Spark 教程 | Spark RDD 原理解读

RDD 介绍
我们提出了弹性分布式数据集(RDDs),这是一种分布式内存抽象,使程序员能够在大型集群上以容错的方式执行内存计算。
RDDs的动机来自于两种类型的应用,这些应用在当前的计算框架中处理效率低下:迭代算法和交互式数据挖掘工具。在这两种情况下,将数据保留在内存中可以将性能提高一个数量级。
为了实现高效的容错性,RDDs提供了一种受限的共享内存形式,基于粗粒度的转换,而不是对共享状态的细粒度更新。然而,我们表明RDDs具有足够的表达能力,可以捕捉各种计算,包括用于迭代作业的最近专门的编程模型(如Pregel),以及这些模型无法捕捉的新应用。
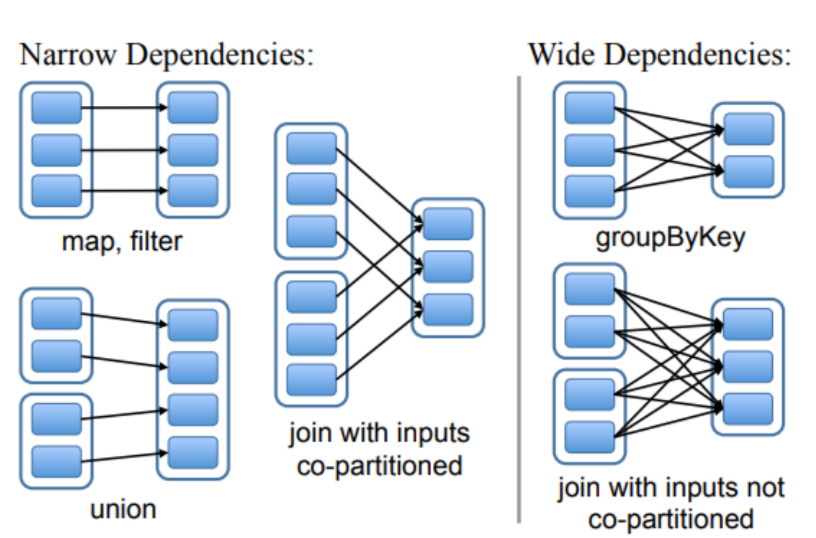
在提供RDDs作为一种抽象的过程中,面临的一个挑战是选择一个可以在广泛的Transform中跟踪血缘依赖的表示方法。
理想情况下,实现RDDs的系统应该提供尽可能丰富的转换操作符,并允许用户以任意方式组合它们。我们提出了一种基于DAG图的简单RDD表示,以实现这些目标。在Spark中,我们使用了这种表示方法,支持了广泛的Transform,而无需为每个Transform在调度程序中添加特殊逻辑,这极大地简化了系统设计。
RDD 的构造函数为 :
1
2
3
4
5
6
7
8
abstract class RDD[T: ClassTag](
@transient private var _sc: SparkContext, // SparkContext
@transient private var deps: Seq[Dependency[_]] // RDD 的依赖关系
) extends Serializable with Logging
// 构建跟上游RDD一对一依赖的RDD。
def this(@transient oneParent: RDD[_]) =
this(oneParent.context, List(new OneToOneDependency(oneParent)))
除此之外, RDD通过一些公共的接口来表示每个RDD,该接口公开了五个信息:
1. partitions() 一组分区,这些分区是数据集的原子片段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 获取此RDD的分区数组,考虑到RDD是否被checkpoint。
final def partitions: Array[Partition] = {
checkpointRDD.map(_.partitions).getOrElse { // 如果数据已经被checkpoint, 则从checkpointRDD 中返回分区
if (partitions_ == null) {
partitions_ = getPartitions // 从具体RDD实现的getPartitions方法中获取分区列表
partitions_.zipWithIndex.foreach { case (partition, index) =>
require(partition.index == index,
s"partitions($index).partition == ${partition.index}, but it should equal $index")
}
}
partitions_
}
}
2. dependencies()一组对父RDD的依赖关系
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 返回构建过程中传递的RDD依赖关系
protected def getDependencies: Seq[Dependency[_]] = deps
// 获取此RDD的依赖列表,要考虑此RDD是否被Checkpoint
final def dependencies: Seq[Dependency[_]] = {
// 如果已经被 checkpoint 了, 则直接返回checkpointRDD
checkpointRDD.map(r => List(new OneToOneDependency(r)))
.getOrElse {
if (dependencies_ == null) {
dependencies_ = getDependencies // 通过getDependencies 获取通过构造函数传递的依赖关系
}
dependencies_
}
}
3. iterator(p, parentIters)一个用于基于其父数据集计算数据集的函数
RDD 的计算入口, 这里需要注意的是,返回的Iterator对象是惰性的, 在调用next时才真正触发计算
4. partitioner()RDD的分区方案其分区方案
1
2
// 可选地由子类覆盖,以指定它们的分区方式
@transient val partitioner: Option[Partitioner] = None
5. 数据放置的位置偏好
1
2
3
4
5
6
7
8
// 可选地由子类覆盖,以指定当前Partition的位置偏好
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
// 获取分区的首选位置,考虑到RDD是否被检查点。
final def preferredLocations(split: Partition): Seq[String] = {
checkpointRDD.map(_.getPreferredLocations(split)).getOrElse {
getPreferredLocations(split)
}
}
RDD 的执行逻辑介绍
RDD 的计算入口为 : def iterator(split: Partition, context: TaskContext): Iterator[T]
它基于指定的 Partition 来返回对应的分区数据迭代器 Iterator[T], 不过通常情况下迭代器中并没有保存当前分区的所有数据, 它是一个懒加载的计算过程,当触发next()方法时,才真正从源头计算并返回数据。
详情可以参考类似 HadoopRDD 等相关实现
itrator 方法的计算逻辑如图 :

- 它首先判断 RDD 的存储 level 是否是
None, 这是一个缓存属性,如果RDD调用过cache过以后,它的存储level会非None. 如果当前的RDD 没有调用过cache, 则调用
computeOrReadCheckpoint方法, 从上游计算,或者是从checkpoint读取i. 通过
isCheckpointedAndMaterialized判断是否checkpoint 中有数据, 如果有数据,则dependences 将指向CheckpointRDD, 此时直接从checkpointRDD读取出数据即可。ii. 如果没有checkpoint, 则调用
compute从上游直接计算出当前分区数据- 如果当前 RDD 调用过
cache, 则从BlockManager中尝试读取 chache 数据, 如果 BlockManager 中存在Cache数据,则直接返回。否则,则调用computeOrReadCheckpoint先计算并放入cache中,然后在返回。
RDD 的常用算子介绍
MapPartitionsRDD
1
2
3
4
5
6
7
8
9
10
11
12
13
14
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
var prev: RDD[T], // 上游依赖RDD
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // 基于上游依赖RDD的算子转换实现 -- OneToOneDependency
preservesPartitioning: Boolean = false,
isFromBarrier: Boolean = false,
isOrderSensitive: Boolean = false)
extends RDD[U](prev) {
override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else None // 定义分区器
override def getPartitions: Array[Partition] = firstParent[T].partitions // 继承自上游的分区
