |
| PTRS_PER_PUD | 页上级目录表中的表项个数 |
| PTRS_PER_PMD | 表中间目录表中的表项个数 |
| PRTS_PER_PTE | 页表项中的表项个数 |
页表处理:
变量 : 页表项(pte_t), 页中间目录项(pmd_t), 页上级目录项(pud_t), 页全局目录项(pgd_t)
| 函数 | 作用 |
|---|---|
| pte_page | 根据页表项获取对应页的页框的描述符地址 |
| pmd_page | 根据页中间目录项获取对应的页表所在页框的描述符地址 |
| pud_page | 根据页上级目录项获取对应的页中间目录所在页框的描述符地址 |
| pgd_page | 根据页全局目录项获取对应的页上级目录所在页框的描述符地址 |
页框描述符位于一个全局变量数组struct page *mem_map;,其中记录页框的实际地址位置。有关定位过程在后期介绍
但并不是所有的地址寻址都具有完整的四级分页模型。
x86(32位) 的普通分页模型
在 i386 的体系架构中,地址长度为 32 位, PAGE_SHIFT 默认大小为12, 既页大小为4KB($2^{12}$).
每个页表项大小为4B, 所以一张页表可以存放1024个页表项($2^{10}$), 则使用了两级页表技术 :

相应的寻址变为:
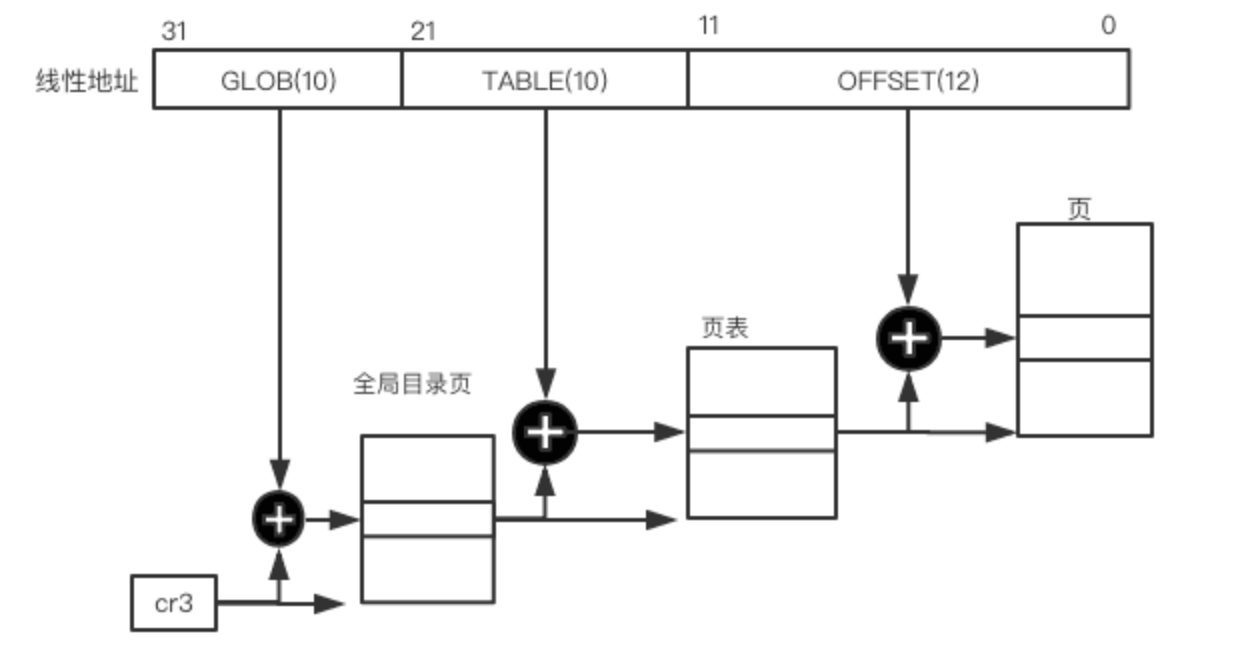
有关分页的宏定义:
1
2
3
4
5
6
7
8
9
10
#define PAGE_SHIFT 12
#define PAGE_SIZE (1UL << PAGE_SHIFT)
#define PAGE_MASK (~(PAGE_SIZE-1))
#define PGDIR_SHIFT 22
#define PGDIR_SIZE (1UL << PGDIR_SHI FT)
#define PGDIR_MASK (~(PGDIR_SIZE-1))
#define PTRS_PER_PGD 1024
#define PTRS_PER_PTE 1024
有关分页的操作:
1
2
3
4
5
6
7
8
9
typedef struct { unsigned long pte_low; } pte_t;
typedef struct { unsigned long pgd; } pgd_t;
// 获取页表项页框号
#define pte_pfn(x) ((unsigned long)(((x).pte_low >> PAGE_SHIFT)))
// 根据页表项页框号获取页框地址的描述符地址
#define pte_page(x) pfn_to_page((x))
#define pfn_to_page(pfn) (mem_map + (pfn))
