Spark 教程 | Spark Shuffle 解读

过上篇 SparkRDD解读文章 我们可以了解到,对于每个 ShuffleDependency会生成 ShuffleMapStage,ShuffleMapStage 对应生成 ShuffleMapTask。
在ShuffleMapTask 中将计算对应的RDD分区数据,然后将结果通过ShuffleManager写出去。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// ShuffleMapTask.scala
override def runTask(context: TaskContext): MapStatus = {
。。。
// 获取RDD与Dependency
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
// 获取 ShuffleManager
val manager = SparkEnv.get.shuffleManager
// 获取 ShuffleWriter
var writer: ShuffleWriter[Any, Any] = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
// 将RDD 对应的分区数据写出到 ShuffleWriter
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
。。。
}
而后在 ShuffledRDD 中将通过 ShuffleManager 将对应的分区数据读取出来。 然后转交给下游来计算
1
2
3
4
5
6
7
// ShuffledRDD.scala
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
}
ShuffledManager
在 SparkEnv 中,基于 spark.shuffle.manager 来配置 ShuffleManager 的实现类。 Driver用它注册 shuffle,Executor(或在driver中本地运行的任务)基于ShuffleManager来读取或者写入数据
1
2
3
4
5
6
7
8
// SparkEnv.scala
val shortShuffleMgrNames = Map(
"sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName,
"tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName)
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass =
shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase(Locale.ROOT), shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
在Spark的历史版本中,对于Shuffle Manager有两种实现。在1.2版本之前的Hash Base Shuffler,以及从1.2版本开始后的基于Sort Base Shuffler。至于Hash Base Shuffler,目前以及被移除,当前版本只保留 SortShuffleManager
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// ShuffleManager.scala
private[spark] trait ShuffleManager {
// 通过ShuffleDependency 来注册获取一个ShuffleHandler
def registerShuffle[K, V, C](shuffleId: Int, numMaps: Int, dependency: ShuffleDependency[K, V, C]): ShuffleHandle
// 获取给定分区的写入器。由ShuffledMapTask在Executor上调用。
def getWriter[K, V](handle: ShuffleHandle, mapId: Int, context: TaskContext): ShuffleWriter[K, V]
// 为一系列的reduce分区 [startPartition, endPartition) 获取一个读取器, 由reduce任务在执行器上调用。
def getReader[K, C](handle: ShuffleHandle, startPartition: Int, endPartition: Int, context: TaskContext): ShuffleReader[K, C]
// 从ShuffleManager中移除shuffle的元数据。
def unregisterShuffle(shuffleId: Int): Boolean
// 返回一个能够根据block坐标检索shuffle block 数据的解析器。
def shuffleBlockResolver: ShuffleBlockResolver
def stop(): Unit
}

ShuffuleManager 总共有三部分组件, ShuffleReader, ShuffleWriter, ShuffleHandle.