override def compute(split: Partition, context: TaskContext): Iterator[U] = // 具体计算转换实现
f(context, split.index, firstParent[T].iterator(split, context))
}
需要注意的是 :
MapPartitionsRDD 的依赖是一个 OneToOneDependency
map(f: A=>B)
元素转换算子
实现原理
1
2
3
4
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
使用案例
1
2
val test: RDD[Int] = sc.makeRDD(1 to 10)
val mapRDD: RDD[Int] = test.map(_*2)
mapPartitions(f: Iterator[T]=>Iterator[U])
类似与map,但它独立对每一个分区数据进行处理
实现原理
1
2
3
4
5
6
7
8
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(iter), // 直接将迭代器传递给函数
preservesPartitioning)
}
使用案例
1
2
3
val test: RDD[Int] = sc.makeRDD(1 to 10,2)
//map被调用了10次,mapPartitions被调用了2次
val mapPartitionsRDD: RDD[Int] = test.mapPartitions(_.map(_*2))
mapPartitionsWithIndex(f: Iterator[T]=>Iterator[U])
类似于mapPartitions,但它多了一个分区的索引值。
实现原理
1
2
3
4
5
6
7
8
9
10
// mapPartitionsWithIndex 算子
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(index, iter),
preservesPartitioning)
}
使用案例
1
2
3
4
5
6
val test: RDD[Int] = sc.makeRDD(1 to 8,2)
val mapPartitionsIndex: RDD[(Int, String)] = test.mapPartitionsWithIndex {
case (num, x) => {
x.map((_,"分区"+num))
}
}
flatMap(f: T=>TraversableOnce[U])
扁平化处理集合,类似与map处理,不过对返回的集合做展开操作
实现原理
1
2
3
4
5
// FlatMap 算子
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))
}
使用案例
1
2
3
4
val test2: RDD[List[Int]] = sc.makeRDD(Array(List(1,2,3),List(4,5,6)))
val flatmapRDD: RDD[Int] = test2.flatMap(datas => datas) //接收一个集合,返回一个集合
flatmapRDD.collect().foreach(println)
// 返回值:Array(1,2,3,4,5,6)
filter( f: T=>Boolean)
对数据进行过滤。满足的留下,不满足的过滤掉。
实现原理
1
2
3
4
5
6
7
8
// Filter 算子
def filter(f: T => Boolean): RDD[T] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[T, T](
this,
(context, pid, iter) => iter.filter(cleanF),
preservesPartitioning = true)
}
使用案例
1
2
val list: RDD[Int] = sc.makeRDD(List(1,2,3,4))
val filterRDD: RDD[Int] = list.filter( x => x%2==0) //按照2的整数倍进行过滤
ShuffledRDD
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class ShuffledRDD[K: ClassTag, V: ClassTag, C: ClassTag](
@transient var prev: RDD[_ <: Product2[K, V]], // 上游依赖的 RDD
part: Partitioner) // 分区器
extends RDD[(K, C)](prev.context, Nil) { // Pre Dependency 设置为NULL
private var userSpecifiedSerializer: Option[Serializer] = None // 自定义序列化器
private var keyOrdering: Option[Ordering[K]] = None // key 排序器
private var aggregator: Option[Aggregator[K, V, C]] = None // 聚合器
private var mapSideCombine: Boolean = false // 是否进行 MapCombine
// 定义 ShuffleDependency 依赖
override def getDependencies: Seq[Dependency[_]] = {
List(new ShuffleDependency(prev, part, serializer, keyOrdering, aggregator, mapSideCombine))
}
override val partitioner = Some(part)
// 自定义分区器
override def getPartitions: Array[Partition] = {
Array.tabulate[Partition](part.numPartitions)(i => new ShuffledRDDPartition(i))
}
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
// 从ShuffleManager 中将对应的分区数据读出来
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
}
}
需要注意的是 :
ShuffledRDD 的依赖是一个 ShuffleDependency
groupBy(f: T=>K): RDD[(K, Iterable[T])]
对数据进行分组。按照传入函数返回值进行分组,分组数据为元组 k-v,k表示索引值,v表示分组数据集合
实现原理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
def groupBy[K](f: T => K,
p: Partitioner) // 分区器,默认是 HashPartition
(implicit kt: ClassTag[K], ord: Ordering[K] = null) : RDD[(K, Iterable[T])] = withScope {
val cleanF = sc.clean(f)
this.map(t => (cleanF(t), t)) // 进行Map操作, 提取Key
.groupByKey(p) // 加入分区器进行分区操作
}
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope {
// 定义Combine操作
val createCombiner = (v: V) => CompactBuffer(v) // 初始化compine空集
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v // combine 内部处理处理方式
