Spark 教程 | Spark调度流程

调度概览
我们通过 Spark RDD 原理解读 可以了解到,RDD通过依赖关系构建形成多个Stage, 每个Stage 中间通过 ShuffleDependency 作为切分点。
Job 在调度之前通过 Stage 之间的依赖关系形成了DAG拓扑图,然后基于依赖关系,从根节点向下开始出发调度 Stage。
每个 Stage 内部包含一个 RDD 信息以及相应的逻辑处理流程.
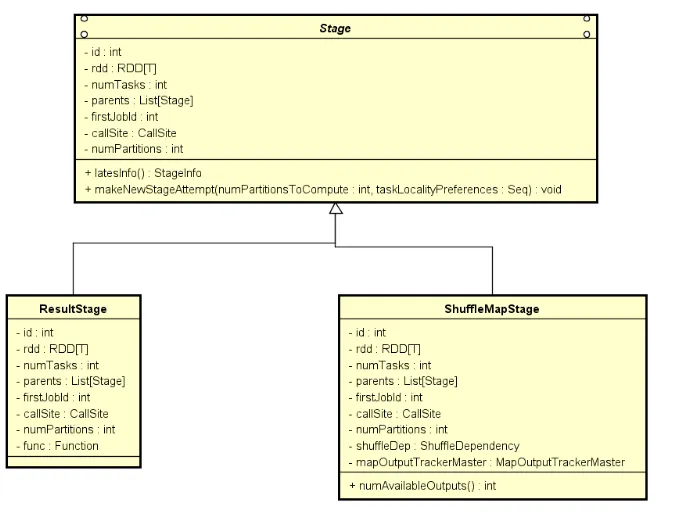
在调度执行之前,会基于 RDD 的分区数量, 将 Stage 转化为一个 Task[RddPartNum] 数组, 每个Task 用来处理一个RDD分区的数据。
Task 是任务运行的最小单元。Task[RddPartNum] 数组结构维护成 TaskSet 一起交给 TaskScheduler 调度。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
// 构建 Task 任务
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,
stage.rdd.isBarrier())
}
}
}
...
// 封装成 TaskSet 提交给 TaskScheduler
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties,
stage.resourceProfileId))
调度流程图
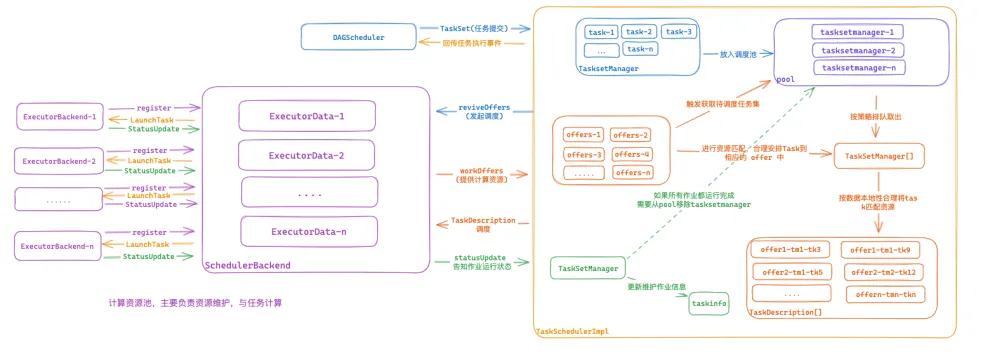
DAGScheduler基于RDD的依赖关系会将 job 切分为若干个Stage, 每个Stage维护成TaskSet集合交给TaskSchedulerImplTaskSchedulerImpl首先将TaskSet转换为TasksetManager,TasksetManager主要用来负责维护当前Task集合的任务管理与调度策略,其中包含每个任务的状态维护,基于数据本地性的调度策略,推测执行等相关功能。TaskSet转换为TasksetManager后, 会转交给Pool来维护,Pool可以维护多个TasksetManager,他基于调度算法在有计算资源时选择合适的TasksetManager去下发任务。- SchedulerBackend定期监控自己所持有的计算资源,将资源转交给