x86中启用PAE的分页模型
物理地址扩展(Physical Address Extension),是x86处理器的一个功能,让中央处理器在32位操作系统下存取超过4GB的实体内存。
PAE 为 Intel Pentium Pro 及以上级别的CPU(包括除了总线频率为400MHz的这个版本的奔腾M之外的所有新型号Pentium系列处理器)所支持,其他兼容的处理器,如速龙(Athlon)和AMD的较新型号的CPU也支持PAE。
在硬件层面上Intel 通过在它的处理器上把管脚数从32位扩展到了36位,从而支持达到 64G 的物理地址寻址技术。
而线性地址长度为32位,所以每个进程的总的地址空间仍为 4G, 而物理地址寻址总共支持到 64G 的寻址空间,这样就可以同时允许更多的进程驻留内存中。
在分页技术上,线性地址为32位长度,但是在页表跟页目录上对页表项的物理地址字段从20位扩展到了24位($2^{24}$ 个页框, PAGE_SHIFT 仍为 12 $2^{24} * 2^{12} = 2^{36}$). 每个页项大小变为8B, 一个4KB的页表存储的页项变为 512个。所以需要使用三级页表技术:
通过设置cr4 控制寄存器的PAE标志来激活PAE, 寻址演变成:

寻址演变为:
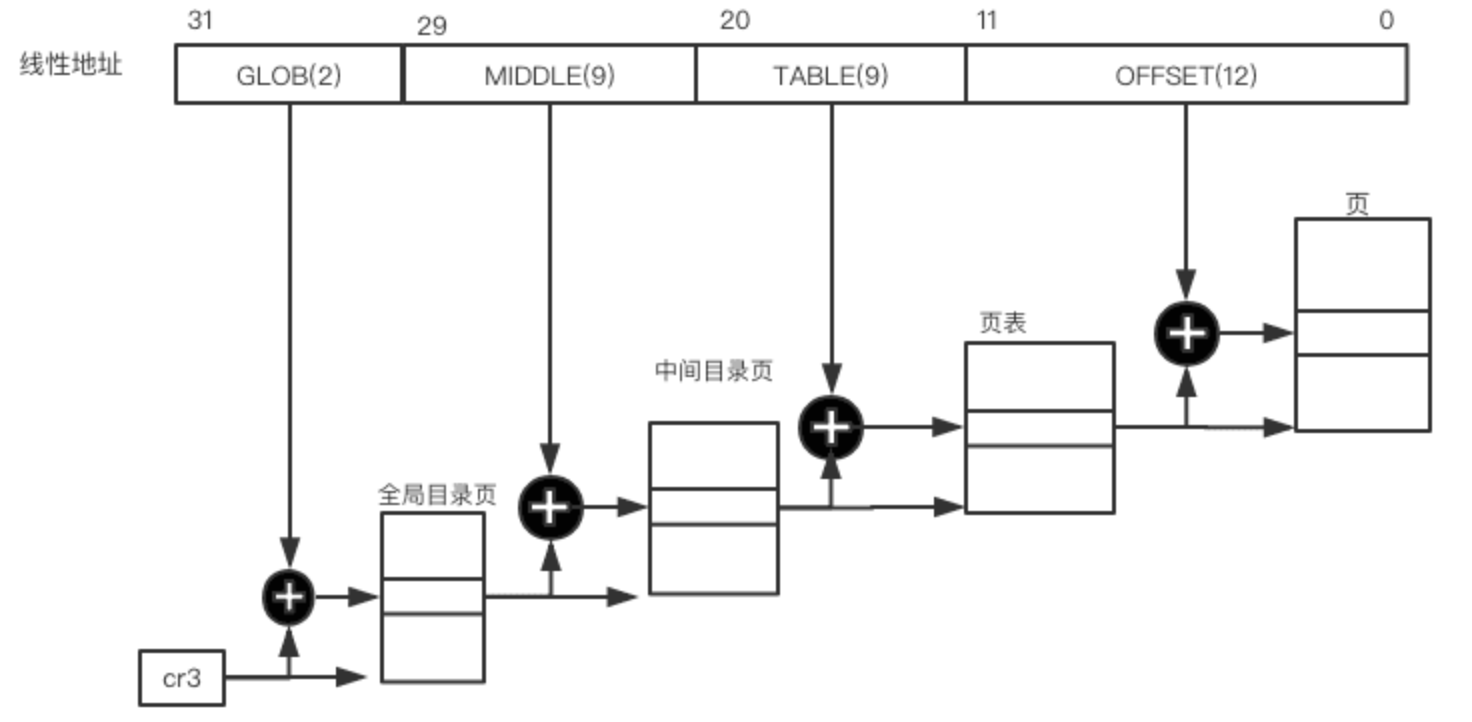
有关分页的宏定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#define PGDIR_SHIFT 30
#define PGDIR_SIZE (1UL << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE-1))
#define PUD_SHIFT PGDIR_SHIFT
#define PUD_SIZE (1UL << PUD_SHIFT)
#define PUD_MASK (~(PUD_SIZE-1))
#define PMD_SHIFT 21
# define PMD_SIZE (1UL << PMD_SHIFT)
# define PMD_MASK (~(PMD_SIZE-1))
#define PTRS_PER_PGD 4
#define PTRS_PER_PUD 1
#define PTRS_PER_PMD 512
#define PTRS_PER_PTE 512
有关分页的操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
typedef struct { unsigned long pte_low, pte_high; } pte_t;