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2 // combine 之间的数据处理方式
val bufs = combineByKeyWithClassTag[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false) // 设置不应该进行 Combine
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
}
def combineByKeyWithClassTag[C](
createCombiner: V => C, // Combine 初始化
mergeValue: (C, V) => C, // Combine 内部数据合并
mergeCombiners: (C, C) => C, // Combine 之间的数据合并
partitioner: Partitioner, // 分区器
mapSideCombine: Boolean = true, // 是否进行 MapCombine 操作
serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope {
// 用于聚合操作的算子类
val aggregator = new Aggregator[K, V, C](
self.context.clean(createCombiner),
self.context.clean(mergeValue),
self.context.clean(mergeCombiners))
// 表示不改变分区结构,只做combine操作
if (self.partitioner == Some(partitioner)) {
self.mapPartitions(iter => {
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context)) /
}, preservesPartitioning = true)
} else {
// 跨shuffle的聚合操作
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}
}
实现案例
1
2
3
4
val list: RDD[Int] = sc.makeRDD(List(1,2,3,4))
val groupbyRDD: RDD[(Int, Iterable[Int])] = list.groupBy( x => x%2) //按照2的整数倍进行分组
groupbyRDD.collect().foreach(println)
// Array((0,CompactBuffer(2, 4),(1,CompactBuffer(1, 3))
sortBy(f:(T)=>K, ascending:Boolean=true)
对数据进行排序。按照函数返回值不同的规则进行排序
实现原理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def sortBy[K](
f: (T) => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] = withScope {
this.keyBy[K](f)
.sortByKey(ascending, numPartitions)
.values
}
def keyBy[K](f: T => K): RDD[(K, T)] = withScope {
val cleanedF = sc.clean(f)
map(x => (cleanedF(x), x))
}
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)] = self.withScope {
// 使用rangePartitioner
val part = new RangePartitioner(numPartitions, self, ascending)
new ShuffledRDD[K, V, V](self, part)
.setKeyOrdering(if (ascending) ordering else ordering.reverse)
}
使用案例
1
2
3
4
val list: RDD[Int] = sc.makeRDD(List(2,3,5,1,6,7))
val sortByRDD: RDD[Int] = list.sortBy( x => x)
sortByRDD.collect().foreach(println)
// Array(1,2,3,5,6,7)
partitionBy(partitioner: Partitioner)
对RDD进行重分区操作
实现原理
1
2
3
4
5
6
7
8
9
10
def partitionBy(partitioner: Partitioner): RDD[(K, V)] = self.withScope {
if (keyClass.isArray && partitioner.isInstanceOf[HashPartitioner]) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
if (self.partitioner == Some(partitioner)) {
self
} else {
new ShuffledRDD[K, V, V](self, partitioner)
}
}
使用案例
1
2
val list1: RDD[(String, Int)] = sc.makeRDD(List(("aaa",1),("bbb",2),("bbb",3)))
val partitionByRDD: RDD[(String, Int)] = list1.partitionBy(new HashPartitioner(2))
groupByKey()
对每个key进行操作,把相同的key的value放到一个集合当中
实现原理参照 groupBy算子
使用案例
1
2
val list1: RDD[String] = sc.makeRDD(List("A","A","B","A","C","B","C"))
val groupByKeyRDD: RDD[(String, Iterable[Int])] = list1.map( x => (x,1)).groupByKey()
reduceByKey(func:(V, V) => V): RDD[(K, V)]
将相同key的值聚合到一起,合并计算Value
实现原理
1
2
3
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
}
应用案例
1
2
3
val list1: RDD[String] = sc.makeRDD(List("A","A","B","A","C","B","C"))
val mapRDD: RDD[(String, Int)] = list1.map(x => (x,1))
val reduceByKey: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
aggregateByKey(zeroValue: U)(seqOp: (U, V) => U,combOp: (U, U) => U): RDD[(K, U)]
先进行每个分区内的计算,然后再进行分区与分区之间的计算。
- zeroValue:初始值
- seqOp:函数用于在每一个分区中用初始值逐步迭代value
- combOp:函数用于合并每个分区中的结果
实现原理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)] = self.withScope {
// 创建初始值
val zeroBuffer = SparkEnv.get.serializer.newInstance().serialize(zeroValue)
val zeroArray = new Array[Byte](zeroBuffer.limit)
zeroBuffer.get(zeroArray)
lazy val cachedSerializer = SparkEnv.get.serializer.newInstance()
// 初始值