ShuffleHandle 记录了对应Shuffle的元信息相关的,其中包含了shuffleId, 上游分区数,ShuffledRDD 对应的 ShuffleDependency 等的信息。
ShuffleReader 的主要功能是用来读取reduce端对应分区的数据,返回分区数据集合。
ShuffleWriter 的主要功能是用来将map端的计算数据结果按照目标分区排序后写出到外部存储中。
ShuffleWriter
当前 SortShuffleManager 中支持3中类型的 ShuffleWriter, 他们分别为 BypassMergeSortShuffleWriter, UnsafeShuffleWriter, SortShuffleWriter
SortShuffleManager 依据具体的情况,合理选择一个ShuffleWriter来完成map端数据shuffle。
- 如果map端没有启用combine操作, 并且reduce分区数量少于
spark.shuffle.sort.bypassMergeThreshold设置的分区大小,则优先使用BypassMergeSortShuffleWriter。(适用于分区少的情况) - 如果 map 端没有启用combine操作,并且数据支持重定向序列化,则选择使用
UnsafeShuffleWriter - 如果以上两种都不满足,则选择使用
SortShuffleWriter
BypassMergeSortShuffleWriter
BypassMergeSortShuffleWriter 更适用于分区数量较少的的情况, 要启用它必须满足三个条件:
- 不存在排序的情况
- 没有combine
- 分区数少于
spark.shuffle.sort.bypassMergeThreshold
这个实现在数据写出的过程中,会对每个reduce目标分区生成一个文件,然后遍历所有的待写入数据,将每个数据写入到对应的分区文件中。
然后将这些分区的文件连接起来形成一个单一的输出文件,提供给reduce使用。

具体步骤如下:
第一步:对每个目标分区创建一个临时写文件,用来将内存数据集序列化到文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// BypassMergeSortShuffleWriter.java
// Step 1 : 为每个分区创建一个分区文件写
partitionWriters = new DiskBlockObjectWriter[numPartitions]; // 对象写文件工具
partitionWriterSegments = new FileSegment[numPartitions]; // 文件元信息
for (int i = 0; i < numPartitions; i++) {
// 对于每个分区, 创建一个临时文件用来存放shuffle数据
final Tuple2<TempShuffleBlockId, File> tempShuffleBlockIdPlusFile = blockManager.diskBlockManager().createTempShuffleBlock();
final File file = tempShuffleBlockIdPlusFile._2();
final BlockId blockId = tempShuffleBlockIdPlusFile._1();
// 通过 BlockManager 封装了一个磁盘写入工具 [[org.apache.spark.storage.DiskBlockObjectWriter]]
partitionWriters[i] = blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, writeMetrics);
}
第二步: 遍历数据,写出到文件,这里需要注意的是,每条数据将写入对应分区的文件中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// BypassMergeSortShuffleWriter.java
// Step 2 : 遍历迭代数据记录,将记录内容写出
while (records.hasNext()) {
final Product2<K, V> record = records.next();
final K key = record._1();
final int partition = partitioner.getPartition(key); // 定位分区
// 找到对应的写文件, 数据写出
partitionWriters[partition].write(key, record._2());
}
// 将每个文件都提交上
for (int i = 0; i < numPartitions; i++) {
final DiskBlockObjectWriter writer = partitionWriters[i];
partitionWriterSegments[i] = writer.commitAndGet();
writer.close();
}
第三步 : 合并分区文件,形成一个最终文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// BypassMergeSortShuffleWriter.java
// Step 3 : 合并临时文件,生成目标文件
File output = shuffleBlockResolver.getDataFile(shuffleId, mapId); // 创建shuffle 写出文件 : shuffle_{shuffleId}_{mapId}_0.data
File tmp = Utils.tempFileWith(output); // {output}.xxxxx -- 临时文件
partitionLengths = writePartitionedFile(tmp); // 将每个分区文件合并写到目标文件, 并返回每个分区的文件长度
// 提交 Shuffle 数据
shuffleBlockResolver.writeIndexFileAndCommit(shuffleId, mapId, partitionLengths, tmp);
/**
* 将所有分区文件连接成一个单独的组合文件。
* @return 每个分区文件的长度数组,以字节为单位(由map输出跟踪器使用)。
*/
private long[] writePartitionedFile(File outputFile) throws IOException {
...
final FileOutputStream out = new FileOutputStream(outputFile, true); // 创建增量输出流
for (int i = 0; i < numPartitions; i++) {
final File file = partitionWriterSegments[i].file(); // 拿到每个分区的写出文件
lengths[i] = Utils.copyStream(in, out, false, transferToEnabled); // 将分区文件数据拷贝到目标文件中
}
...