TaskSchedulerImpl, 通过Pool挑选出合适的待执行任务的TasksetManager,TasksetManager基于计算资源信息,选择合适的Task任务绑定到计算资源上, 生成TaskDescription信息传递给SchedulerBackend SchedulerBackend通过TaskDescription信息将Task序列化后通过RPC提交到指定的Executor上去执行, 并监听运行状态。
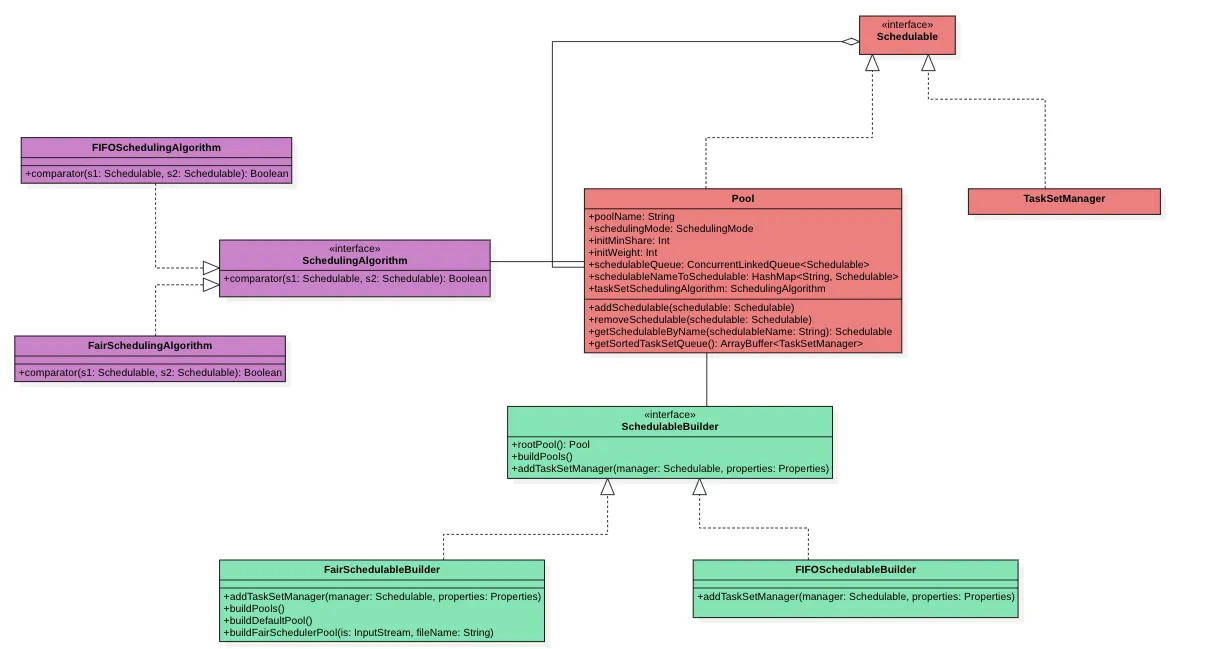
组件架构
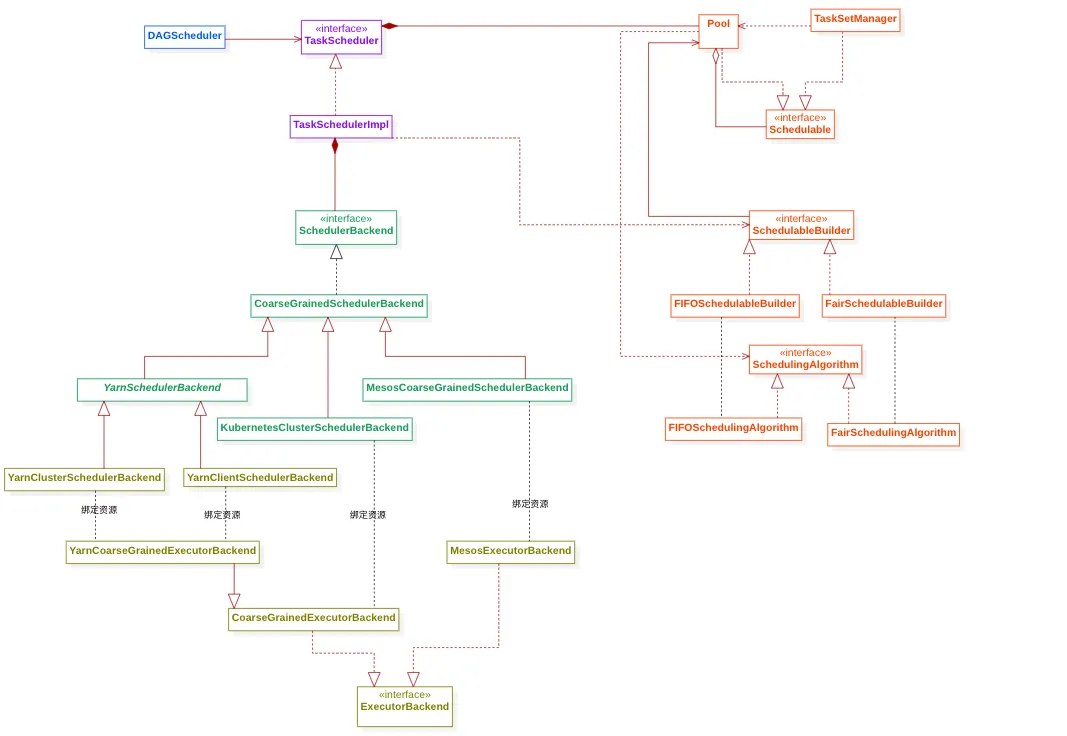
- DAGScheduler : 主要工作是用来做
Job的切分工作, 将Job切分为Stage执行拓扑图,并且按照依赖关系将Stage维护成Taskset提交给TaskSchedulerImpl - TaskSetManger :
TaskSet级别的任务管理中心,它主要用来管理Task集合的运行状态,以及当有资源时,选择合适的Task调度执行。 - Pool : 调度资源池,可以维护多个未完成的
TaskSetManager,他按照一定的算法选择合适的TaskSetManager优先调度。 - SchedulableBuilder :
Pool的构建工具,用来将TasksetManger放置到Pool池中合适的位置。 - SchedulingAlgorithm:
Pool中的TaskSetManger排序算法, 他按照一定顺序将TaskSetManger排成一个队列,前面的优先被调度。 - ScheduleBackend : 资源调度后端, 主要是用来维护当前的可用 executor 资源。 并定期触发
TaskSchedulerImpl激活调度任务。 - TaskScheduler : 任务调度的核心功能类,他借助