val createZero = () => cachedSerializer.deserialize[U](ByteBuffer.wrap(zeroArray))
// combine 计算
val cleanedSeqOp = self.context.clean(seqOp)
combineByKeyWithClassTag[U]((v: V) => cleanedSeqOp(createZero(), v),
cleanedSeqOp, combOp, partitioner)
}
应用案例
1
2
3
4
val list1: RDD[(String, Int)] = sc.makeRDD(List(("a",3),("a",2),("c",4),("b",3),("c",6),("c",8)),2)
val aggregateByKeyRDD: RDD[(String, Int)] = list1.aggregateByKey(0)(math.max(_,_),_+_) //取每个分区不同key的最大值,每个分区的key最大值进行相加
aggregateByKeyRDD.collect().foreach(println)
// Array((b,3),(a,3),(c,12))
CoGroupedRDD
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
class CoGroupedRDD[K: ClassTag](
@transient var rdds: Seq[RDD[_ <: Product2[K, _]]], // 上游依赖的多个RDD
part: Partitioner) // 分区器
extends RDD[(K, Array[Iterable[_]])](rdds.head.context, Nil) {
// 获取上游依赖的 RDD
override def getDependencies: Seq[Dependency[_]] = {
rdds.map { rdd: RDD[_] =>
if (rdd.partitioner == Some(part)) {
new OneToOneDependency(rdd)
} else {
new ShuffleDependency[K, Any, CoGroupCombiner](rdd.asInstanceOf[RDD[_ <: Product2[K, _]]], part, serializer)
}
}
}
// 自定义分区函数
override def getPartitions: Array[Partition] = {
val array = new Array[Partition](part.numPartitions)
// 当前RDD 的每个分区,依赖自上游所有RDD的对应分区数据
for (i <- 0 until array.length) {
array(i) = new CoGroupPartition(i,rdds.zipWithIndex.map { case (rdd, j) =>
dependencies(j) match {
// Shuffle 依赖无需记录,需要从ShuffleManager中读取
case s: ShuffleDependency[_, _, _] => None
case _ => Some(new NarrowCoGroupSplitDep(rdd, i, rdd.partitions(i)))
}
}.toArray)
}
array
}
// 计算当前分区数据
override def compute(s: Partition, context: TaskContext): Iterator[(K, Array[Iterable[_]])] = {
val split = s.asInstanceOf[CoGroupPartition]
val numRdds = dependencies.length
// 存放结果数据集
val rddIterators = new ArrayBuffer[(Iterator[Product2[K, Any]], Int)]
// 获取所有依赖的RDD,获取每个RDD的当前分区的数据
for ((dep, depNum) <- dependencies.zipWithIndex) dep match {
case oneToOneDependency: OneToOneDependency[Product2[K, Any]] @unchecked =>
val dependencyPartition = split.narrowDeps(depNum).get.split
val it = oneToOneDependency.rdd.iterator(dependencyPartition, context)
rddIterators += ((it, depNum))
case shuffleDependency: ShuffleDependency[_, _, _] =>
// Read map outputs of shuffle
val it = SparkEnv.get.shuffleManager
.getReader(shuffleDependency.shuffleHandle, split.index, split.index + 1, context)
.read()
rddIterators += ((it, depNum))
}
val map = createExternalMap(numRdds)
// 合并当前分区数据, 如果key 相同, 则内容追加到depNum对应的迭代器中
for ((it, depNum) <- rddIterators) {
map.insertAll(it.map(pair => (pair._1, new CoGroupValue(pair._2, depNum))))
}
new InterruptibleIterator(context,
map.iterator.asInstanceOf[Iterator[(K, Array[Iterable[_]])]])
}
}
cogroup(other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]
将两个RDD 进行Key关联
实现原理
1
2
3
4
5
6
7
8
9
10
11
12
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))] = self.withScope {
cogroup(other, defaultPartitioner(self, other))
}
def cogroup[W](other: RDD[(K, W)], partitioner: Partitioner)
: RDD[(K, (Iterable[V], Iterable[W]))] = self.withScope {
val cg = new CoGroupedRDD[K](Seq(self, other), partitioner)
cg.mapValues { case Array(vs, w1s) =>
(vs.asInstanceOf[Iterable[V]], w1s.asInstanceOf[Iterable[W]])
}
}
使用案例
1
2
3
4
5
val list1: RDD[(String, Int)] = sc.makeRDD(List(("A",1),("B",2),("C",3)))
val list2: RDD[(String, String)] = sc.makeRDD(List(("A","a"),("B","b"),("C","c")))
val cogroupRDD: RDD[(String, (Iterable[Int], Iterable[String]))] = list1.cogroup(list2)
cogroupRDD.collect().foreach(println)
// Array((A,(CompactBuffer(1),CompactBuffer(a))),(B,(CompactBuffer(2),CompactBuffer(b))),(C,(CompactBuffer(3),CompactBuffer(c))))
join(other: RDD[(K, W)]): RDD[(K, (V, W))]