}
UnsafeShuffleWriter
在 SPARK-4550 中提出了基于序列化对象的排序方式。
它的排序操作基于序列化的二进制数据,而不是Java对象,这减少了内存消耗和垃圾回收开销。
这只在对象的序列化表示相互独立且占据内存的连续段时才有效。例如,当Kryo引用跟踪被保留时,对象可能包含指向流中更远对象的指针,这意味着排序无法重新定位对象,否则会导致对象损坏。
它使用了一个专门的高缓存效率的排序器(ShuffleExternalSorter),该Sorter对压缩Record指针和分区ID的数组进行排序。通过在排序数组中每个记录仅使用8字节的空间,可以将更多的数组数据放入缓存中。
溢写合并过程操作的是属于同一分区的序列化记录块,在合并过程中不需要对记录进行反序列化
当溢写压缩编解码器支持压缩数据的串联时,溢写合并过程仅仅将序列化和压缩的溢写分区串联起来,生成最终的输出分区。这允许使用高效的数据复制方法,例如NIO的 transferTo,并且避免在合并过程中分配解压缩或复制缓冲区。
写内存阶段
在Shuffle 过程中,数据首先会被序列化成字节流对象,可以节省部分存储资源。然后写入内存块中,只有当内存资源不足时,才将内存块的数据顺序溢写成文件。
1
2
3
4
5
6
7
8
9
10
11
12
// UnsafeShuffleWriter.insertRecordIntoSorter
// STEP 1 : 将数据序列化
serBuffer.reset();
serOutputStream.writeKey(key, OBJECT_CLASS_TAG);
serOutputStream.writeValue(record._2(), OBJECT_CLASS_TAG);
serOutputStream.flush();
final int serializedRecordSize = serBuffer.size();
// STEP 2 : 将序列化后的对象写入 ShuffleExternalSorter
sorter.insertRecord(serBuffer.getBuf(), Platform.BYTE_ARRAY_OFFSET, serializedRecordSize, partitionId);
数据的内存写过程主要是 ShuffleExternalSorter 类来完成。
序列化的数据对象将使用两个结构来存储,一个是用来存储序列化对象数据的块存储(MemoryBlock),一个是用来节省排序内存空间的 ShuffleInMemorySorter 对象
数据在写入时通过currentPage定位当前可以写入数据的MemoryBlock, 数据从pageCursor作为起始位置写入。如果当前没有可用的MemoryBlock或者剩余空间不足以存放下一个完整的Record, 则放弃写入当前Block, 而是重新分配一个新的MemoryBlock给currentPage,用来作为数据写入。所有存放数据MemoryBlock集合在LinkedList<MemoryBlock> allocatedPages结构中维护
数据的写入包含数据头部(序列化化数据的长度)与数据体(序列化数据),写入时,顺便记录下当前的数据分区与数据索引位置(块号+块内偏移),通过数据索引+数据头部,我们可以方便的取回数据。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
// ShuffleExternalSorter.insertRecord
private void acquireNewPageIfNecessary(int required) {
// 如果当前没有分配页,或者分配的内存页剩余空间不足,则分配一个新的页
if (currentPage == null ||
pageCursor + required > currentPage.getBaseOffset() + currentPage.size() ) {
// TODO: try to find space in previous pages
currentPage = allocatePage(required);
pageCursor = currentPage.getBaseOffset(); // 拿到页内偏移
allocatedPages.add(currentPage);
}
}
// 需求内存总大小 = 序列化对象长度 + UAO 对象大小
final int required = length + uaoSize;
// 检查内存页是否满足条件,不满足条件则准备一个新的内存页
acquireNewPageIfNecessary(required);
// 拿到底层的存储对象 long[]
final Object base = currentPage.getBaseObject();
// 计算数据要写入的位置(用户后期数据定位): 页号左移51位 | 页内偏移低51位
final long recordAddress = taskMemoryManager.encodePageNumberAndOffset(currentPage, pageCursor);
// TODO : 将数据写入 currentPage 对应的块中: [ len(recordBase) ] [recordBase]
// 写入序列化数据的长度
UnsafeAlignedOffset.putSize(base, pageCursor, length);
pageCursor += uaoSize; // 更新偏移位置
Platform.copyMemory(recordBase, recordOffset, base, pageCursor, length);