typedef struct { unsigned long long pmd; } pmd_t;
typedef struct { pgd_t pgd; } pud_t;
typedef struct { unsigned long long pgd; } pgd_t;
#define pgd_val(x) ((x).pgd)
#define pud_val(x) (pgd_val((x).pgd))
#define pmd_val(x) ((x).pmd)
#define pte_val(x) ((x).pte_low | ((unsigned long long)(x).pte_high << 32))
// 根据页表项页框号获取页框地址的描述符地址
#define pfn_to_page(pfn) (mem_map + (pfn))
/**
* 页表
*/
// 获取页表项页框号
static inline unsigned long pte_pfn(pte_t pte)
{
return (pte.pte_low >> PAGE_SHIFT) |
(pte.pte_high << (32 - PAGE_SHIFT));
}
#define pte_page(x) pfn_to_page(pte_pfn(x))
/**
* 页中间目录
*/
#define pmd_page(pmd) (pfn_to_page(pmd_val(pmd) >> PAGE_SHIFT))
/**
* 页全局目录
*/
#define pgd_page(pgd) (pud_page((pud_t){ pgd }))
#define pud_page(pud) ((struct page *) __va(pud_val(pud) & PAGE_MASK))
x86_64 的分页模型 :
在 64位机器机器中分页级别与处理器类型有关,不同平台适用不同的分页类型:
| 平台名称 | 页大小 | 寻址所使用的位数 | 分页级别数 | 线性地址分级 |
|---|---|---|---|---|
| alpha | 8KB | 43 | 3 | 10 + 10 + 10 + 13 |
| ia64 | 4KB | 39 | 3 | 9 + 9 + 9 + 12 |
| ppc64 | 4KB | 41 | 3 | 10 + 10 + 9 + 12 |
| sh64 | 4KB | 41 | 3 | 10 + 10 + 9 + 12 |
| x86_64 | 4KB | 48 | 4 | 9 + 9 + 9 + 9 + 12 |
从上面可以看出, 在 x86_64 处理机中虽然线性地址长度为64位,但是实际的用于寻址的长度只有48位有效地址, 每个进程最大支持的地址空间为 : $2^{48} = 256TB$.