实现原理
1
2
3
4
5
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))] = self.withScope {
this.cogroup(other, partitioner).flatMapValues( pair =>
for (v <- pair._1.iterator; w <- pair._2.iterator) yield (v, w)
)
}
使用案例
1
2
3
4
5
val list1: RDD[(String, Int)] = sc.makeRDD(List(("A",1),("B",2),("C",3)))
val list2: RDD[(String, String)] = sc.makeRDD(List(("A","a"),("B","b"),("C","c")))
val joinRDD: RDD[(String, (Int, String))] = list1.join(list2)
joinRDD.collect().foreach(println)
// Array((A,(1,a)),(B,(2,b)),(C,(3,c)))
CoalescedRDD
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
/**
* 表示一个分区较少的合并RDD,其分区数少于其父RDD。
* 该类使用PartitionCoalescer类来找到父RDD的良好分区方式,以便每个新分区大致具有相同数量的父分区,
* 并且每个新分区的首选位置与其父分区的尽可能多的首选位置重叠。
*
* @param prev RDD 用于重分区的RDD
* @param maxPartitions 分区后的最大分区数量
* @param partitionCoalescer [[PartitionCoalescer]] 用于合并分区的实现方式
*/
private[spark] class CoalescedRDD[T: ClassTag](
@transient var prev: RDD[T],
maxPartitions: Int,
partitionCoalescer: Option[PartitionCoalescer] = None)
extends RDD[T](prev.context, Nil) { // Nil since we implement getDependencies
// 定义分区
override def getPartitions: Array[Partition] = {
// 创建一个默认的分区实现器
val pc = partitionCoalescer.getOrElse(new DefaultPartitionCoalescer())
// 分区器计算,每个分区包含多个目标分区的数据
pc.coalesce(maxPartitions, prev).zipWithIndex.map {
case (pg, i) =>
// 拿到计算后的每个分区组
val ids = pg.partitions.map(_.index).toArray
new CoalescedRDDPartition(i, prev, ids, pg.prefLoc)
}
}
override def compute(partition: Partition, context: TaskContext): Iterator[T] = {
// 顺序迭代上游算子
partition.asInstanceOf[CoalescedRDDPartition].parents.iterator.flatMap { parentPartition =>
firstParent[T].iterator(parentPartition, context)
}
}
override def getDependencies: Seq[Dependency[_]] = {
Seq(new NarrowDependency(prev) {
def getParents(id: Int): Seq[Int] = {
// 基于当前分区号获取到多个上游分区依赖号
partitions(id).asInstanceOf[CoalescedRDDPartition].parentsIndices
}
})
}
}
coalesce(numPartitions:Int, shuffle:Boolean = false)
缩减分区,用于大数据集过滤后,提高小数据集的执行效率。
实现原理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
: RDD[T] = withScope {
if (shuffle) {
// 从一个随机分区开始,均匀地将元素分布到输出分区。
val distributePartition = (index: Int, items: Iterator[T]) => {
var position = new Random(hashing.byteswap32(index)).nextInt(numPartitions)
items.map { t =>
// 需要注意的是,键的哈希码将直接是键本身。HashPartitioner 将使用总分区数对其进行取模操作。
position = position + 1
(position, t)
}
} : Iterator[(Int, T)]
new CoalescedRDD( // 套一层 CoalescedRDD
new ShuffledRDD[Int, T, T]( // 构建ShuffleRDD
mapPartitionsWithIndexInternal(distributePartition, isOrderSensitive = true), // 增肌随机偏移
new HashPartitioner(numPartitions)), // 使用的 HashPartitioner 进行分区
numPartitions,
partitionCoalescer).values
} else {
new CoalescedRDD(this, numPartitions, partitionCoalescer)
}
}
应用案例
1
2
val list: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6),3)
val coalesceRDD: RDD[Int] = list.coalesce(2)
repartition(numPartitions:Int)
对数据重新分区,重新洗牌所有数据
实现原理
1
2
3
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
应用案例
1
2
val list: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6),3)
val repartitionRDD: RDD[Int] = list.repartition(2)
UnionRDD
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
@DeveloperApi
class UnionRDD[T: ClassTag](
sc: SparkContext, //
var rdds: Seq[RDD[T]]) // 上游依赖的 RDD 数据集
extends RDD[T](sc, Nil) { // Nil since we implement getDependencies
// 上游所有RDD的分区集合
override def getPartitions: Array[Partition] = {
val parRDDs = if (isPartitionListingParallel) {
val parArray = rdds.par
parArray.tasksupport = UnionRDD.partitionEvalTaskSupport
parArray
} else {
rdds
}
val array = new Array[Partition](parRDDs.map(_.partitions.length).seq.sum)
var pos = 0