pageCursor += length;
// inMemSorter 记录数据 : 数据位置, 数据所在分区
inMemSorter.insertRecord(recordAddress, partitionId);
ShuffleInMemorySorter 内部使用LongArray来维护 数据的分区与索引数据,分区用来进行数据排序,索引则用来定位数据体。这样的好处是排序时无需使用数据本身来参加排序,以此来节省排序时的内存空间。
1
2
3
4
5
6
7
8
9
10
11
12
// ShuffleInMemorySorter.java
public static long packPointer(long recordPointer, int partitionId) {
final long pageNumber = (recordPointer & MASK_LONG_UPPER_13_BITS) >>> 24;
final long compressedAddress = pageNumber | (recordPointer & MASK_LONG_LOWER_27_BITS);
// 高40位位分区号 | 第 40 位是压缩地址
return (((long) partitionId) << 40) | compressedAddress;
}
public void insertRecord(long recordPointer, int partitionId) {
// 对象指针跟分区号的封装结构,
array.set(pos, PackedRecordPointer.packPointer(recordPointer, partitionId));
pos++;
}
内存数据溢写磁盘
当内存不足以容纳更多数据时,将会触发spill操作,把MemoryBlock块集合写出到文件,在写之前,首先通过 ShuffleInMemorySorter 对LongArray对象按照parititionId来进行排序。
排完序后,按顺序读取数据索引,取出位于MemoryBlock的序列化数据,写入磁盘文件中,并且使用SpillInfo对象记录当前文件中每个分区的数据长度,用来索引分区
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
// ShuffleExternalSorter.writeSortedFile
// 将 inMemSorter 排序并返回一个迭代器
final ShuffleInMemorySorter.ShuffleSorterIterator sortedRecords = inMemSorter.getSortedIterator();
// 对象拷贝到writeBuffer用于写磁盘
final byte[] writeBuffer = new byte[diskWriteBufferSize];
// 因为这个输出将在shuffle期间被读取,所以它的压缩编解码器必须由spark.shuffle.compress控制
// 而不是由spark.shuffle.spill.compress控制,因此我们需要在这里使用createTempShuffleBlock
// 更多细节请参见SPARK-3426。
final Tuple2<TempShuffleBlockId, File> spilledFileInfo = blockManager.diskBlockManager().createTempShuffleBlock();
final File file = spilledFileInfo._2();
final TempShuffleBlockId blockId = spilledFileInfo._1();
final SpillInfo spillInfo = new SpillInfo(numPartitions, file, blockId);
final DiskBlockObjectWriter writer = blockManager.getDiskWriter(blockId, file, ser, fileBufferSizeBytes, writeMetricsToUse);
// 遍历有序数据集
while (sortedRecords.hasNext()) {
sortedRecords.loadNext(); // 获取迭代数据
final int partition = sortedRecords.packedRecordPointer.getPartitionId(); // 获取数据对应分区
if (partition != currentPartition) { // 如果切换新的分区,则记录上一个分区的数据长度
if (currentPartition != -1) {
final FileSegment fileSegment = writer.commitAndGet();
spillInfo.partitionLengths[currentPartition] = fileSegment.length(); // 记录每个分区的长度
}
currentPartition = partition;
}
// 取出序列化对象数据,并写到文件中
final long recordPointer = sortedRecords.packedRecordPointer.getRecordPointer(); // 拿到数据索引
final Object recordPage = taskMemoryManager.getPage(recordPointer);