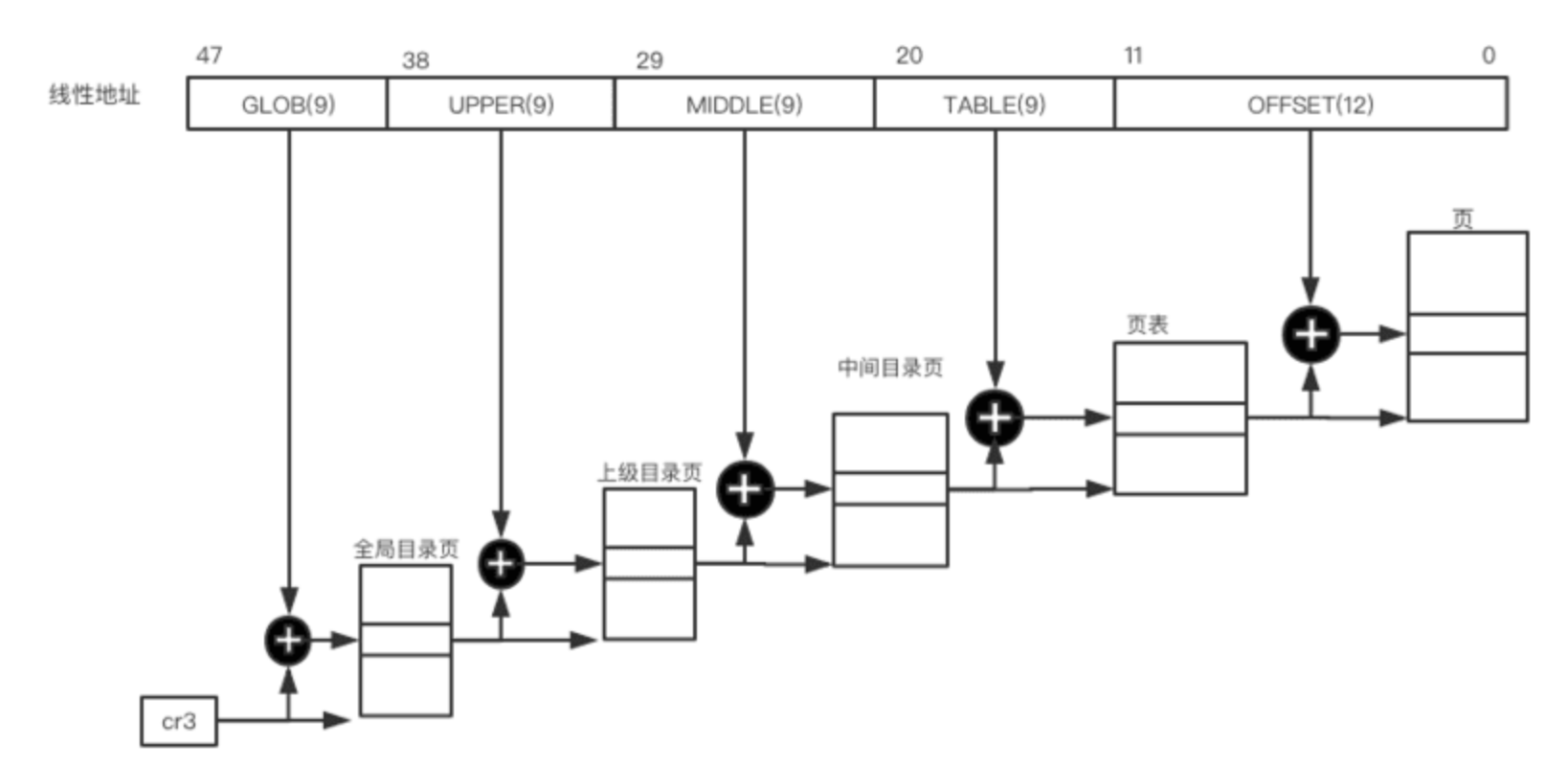
有关分页的宏定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#define PAGE_SHIFT 12
#define PAGE_SIZE (1UL << PAGE_SHIFT)
#define PAGE_MASK (~(PAGE_SIZE-1))
#define PMD_SHIFT 21
#define PMD_SIZE (1UL << PMD_SHIFT)
#define PMD_MASK (~(PMD_SIZE-1))
#define PUD_SHIFT 30
#define PUD_SIZE (1UL << PUD_SHIFT)
#define PUD_MASK (~(PUD_SIZE-1))
#define PGDIR_SHIFT 39
#define PGDIR_SIZE (1UL << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE-1))
#define PTRS_PER_PGD 512
#define PTRS_PER_PUD 512
#define PTRS_PER_PMD 512
#define PTRS_PER_PTE 512
有关分页的操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
typedef struct { unsigned long pte; } pte_t;
typedef struct { unsigned long pmd; } pmd_t;
typedef struct { unsigned long pud; } pud_t;
typedef struct { unsigned long pgd; } pgd_t;
#define pte_val(x) ((x).pte)
#define pmd_val(x) ((x).pmd)
#define pud_val(x) ((x).pud)