SchedulerBackend,Pool,TasksetManger等相关组件,完成DAGScheduler下发的调度任务。
TaskSetManager
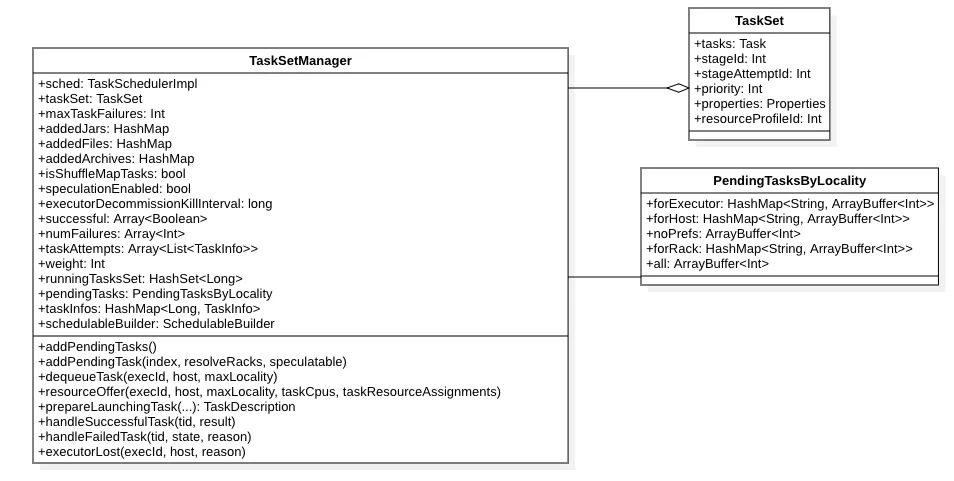
TasksetManager 主要用来负责维护当前 Task 集合的任务管理与调度策略,其中包含每个任务的状态维护,基于数据本地性的调度策略,推测执行等相关功能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
/**
* 通过找到一个任务来响应调度器提供的单个执行器资源
*
* 注意:
* 此函数要么被调用时带有 maxLocality,此值会被延迟调度算法调整,
* 要么带有特殊的 NO_PREF 本地性,此值不会被修改
*
* @param execId 提供的资源的执行器 ID
* @param host 提供的资源的主机 ID
* @param maxLocality 我们希望调度任务的最大本地性
* @param taskCpus 任务所需的 CPU 数量
* @param taskResourceAssignments 任务的资源分配
*
* @return 包含以下内容的 Triple:
* (如果有已启动的任务,返回 TaskDescription, 因延迟调度而被拒绝的资源? 被出队的任务索引)
*/
@throws[TaskNotSerializableException]
def resourceOffer(execId: String, host: String, maxLocality: TaskLocality.TaskLocality,
taskCpus: Int = sched.CPUS_PER_TASK,
taskResourceAssignments: Map[String, ResourceInformation] = Map.empty)
: (Option[TaskDescription], Boolean, Int) = {
var dequeuedTaskIndex: Option[Int] = None
// 从队列中取出一个任务来
// 注意可能会获取不到
val taskDescription = dequeueTask(execId, host, allowedLocality)
.map {
case (index, taskLocality, speculative) =>
dequeuedTaskIndex = Some(index)
// 如果获取成功。则当前任务做运行前准备
prepareLaunchingTask(
execId,
host,
index,
taskLocality,
speculative,
taskCpus,
taskResourceAssignments,
curTime)
}
val hasPendingTasks = pendingTasks.all.nonEmpty || pendingSpeculatableTasks.all.nonEmpty
// 是否有延迟调度
val hasScheduleDelayReject = taskDescription.isEmpty && maxLocality == TaskLocality.ANY && hasPendingTasks
(taskDescription, hasScheduleDelayReject, dequeuedTaskIndex.getOrElse(-1))
} else {
(None, false, -1)
}
}
数据本地性调度策略
TaskSetManager初始化时,通过addPendingTask将task按照本地性优先级,多层维护起任务信息- 每次获得计算资源后,
dequeueTaskHelper基于本地性优先级依次来调度,选择一个合适的作业上去执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
private[spark] def addPendingTask(
taskId: Int,
resolveRacks: Boolean = true,
speculatable: Boolean = false): Unit = {
..