final long recordOffsetInPage = taskMemoryManager.getOffsetInPage(recordPointer);
int dataRemaining = UnsafeAlignedOffset.getSize(recordPage, recordOffsetInPage);
long recordReadPosition = recordOffsetInPage + uaoSize; // skip over record length
while (dataRemaining > 0) {
final int toTransfer = Math.min(diskWriteBufferSize, dataRemaining);
Platform.copyMemory(recordPage, recordReadPosition, writeBuffer, Platform.BYTE_ARRAY_OFFSET, toTransfer);
writer.write(writeBuffer, 0, toTransfer);
recordReadPosition += toTransfer;
dataRemaining -= toTransfer;
}
// 记录数据写
writer.recordWritten();
}
final FileSegment committedSegment = writer.commitAndGet();
writer.close();
if (currentPartition != -1) {
spillInfo.partitionLengths[currentPartition] = committedSegment.length();
spills.add(spillInfo);
}
合并Spill文件形成最终的Shuffle文件
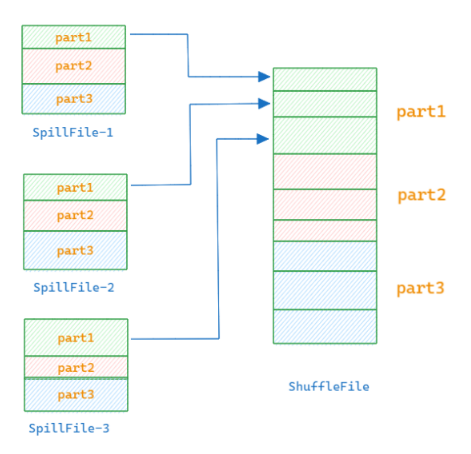
UnsafeShuffleWriter 在合并spill文件时会同时打开所有的 SpillFile ,然后按顺序将每个分区在所有SpillFile中的数据读取顺序写入到目标文件中,构建ShuffleFile
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
// 使用计数输出流,以避免在每个分区写入后关闭底层文件并向文件系统请求其大小。
final CountingOutputStream mergedFileOutputStream = new CountingOutputStream(bos);
// 遍历所有的分区
for (int partition = 0; partition < numPartitions; partition++) {
// 基于计数器的写流
OutputStream partitionOutput = new CloseAndFlushShieldOutputStream(new TimeTrackingOutputStream(writeMetrics, mergedFileOutputStream));
partitionOutput = blockManager.serializerManager().wrapForEncryption(partitionOutput);
if (compressionCodec != null) { // 判断是否要压缩写出
partitionOutput = compressionCodec.compressedOutputStream(partitionOutput);
}
for (int i = 0; i < spills.length; i++) { // 遍历所有的Spill文件
final long partitionLengthInSpill = spills[i].partitionLengths[partition]; // 定位当前当前spill中当前分区的数据位置
if (partitionLengthInSpill > 0) {
InputStream partitionInputStream = new LimitedInputStream(spillInputStreams[i], partitionLengthInSpill, false);
try {
partitionInputStream = blockManager.serializerManager().wrapForEncryption(partitionInputStream);
if (compressionCodec != null) {
partitionInputStream = compressionCodec.compressedInputStream(partitionInputStream);
}
// 将SpillFile的当前分区写出到目标文件
ByteStreams.copy(partitionInputStream, partitionOutput);
} finally {
partitionInputStream.close();
}
}
}
partitionOutput.flush();
partitionOutput.close();
// 记录每个分区的数据长度
partitionLengths[partition] = (mergedFileOutputStream.getByteCount() - initialFileLength);
}
总的来说,UnsafeShuffleWriter 利用内存数据结构、排序和合并技术以及最小化磁盘操作的策略来加速Shuffle过程,从而提高Spark作业的性能。 不过需要注意的是,虽然UnsafeShuffleWriter能够带来性能上的提升,但它也可能会对内存资源造成一定的压力,特别是在处理大规模数据时。