#define pgd_val(x) ((x).pgd)
// 页框号获取页框地址的描述符地址
#define pfn_to_page(pfn) (mem_map + (pfn))
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
/**
* 页表操作
*/
#define pte_pfn(x) ((pte_val(x) >> PAGE_SHIFT) & __PHYSICAL_MASK) // ? __PHYSICAL_MASK
#define pte_page(x) pfn_to_page(pte_pfn(x))
/**
* 页中间目录
*/
#define pmd_page(pmd) (pfn_to_page(pmd_val(pmd) >> PAGE_SHIFT))
/**
* 页上级目录
*/
#define pud_page(pud) ((unsigned long) __va(pud_val(pud) & PHYSICAL_PAGE_MASK))
/**
* 页全局目录
*/
#define pgd_page(pgd) ((unsigned long) __va((unsigned long)pgd_val(pgd) & PTE_MASK))
大页模式
在 Linux 操作系统上运行内存需求量较大的应用程序时,由于其采用的默认页面大小为 4KB,因而将会产生较多 TLB Miss 和缺页中断,从而大大影响应用程序的性能。 当操作系统以 2MB 甚至更大作为分页的单位时,将会大大减少 TLB Miss 和缺页中断的数量,显著提高应用程序的性能。这也正是 Linux 内核引入大页面支持的直接原因。
大型页不使用最后一级页表,将Table字段与Offset字段合并位大型页的页内偏移量, 所以产生大型页尺寸的LARGE_PAGE_SIZE宏等于PMD_SIZE, 相应的用于屏蔽Offset字段和Table字段的所有位使用LARGE_PAGE_MASK宏,等于PMD_MASK.