for ((rdd, rddIndex) <- rdds.zipWithIndex; split <- rdd.partitions) {
array(pos) = new UnionPartition(pos, rdd, rddIndex, split.index)
pos += 1
}
array
}
// 依赖上游所有RDD
override def getDependencies: Seq[Dependency[_]] = {
val deps = new ArrayBuffer[Dependency[_]]
var pos = 0
for (rdd <- rdds) {
deps += new RangeDependency(rdd, 0, pos, rdd.partitions.length)
pos += rdd.partitions.length
}
deps
}
// 上游RDD参与计算
override def compute(s: Partition, context: TaskContext): Iterator[T] = {
val part = s.asInstanceOf[UnionPartition[T]]
// 定位到上游 RDD 的对应分区数据迭代
parent[T](part.parentRddIndex).iterator(part.parentPartition, context)
}
}
union
对源RDD和参数RDD求并集后返回一个新的RDD
实现原理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def union(other: RDD[T]): RDD[T] = withScope {
sc.union(this, other)
}
def union[T: ClassTag](rdds: Seq[RDD[T]]): RDD[T] = withScope {
val nonEmptyRdds = rdds.filter(!_.partitions.isEmpty) // 获取掉空的RDD
val partitioners = nonEmptyRdds.flatMap(_.partitioner).toSet // 拿到所有RDD的分区器
if (nonEmptyRdds.forall(_.partitioner.isDefined) && partitioners.size == 1) {
// 如果只有一个分区器
new PartitionerAwareUnionRDD(this, nonEmptyRdds)
} else {
new UnionRDD(this, nonEmptyRdds)
}
}
应用案例
1
2
3
4
5
val list1: RDD[Int] = sc.makeRDD(List(1,2,3,4,5))
val list2: RDD[Int] = sc.makeRDD(List(6,7,8,9,10))
val unionRDD: RDD[Int] = list1.union(list2)
unionRDD.collect().foreach(println)
// Array(1,2,3,4,5,6,7,8,9)
RDD 到 Task 的转换
RDD DAG 相关内容
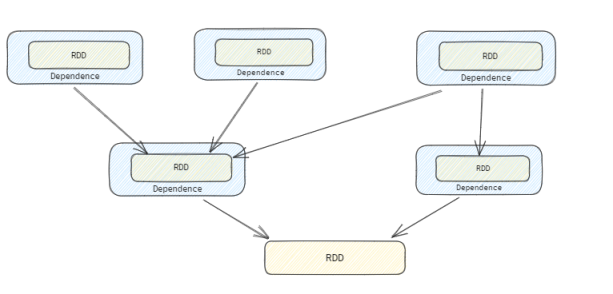
RDD 的依赖是一个DAG, 它的每一个依赖的RDD通过 Dependecy 来封装依赖的类型。
- 对于窄依赖,
RDD使用NarrowDependency实现依赖关系 - 对于宽依赖,
RDD则使用ShuffleDependency实现依赖关系,ShuffleDependency是RDD的切分点
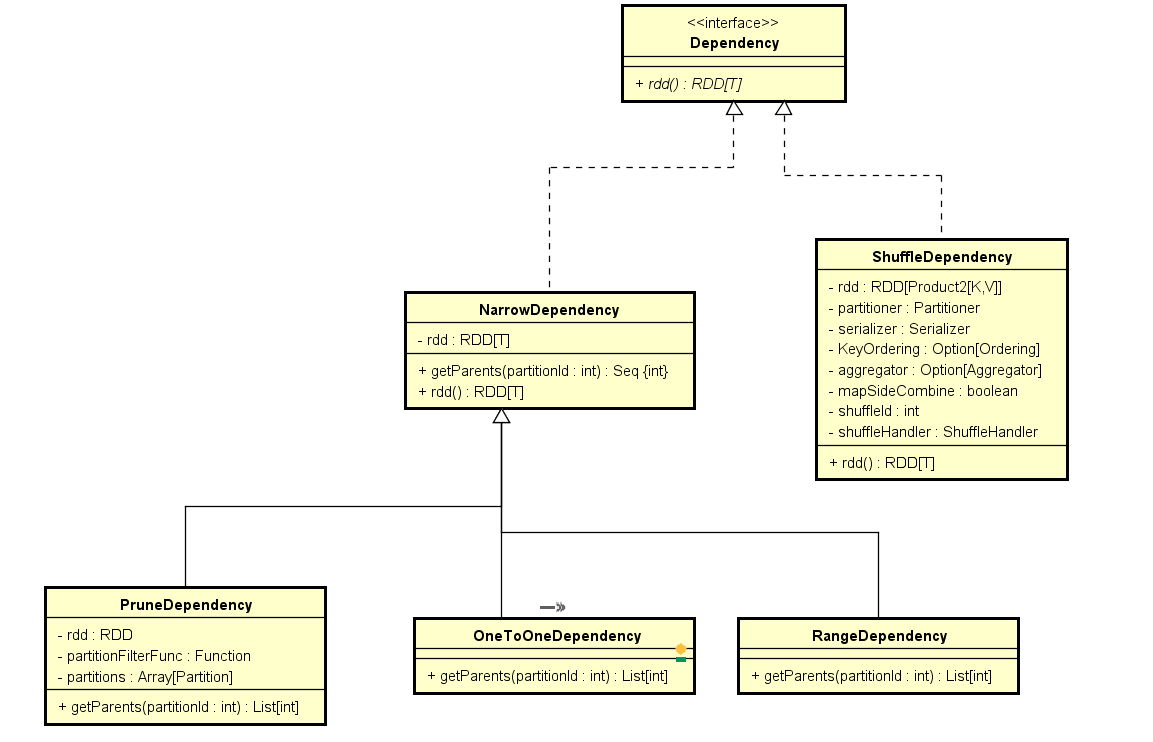
对于像类似 union 算子,会使用 RangeDependency 像类似 map, flatmap, filter 等相关算子,会使用 OneToOneDependency 类似 sortByKey, groupby 等算子,会使用 ShuffleDependency NarrowDependency 及其实现中信息量比较少,只包含有依赖的RDD等信息 ShuffleDependency 则为了保证上游RDD计算完以后能够按照下游RDD进行分区等操作,所以需要额外保留其他的信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]], // 上游依赖的 RDD
val partitioner: Partitioner, // 上游RDD数据计算完后需要采用的分区方式
val serializer: Serializer = SparkEnv.get.serializer, // RDD 的序列化工具
val keyOrdering: Option[Ordering[K]] = None, // 需要对key排序的排序器
val aggregator: Option[Aggregator[K, V, C]] = None, // RDD 聚合器
val mapSideCombine: Boolean = false) // 是否需要做Map端聚合(Combine)操作
extends Dependency[Product2[K, V]] {
// 生成一个ShuffleId
val shuffleId: Int = _rdd.context.newShuffleId()
// shufffle 操作句柄信息
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(shuffleId, _rdd.partitions.length, this)
}
Stage
Stage 是一组并行计算任务,这些任务都有计算相同的函数(位于RDD中),并且作为 Spark Job的一部分运行。 这些任务具有相同的shuffle依赖关系。
DAGSheduler 按照shuffle(ShuffleDependency)的边界将RDD图拆分成若干Stage,然后 DAGScheduler 按照 拓扑顺序运行这些Stage。

Stage 的实现有两种 :
ShuffleMapStage: 它的结果数据作为其他Stage的输入。ResultStage: 它的task通过在RDD上运行函数直接计算(例如count()、save()等)。
对于 ShuffleMapStage,我们还会追踪每个输出分区所在的节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
/**
* 基于 ShuffleDependency 创建一个 ShuffleMapStage
* @param shuffleDep : 目标ShuffleDependency
* @param jobId : 所属的作业ID
*/
def createShuffleMapStage(shuffleDep: ShuffleDependency[_, _, _], jobId: Int): ShuffleMapStage = {
// 当前ShuffleDependency 所对应的 RDd, 这里需要注意的是它是shuffle操作的上一个rdd
// kv 结构
val rdd = shuffleDep.rdd
val numTasks = rdd.partitions.length // task 数量对应的是目标rdd分区数量
val parents = getOrCreateParentStages(rdd, jobId) // 如果没有上游 stage, 首先创建上游stage(找上游的dependency)
val id = nextStageId.getAndIncrement() // 更新一个 stageId
// 基于当前的 ShuffleDependency[RDD] 创建一个 ShuffleMapStage
// - stageId, 目标RDD, 并行度,上游依赖stage, jobId, stage描述, 当前的ShuffleDependency, mapOutputTracker
val stage = new ShuffleMapStage(id, rdd, numTasks, parents, jobId, rdd.creationSite, shuffleDep, mapOutputTracker)
}
/**
* 对目标RDD创建 ResultStage .