SortShuffleWriter
SortShuffleWriter 是一个通用的 Shuffle 写工具。
它首先在写入时按照分区进行排序,这个操作在内存中完成,如果内存数据不足时,数据将有序写入到临时文件中。
如果数据量很大,将进行多次溢写操作产生多个临时文件,后续的 Shuffle 阶段会将这些文件进行合并,以生成最终的结果。
同时它还支持基于Combine 的Shuffle操作,如果开启Combine操作,那么数据在写入时将合并相同key的数据。减少shuffle时的数据写出量。
SortShuffleWriter 的Shuffle操作主要通过ExternalSorter来完成。
1
2
3
4
5
6
7
8
9
10
11
12
13
// SortShuffleWriter.write()
sorter = if (dep.mapSideCombine) {
// 如果需要combine 操作,则开启写出聚合操作
new ExternalSorter[K, V, C](context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// 如果不需要combine操作
// 在这种情况下,我们既不向排序器传递聚合器,也不向排序器传递排序,因为我们不关心每个分区中的键是否已排序;
// 这将在reduce方面完成
new ExternalSorter[K, V, V](context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
sorter.insertAll(records)
没有启用Combine的情况
如果Shuffle过程中没有开启 Combine 操作, 将遍历迭代数据集合, 将数据将被有序的放入到 PartitionedPairBuffer。
1
2
3
4
5
6
// ExternalSorter.insertAll()
while (records.hasNext) {
val kv = records.next()
buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C]) // 数据组织成 // (partitionId, recordKey) -> record 写入 PartitionedPairBuffer
maybeSpillCollection(usingMap = false) // 判断内存空间是否足够,是否需要将数据刷到磁盘
}
PartitionedPairBuffer是一个顺序的数组结构。初始大小为64*2。
数组中每连续两个单元空间用来存放一条数据(key, value), 它有序的将数据依次放置到数组空间空,初始可以放置 64条记录。
如果数组已经被填充满,数组将会被扩容到两倍。用来存放更多的数据。
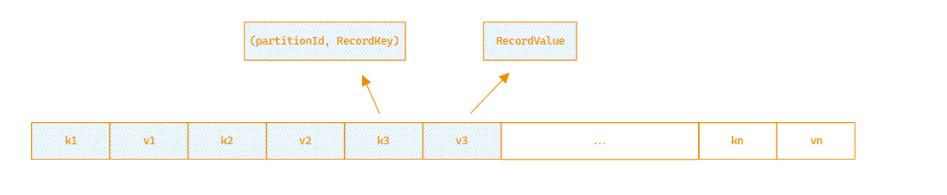
数据每写入一条之后,都会判断PartitionedPairBuffer当前使用的内存大小。 过程请参考 ExternalSorter.maybeSpillCollection.
当内存使用超过限制时,数据将被刷写到磁盘中形成 SpillFile,如果数据量过多这个过程会在磁盘中形成多个SpillFile文件。
PartitionedPairBuffer写出到 SpillFile 之前,会先在内存中按照partitionId进行排序,然后将数据有序的写到文件中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// PartitionedPairBuffer.java
def partitionComparator[K]: Comparator[(Int, K)] = new Comparator[(Int, K)] {
override def compare(a: (Int, K), b: (Int, K)): Int = {
a._1 - b._1 // partitionId
}
}
// 如果没有开启combine操作, 则partitionKeyComparator一直是None
// 参照 SortShuffleWriter.write() 中ExternalSort 构造过程
val comparator = keyComparator.map(partitionKeyComparator).getOrElse(partitionComparator) // 返回 partitionComparator 比较器
// ExternalSorter.scala
// 数据spill
override protected[this] def spill(collection: WritablePartitionedPairCollection[K, C]): Unit = {
val inMemoryIterator = collection.destructiveSortedWritablePartitionedIterator(comparator) // 对数据按照分区进行排序
val spillFile = spillMemoryIteratorToDisk(inMemoryIterator) // 将内存数据写到磁盘,形成 SpillFile 文件
spills += spillFile // 记录所有的 SpillFile 文件集合
}
当所有的数据写成功以后, 将开启合并 SpillFile 文件过程,形成最终的 ShuffleFile. 这里注意的是合并时不只要读取 SpillFile 中的文件数据,PartitionedPairBuffer中可能还有最后一批插入到内存中的数据。这时候也需要读取一起合并。