1
2
#define LARGE_PAGE_SIZE (1UL << PMD_SHIFT)
#define LARGE_PAGE_MASK (~(LARGE_PAGE_SIZE-1))
linux 实现大页模式有两种方式:基于 hugetlbfs 特殊文件系统与Transparent Huge Page(THP)
基于 hugetlbfs 特殊文件系统
使用 hugetlbfs 之前,首先需要在编译内核 (make menuconfig) 时配置CONFIG_HUGETLB_PAGE和CONFIG_HUGETLBFS选项,这两个选项均可在 File systems 内核配置菜单中找到。 内核编译完成并成功启动内核之后,将 hugetlbfs 特殊文件系统挂载到根文件系统的某个目录上去,以使得 hugetlbfs 可以访问。命令如下:
1
mount none /mnt/huge -t hugetlbfs
此后,只要是在 /mnt/huge/ 目录下创建的文件,将其映射到内存中时都会使用 2MB 作为分页的基本单位。值得一提的是,hugetlbfs 中的文件是不支持读 / 写系统调用 ( 如read()或write()等 ) 的,一般对它的访问都是以内存映射的形式进行的。
对于系统中大页面的统计信息可以在 Proc 特殊文件系统(/proc)中查到,如/proc/sys/vm/nr_hugepages给出了当前内核中配置的大页面的数目,也可以通过该文件配置大页面的数目,如:
1
echo 20 > /proc/sys/vm/nr_hugepages
调整系统中的大页面的数目为 20 。 例子中给出的大页面应用是简单的,而且如果仅仅是这样的应用,对应用程序来说也是没有任何用处的。在实际应用中,为了使用大页面,还需要将应用程序与库libhugetlb链接在一起。
libhugetlb库对malloc()/free()等常用的内存相关的库函数进行了重载,以使得应用程序的数据可以放置在采用大页面的内存区域中,以提高内存性能。
Transparent Huge Page
这个是RHEL 6开始引入的一个功能。THP 是一个抽象层, 可以自动创建、管理和使用传统大页的大多数方面。 THP为系统管理员和开发人员减少了很多使用传统大页的复杂性, 因为THP的目标是改进性能, 因此其它开发人员 (来自社区和红帽) 已在各种系统、配置、应用程序和负载中对 THP 进行了测试和优化
目前只适用于内存映射与共享存储方面,未来可能会扩展到其他文件系统。
查看是否启用 THP:cat /sys/kernel/mm/transparent_hugepage/enabled
当开启THP时, 对于内存映射,或者共享存储申请内存空间时, 优先分配大页内存,当由于碎片化问题导致大页不足时, 在分配常规页。
再谈 MMU
上面讲述了分段以及分页的原理细节部分,在这里再次回 MMU 工作原理上来。 当操作系统运行在保护模式时,操作系统无法直接对物理内存进行寻址,系统访问物理内存只能通过MMU来完成。
我们还可以看到在内核代码中,对于分页的若干函数里面,只有诸如页框号,页框描述符之类的辅助工具,并没有直接出现 线性地址 -> 物理地址 的转换函数。 因为这是没有意义的。
这里我们介绍下 MMU 的工作方式:
当PE(CR0的位0 - 段级保护)与PG(CR0的位31分页标志)开启时, MMU发挥作用。
MMU 通过 gdtr 与 ldtr 控制寄存器获取段表基址,来取的段表信息, 这时候与段选择符与段内偏移量与段描述符相关计算(过程参照上文)转换为线性地址。这个过程经过RPL字段权限之类的事情需要校验。
当转换为线性地址后,下一步进行线性地址到物理地址的转换.
不同的处理机分页等级是不同的:
| 处理器 | 页大小 | 寻址使用的位数 | 分页级别 | 虚拟地址分级 |
|---|---|---|---|---|
| x86 | 4KB | 32 | 2 | 10+10+12 |
| x86(extended) | 4MB | 32 | 1 | 10+22 |
| x86(PAE) | 4KB | 36 | 3 | 2+9+9+12 |
| x86(PAE ext) | 2MB | 36 | 2 | 2+9+21 |
| alpha | 8KB | 43 | 3 | 10+10+10+13 |
| ia64 | 4KB | 39 | 3 | 9+9+9+12 |
| ppc64 | 4KB | 41 | 3 | 10+10+9+12 |
| sh64 | 4KB | 41 | 3 | 10+10+9+12 |
| X86-64 | 4KB | 48 | 4 | 9+9+9+9+12 |
不同处理机MMU根据自身设计固定的拆分线性地址不同字段部分来解析页表,得到物理块号并且拼接页内偏移量部分,得到真实的物理地址(细节参照上文)。
有关 x86 中的 PAE 模式校验是通过 PAE 标识(CR4的位5)来完成。
关于大页是通过页表项中的Page Size来完成。
由于程序中使用的都是线性地址,所以程序在运行过程中会将先线性地址预先变成逻辑地址(细节后期更新),然后再去装入MMU完成取址。
参考资料:
document/深入理解linux内核中文第三版.pdf at master · saligia-eva/document · GitHub
[进程页表页和内核页表 Linux Kernel Architecture 内核笔记]
[MMU分页原理 程序园]