* @param rdd : 目标RDD
* @param func : 对目标RDD所做的操作
* @param partitions : 分区数量
* @param jobId : 任务Id
* @param callSite : 作业描述信息
*/
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
// 构建上游的 ShuffleDependencyStage 依赖关系
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
// 创建结果 RDD
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
}
每个 Stage 还有一个jobId,用于标识首次提交该阶段的作业,当使用 FIFO 调度时,这允许较早作业的阶段被优先计算或在失败后更快地恢复。
最后,由于故障恢复的需要,单个Stage可以重试多次,在这种情况下,Stage对象将跟踪多个 StageInfo 对象,以便传递给Listener或 Web UI。
基于DAG RDD 的Stage 构建流程
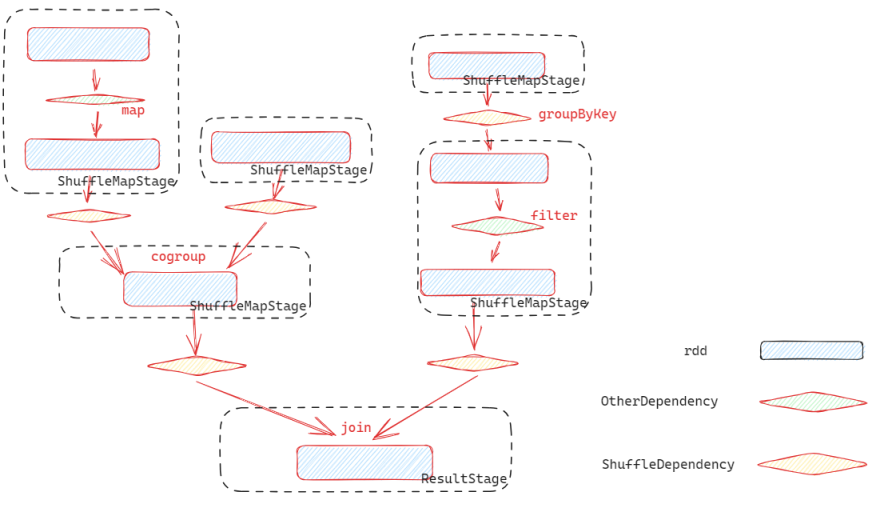
createResultStage 是基于RDD创建Stage的入口方法,它首先找到并创建上游的 ShuffleMapStage, 然后基于目标RDD与上游的依赖 ShuffleMapStage 创建 ResultStage.