合并 SpillFile 过程比较简单,它将基于当前的分区数,从每个SpillFile与PartitionedPairBuffer中读取对应的分区数据,然后拼接写入到ShuffleFile中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
private def merge(spills: Seq[SpilledFile], inMemory: Iterator[((Int, K), C)])
: Iterator[(Int, Iterator[Product2[K, C]])] = {
val readers = spills.map(new SpillReader(_)) // 得到所有 Spill 文件的迭代器
val inMemBuffered = inMemory.buffered // 得到文件的迭代器
(0 until numPartitions).iterator.map { p => // 迭代所有的分区
// 这里需要注意的是,SpillFile 中的数据迭代器是懒加载的, 只有调用hasNext() 时才真正从文件中取出一条数据。
val inMemIterator = new IteratorForPartition(p, inMemBuffered) // 获取内存数据在当前分区的迭代器
val iterators = readers.map(_.readNextPartition()) ++ Seq(inMemIterator) // 拼接所有SpillFile 对应当前分区的迭代器 + 内存数据分区迭代器
(p, iterators.iterator.flatten) // 非 combine 情况下,直接展开对应的分区数据即可
}
}
启用Combine的情况
如果数据在ShuffleWriter阶段启用了 combine ,这时候要在数据写入时对key相同的数据完成合并工作,减少Shuffle过程中落盘的数据量。
它内部将使用插入到PartitionedAppendOnlyMap结构中。
数据在写入PartitionedAppendOnlyMap时增加了combine操作,用来合并相同key的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// ExternalSorter.java
def insertAll(records: Iterator[Product2[K, V]]): Unit = {
// 如果需要进行与合并, 则直接在内存中进行合并处理
val mergeValue = aggregator.get.mergeValue
val createCombiner = aggregator.get.createCombiner
var kv: Product2[K, V] = null
val update = (hadValue: Boolean, oldValue: C) => {
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
}
while (records.hasNext) {
addElementsRead() // 记录数据读取
kv = records.next() // 提取出 kv 数据记录, key -> (partitinId, recordKey)
map.changeValue((getPartition(kv._1), kv._1), update) // 插入的同时完成合并工作
maybeSpillCollection(usingMap = true)
}
}

PartitionedAppendOnlyMap与 PartitionedPairBuffer 的底层存储基本类似,唯一区别就是在数据定位上,它不是顺序存取的,而是基于hash(key)来确定数据的索引位置。
这样用户数据的快速定位。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// AppendOnlyMap.java
var pos = rehash(key.hashCode) & mask
var i = 1
while (true) {
val curKey = data(2 * pos)
if (curKey.eq(null)) {
data(2 * pos) = k
data(2 * pos + 1) = value.asInstanceOf[AnyRef]
incrementSize() // Since we added a new key
return
} else if (k.eq(curKey) || k.equals(curKey)) {
data(2 * pos + 1) = value.asInstanceOf[AnyRef]
return
} else {
val delta = i
pos = (pos + delta) & mask
i += 1
}
}
PartitionedAppendOnlyMap使用数组中每连续两个单元空间用来存放一条数据(key, value),使用hash(key)用来定位数据写入位置,如果当前位置已经有值,则从当前位置开始往后找到第一个空闲位置写入数据。初始可以放置 64条记录。
如果数组已经被填充满, 数组将会被扩容到两倍。用来存放更多的数据。
数据每写入一条之后,都会判断PartitionedAppendOnlyMap当前使用的内存大小。 过程请参考 ExternalSorter.maybeSpillCollection.