// 获取数据本地性
for (loc <- tasks(taskId).preferredLocations) {
// STEP-1 : 进程本地性维护
loc match {
// 进程本地化
case e: ExecutorCacheTaskLocation =>
pendingTaskSetToAddTo.forExecutor.getOrElseUpdate(e.executorId, new ArrayBuffer) += index
case e: HDFSCacheTaskLocation =>
pendingTaskSetToAddTo.forExecutor.getOrElseUpdate(e, new ArrayBuffer) += index
case _ =>
}
// STEP-2 : 节点本地性维护
pendingTaskSetToAddTo.forHost.getOrElseUpdate(loc.host, new ArrayBuffer) += index
// STEP-3 : 机架本地性维护
if (resolveRacks) {
sched.getRackForHost(loc.host).foreach { rack =>
pendingTaskSetToAddTo.forRack.getOrElseUpdate(rack, new ArrayBuffer) += index
}
}
}
// STEP-4 : 无本地偏好性维护
if (tasks(index).preferredLocations == Nil) {
pendingTaskSetToAddTo.noPrefs += index
}
// STEP-5 : 在所有待处理任务集合上单独维护
pendingTaskSetToAddTo.all += index
}
protected def dequeueTaskHelper(
execId: String, // 资源节点
host: String,
maxLocality: TaskLocality.Value,
speculative: Boolean): Option[(Int, TaskLocality.Value, Boolean)] = {
// STEP-1 : 基于进程本地性挑选任务
dequeue(pendingTaskSetToUse.forExecutor.getOrElse(execId, ArrayBuffer())).foreach { index =>
return Some((index, TaskLocality.PROCESS_LOCAL, speculative))
}
// STEP-2 : 基于节点本地性挑选任务
if (TaskLocality.isAllowed(maxLocality, TaskLocality.NODE_LOCAL)) {
dequeue(pendingTaskSetToUse.forHost.getOrElse(host, ArrayBuffer())).foreach { index =>
return Some((index, TaskLocality.NODE_LOCAL, speculative))
}
}
// STEP-3 : 基于数据无偏好性选任务
if (TaskLocality.isAllowed(maxLocality, TaskLocality.NO_PREF)) {
dequeue(pendingTaskSetToUse.noPrefs).foreach { index =>
return Some((index, TaskLocality.PROCESS_LOCAL, speculative))
}
}
// STEP-4 : 基于数据本地机架选任务
if (TaskLocality.isAllowed(maxLocality, TaskLocality.RACK_LOCAL)) {
for {
rack <- sched.getRackForHost(host)
index <- dequeue(pendingTaskSetToUse.forRack.getOrElse(rack, ArrayBuffer()))
} {
return Some((index, TaskLocality.RACK_LOCAL, speculative))
}
}
// STEP-5 : 改节点在以上本地性都不满足后,任意调起一个任务执行
if (TaskLocality.isAllowed(maxLocality, TaskLocality.ANY)) {
dequeue(pendingTaskSetToUse.all).foreach { index =>
return Some((index, TaskLocality.ANY, speculative))
}
}
None
}
推测执行逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
/**
* 检查与给定 tid 关联的任务是否已超过时间阈值,并且是否应该进行推测性运行。
*/
private def checkAndSubmitSpeculatableTask(tid: Long, currentTimeMillis: Long, threshold: Double): Boolean = {
val info = taskInfos(tid)
val index = info.index
// 当前任务正在运行
// 当前任务的运行时间超过了已完成任务平均时间的 threshold 倍
if (!successful(index) && copiesRunning(index) == 1 &&
info.timeRunning(currentTimeMillis) > threshold && !speculatableTasks.contains(index)) {
addPendingTask(index, speculatable = true)
speculatableTasks += index
sched.dagScheduler.speculativeTaskSubmitted(tasks(index))
true
} else {
false
}
}
Pool