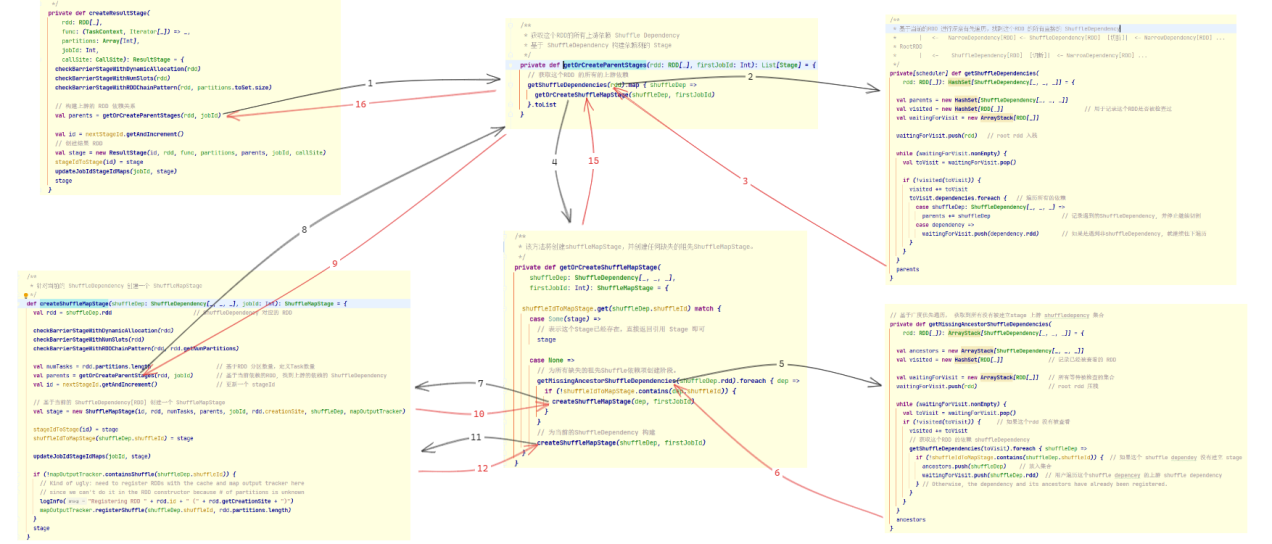
在 getOrCreateParentStages 构建 ShuffleMapStage 一个深度优先的构造过程:
- 先根据
ShuffleDependency切割RDD图,找到目标RDD的直接依赖的所有ShuffleDependency(通过getShuffleDependencies) - 基于获取到的
ShuffleDependency构建ShuffleMapStage,每个ShuffleDependency.shuffleId对应一个ShuffleMapStage ShuffleMapStage构建过程也是同样,先判断当前目标RDD是否存在依赖的ShuffleDepence,如果存在依赖,先构建依赖项,以此完成依赖构建- 这里为了加速构建过程,引入了
getMissingAncestorShuffleDependencies一次性获取所有的祖先ShuffleDependency
Stage 到 Task的映射关系
Stage 构建完成以后,便可以通过 submitStage 开始提交执行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
private def submitStage(stage: Stage) {
// 首先判断这个stage 没有被执行过
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 查看当前stage 有没有上游依赖的父stage
val missing = getMissingParentStages(stage).sortBy(_.id)
if (missing.isEmpty) {
// 正式执行当前stage
submitMissingTasks(stage, jobId.get)
} else {
// 如果存在依赖的父stage, 则首先执行父stage
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
}
- 执行前首先判断当前
stage在此之前有没有被执行过,或者正在执行。如果已经被执行,则跳过执行 - 对于没有被执行过的
stage, 则查看其所有依赖的stage, 如果存在依赖stage, 则首先执行依赖的stage - 如果当前
stage没有依赖,或者依赖都已经执行完成,则通过submitMissingTasks正式触发执行
stage 在转task之前,首先要将RDD跟依赖等相关信息广播到每个executor, 为任务执行做准备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
RDDCheckpointData.synchronized {
taskBinaryBytes = stage match {
case stage: ShuffleMapStage =>
// 将RDD跟 ShuffleDependency 进行序列化
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
// 将RDD跟对RDD的操作函数进行序列化
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
partitions = stage.rdd.partitions
}
taskBinary = sc.broadcast(taskBinaryBytes)
此后,将stage对应的分区展开,创建Task结构, Spark实现了两种类型的Task: ShuffleMapTask, ResultTask,分别对应与 ShuffleMapStage, ResultStage. Task对象是可序列化的,用于发送到Executor端去执行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// 每个stage基于其分区构建对应数量的 Task 结构
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
// 对于 ShuffleMapStage, 将构建 ShuffleMapTask
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id) // 任务本地化信息
val part = partitions(id) // 分区信息
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
}
case stage: ResultStage =>
// 对于 ResultStage 将构建 ResultTask
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,
stage.rdd.isBarrier())
}
}
}
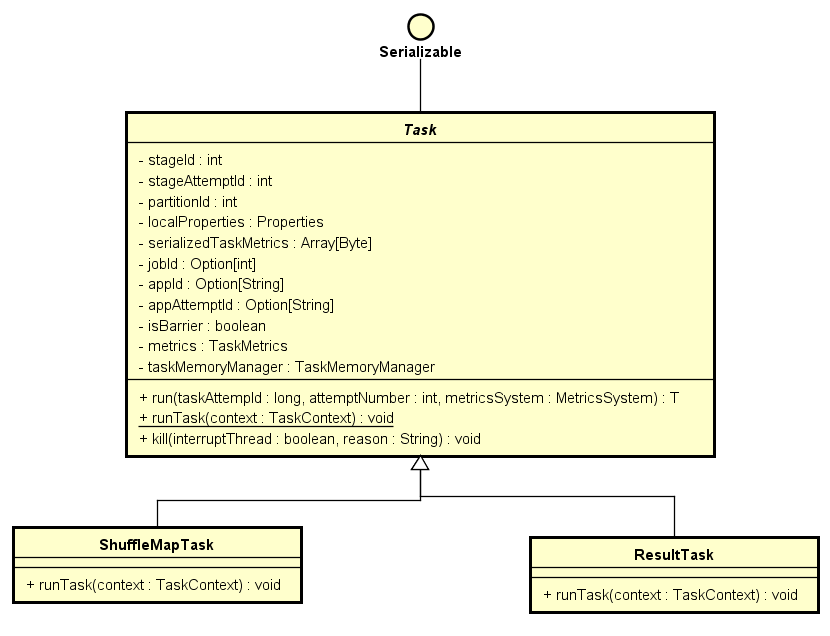
ShuffleMapTask 与 ResultTask中通过继承 runTask 来实现具体的执行逻辑,他首先通过反序列的形式来获取到RDD信息, 然后调用rdd.iterator来触发RDD的相关计算逻辑。
1
2
3
4
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
rdd.iterator(partition, context)
对于 ShuffleMapTask RDD 的计算结果数据需要交给 ShuffleManager 写到对应的分区中。 对于 ResultTaskRDD 的计算结果需要调用传递的函数来处理结果。