Pool 的主要功能是用来维护当前所有需要运行的 TaskSetManager 集合;并且当空闲计算资源时, 他通过 SchedulingAlgorithm 算法策略来对所有 TaskSetManager 进行排序,并有序调度相关的 TaskSetManager 。
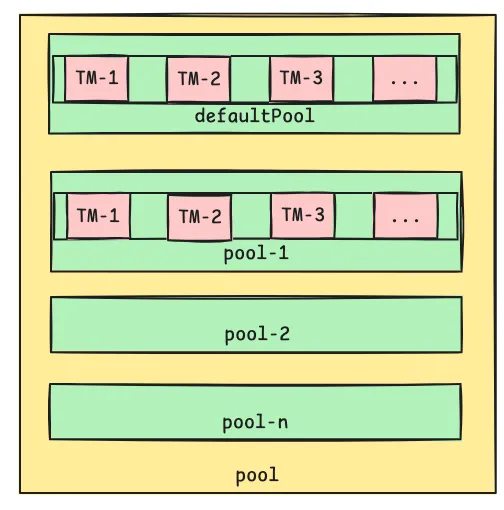
Pool 使用 SchedulableBuilder 来维护 TasksetManager 集合,他主要有两种策略 :
Pool构建策略
FIFOSchedulableBuilder
FairSchedulableBuilder 简单地将TaskSetManager按照先来先到的方式入队处理
FairSchedulableBuilder
FAIR模式中有一个rootPool和多个子Pool,各个子Pool中存储着所有待分配的TaskSetMagager。
TaskSetManager 排序策略
FIFOSchedulingAlgorithm
1
2
3
4
5
6
7
8
9
10
11
12
// 按照优先级排序,如果优先级相同,则按照stageId排序
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val priority1 = s1.priority
val priority2 = s2.priority
var res = math.signum(priority1 - priority2)
if (res == 0) {
val stageId1 = s1.stageId
val stageId2 = s2.stageId
res = math.signum(stageId1 - stageId2)
}
res < 0
}
FairSchedulingAlgorithm
比较时会综合考量runningTasks值,minShare(最小共享)值以及weight值。
注意, minShare 、 weight 的值均在公平调度配置文件fairscheduler.xml中被指定,调度池在构建阶段会读取此文件的相关配置。
1) 如果A对象的runningTasks大于它的minShare,B对象的runningTasks小于它的minShare,那么B排在A前面;(runningTasks比minShare小的先执行) 比如A中10个任务有8个在执行,B中10个任务有2个中执行,就把B放前边先执行;
2) 如果A、B对象的runningTasks都小于它们的minShare,那么就比较runningTasks与minShare的比值(minShare使用率),谁小谁排前面;(minShare使用率低的先执行)
比如A中有100个任务有4个在执行,占1/25;B中有2个任务只有1个在执行,占1/2,A排在前边;
3) 如果A、B对象的runningTasks都大于它们的minShare,那么就比较runningTasks与weight的比值(权重使用率),谁小谁排前面。(权重使用率低的先执行)
4) 如果上述比较均相等,则比较名字。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val minShare1 = s1.minShare
val minShare2 = s2.minShare
val runningTasks1 = s1.runningTasks
val runningTasks2 = s2.runningTasks
val s1Needy = runningTasks1 < minShare1
val s2Needy = runningTasks2 < minShare2
val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0)
val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0)
val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble
val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble
var compare = 0
if (s1Needy && !s2Needy) {
return true
} else if (!s1Needy && s2Needy) {
return false
} else if (s1Needy && s2Needy) {
compare = minShareRatio1.compareTo(minShareRatio2)
} else {
compare = taskToWeightRatio1.compareTo(taskToWeightRatio2)
}
if (compare < 0) {
true
} else if (compare > 0) {
false
} else {
s1.name < s2.name
}
}
SchedulerBackend
SchedulerBackend 作为资源调度管理后端,主要用来维护当前的计算节点数,他接受来自 ExecutorBackend 的 Executor 注册信息, 将 Executor 统一管理,并分配给 TaskScheduler, 去执行计算任务。 同时他跟 ExecutorBackend 交互, 负责任务提交功能。
Executor 注册通知流程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
protected val addressToExecutorId = new HashMap[RpcAddress, String]
protected val totalCoreCount = new AtomicInteger(0) // 使用原子变量跟踪集群中的总核心数,以简化操作并提高速度。
private val executorDataMap = new HashMap[String, ExecutorData] // 保存当前存活的所有的 Executor
// Executor 注册事件
case RegisterExecutor(executorId, executorRef, hostname, cores, logUrls,
attributes, resources, resourceProfileId) =>
..
// Executor 地址
val executorAddress = executorRef.address
addressToExecutorId(executorAddress) = executorId // 记录地址映射关系
totalCoreCount.addAndGet(cores) // 记录总的core数量
totalRegisteredExecutors.addAndGet(1)
// 统计 Executor 资源信息
val resourcesInfo = resources.map { case (rName, info) =>
// 告诉 Executor 它可以根据用户配置最多调度 numSlotsPerAddress 次资源,
// 或者设置为默认值 1(1 个任务/资源)。
val numParts = scheduler.sc.resourceProfileManager
.resourceProfileFromId(resourceProfileId)
.getNumSlotsPerAddress(rName, conf)
(info.name, new ExecutorResourceInfo(info.name, info.addresses, numParts))
}
// executor 相关信息维护
val data = new ExecutorData(executorRef, executorAddress, hostname,
0, cores, logUrlHandler.applyPattern(logUrls, attributes), attributes,
resourcesInfo, resourceProfileId, registrationTs = System.currentTimeMillis())
// 这必须是同步的,因为在此代码块中变更的变量会在请求执行器时被读取。
CoarseGrainedSchedulerBackend.this.synchronized {
executorDataMap.put(executorId, data) // 记录映射关系
}
// Executor 新增事件
listenerBus.post(SparkListenerExecutorAdded(System.currentTimeMillis(), executorId, data))
context.reply(true)
}
触发任务绑定计算资源
SchedulerBackend 定期扫描空闲的executor, 并转交给 TaskSchdulerImpl
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
// CoarseGrainedSchedulerBackend
class DriverEndpoint extends IsolatedRpcEndpoint with Logging {
override def onStart(): Unit = {
// 定期重新激活任务提供,以使延迟调度生效。
// 默认 一秒
val reviveIntervalMs = conf.get(SCHEDULER_REVIVE_INTERVAL).getOrElse(1000L)
reviveThread.scheduleAtFixedRate(() => Utils.tryLogNonFatalError {
Option(self).foreach(_.send(ReviveOffers))
}, 0, reviveIntervalMs, TimeUnit.MILLISECONDS)
}
override def receive: PartialFunction[Any, Unit] = {
// 接受 ReviveOffers 事件
case ReviveOffers =>
makeOffers()
}
// 每秒调用一次
private def makeOffers(): Unit = {
// 触发资源调度, 从 TaskScheduler 中绑定任务执行, 返回绑定的任务描述信息
val taskDescs = withLock {
// 过滤出所有Active的Executor
val activeExecutors = executorDataMap.filterKeys(isExecutorActive)
// 计算每个 executor 的可用资源
val workOffers = activeExecutors.map {
case (id, executorData) =>
new WorkerOffer(id,
executorData.executorHost,
executorData.freeCores,
Some(executorData.executorAddress.hostPort),
executorData.resourcesInfo.map { case (rName, rInfo) =>
(rName, rInfo.availableAddrs.toBuffer)
},
executorData.resourceProfileId)
}.toIndexedSeq
scheduler.resourceOffers(workOffers, true)
}
// 如果有需要提交的任务, 则提交执行
if (taskDescs.nonEmpty) {
launchTasks(taskDescs)
}
}
}
提交计算任务
通过RPC 通信,将 TaskScheduler 提交过来的任务集合分配给对应的 Executor 执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
private def launchTasks(tasks: Seq[Seq[TaskDescription]]): Unit = {
for (task <- tasks.flatten) {
val serializedTask = TaskDescription.encode(task)
if (serializedTask.limit() >= maxRpcMessageSize) { // 序列化数据过大,失败报错处理 }
else {
val executorData = executorDataMap(task.executorId) //
val rpId = executorData.resourceProfileId
val prof = scheduler.sc.resourceProfileManager.resourceProfileFromId(rpId)
val taskCpus = ResourceProfile.getTaskCpusOrDefaultForProfile(prof, conf)
// 绑定资源
executorData.freeCores -= taskCpus
task.resources.foreach { case (rName, rInfo) =>
assert(executorData.resourcesInfo.contains(rName))
executorData.resourcesInfo(rName).acquire(rInfo.addresses)
}
// 提交作业执行
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}