当内存使用超过限制时,数据将被刷写到磁盘中形成 SpillFile,如果数据量过多这个过程会在磁盘中形成多个SpillFile文件。
PartitionedAppendOnlyMap写出到 SpillFile 之前,需要先在内存中做一下排序,默认按照 (partitionId + RecordKey.hashcode()) 的组合进行排序操作, 为了后续的合并spill文件时的二次combine操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
private val keyComparator: Comparator[K] = ordering.getOrElse(new Comparator[K] {
override def compare(a: K, b: K): Int = {
val h1 = if (a == null) 0 else a.hashCode()
val h2 = if (b == null) 0 else b.hashCode()
if (h1 < h2) -1 else if (h1 == h2) 0 else 1
}
})
private def comparator: Option[Comparator[K]] = {
// 对于开启 combine 操作的 Shuffle Writer Aggregator 参数一定非空
if (ordering.isDefined || aggregator.isDefined) {
Some(keyComparator)
} else {
None
}
}
// PartitionedAppendOnlyMap.java
def partitionedDestructiveSortedIterator(keyComparator: Option[Comparator[K]])
: Iterator[((Int, K), V)] = {
val comparator = keyComparator.map(partitionKeyComparator).getOrElse(partitionComparator)
destructiveSortedIterator(comparator)
}
当所有的数据写成功以后, 将开启合并 SpillFile 文件过程,形成最终的ShuffleFile. 这里注意的是合并时不只要读取 SpillFile 中的文件数据,PartitionedAppendOnlyMap中可能还有最后一批插入到内存中的数据。这时候也需要读取一起合并。
合并过程需要考虑到不同的SpillFile 中可能存在相同key的记录,这时候需要进行二次 combine 操作,合并不同 SpillFile 中的数据。
首先取出每个分区在不同
SpillFile与PartitionedAppendOnlyMap的迭代器因为每个
SpillFile中的数据是按照key进行排序的,PartitionedAppendOnlyMap也可以有序处理,所以可以使用排序,形成一个有序的迭代器。针对有序的迭代器,在数据输出时合并相邻数据中存在相同key的记录,形成最后的数据记录。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
private def mergeWithAggregation(
iterators: Seq[Iterator[Product2[K, C]]], // 当前分区的所有待合并的数据集,
mergeCombiners: (C, C) => C, // combine 操作
comparator: Comparator[K], // key 比较器, 默认hashcode
totalOrder: Boolean) // 是否排序
: Iterator[Product2[K, C]] =
{
new Iterator[Iterator[Product2[K, C]]] {
// 归并排序
val sorted = mergeSort(iterators, comparator).buffered
val keys = new ArrayBuffer[K]
val combiners = new ArrayBuffer[C]
override def hasNext: Boolean = sorted.hasNext
override def next(): Iterator[Product2[K, C]] = {
val firstPair = sorted.next()
keys += firstPair._1
combiners += firstPair._2
val key = firstPair._1
// 合并相同key 的数据
while (sorted.hasNext && comparator.compare(sorted.head._1, key) == 0) {
val pair = sorted.next()
var i = 0
var foundKey = false
while (i < keys.size && !foundKey) {
if (keys(i) == pair._1) {
combiners(i) = mergeCombiners(combiners(i), pair._2)
foundKey = true
}
i += 1
}
if (!foundKey) {
keys += pair._1
combiners += pair._2
}
}
keys.iterator.zip(combiners.iterator)
}
}.flatMap(i => i)
}
总结
ShuffleWrite是Spark中一个重要的阶段,通常在执行数据转换操作时会涉及到,如groupByKey,reduceByKey,join等操作。
它的主要工作是将数据重新分区并写入磁盘,以便在后续阶段进行数据合并和聚合。
ShuffleWrite 的主要工作包括以下几个方面:
数据的重分区 : 每一个map的数据按照partitionId 进行分区处理,保证数据按照分区有序。
中间数据落盘 : 中间处理过程中的数据会进行多次落盘操作, 避免内存数据量过大导致的内存溢出问题。
Combine操作 : 如果算子操作过程中要求进行combine, 那么数据在Shuffle期间会按照key进行combine处理。
合并成目标文件: 由于shuffle过程中会产生多个临时文件,在所有数据都处理完成后,会将这些临时文件统一合并成目标文件,按照分区有序。
当ShuffleWriter执行完成以后, Executor 会将Shuffle的MapStatus通过RPC通知到Driver端,Driver 内部通过MapOutputTrackerMaster来维护每个shuffleId对应的所有的MapStatus, 用来提供给Reduce端读取数据。
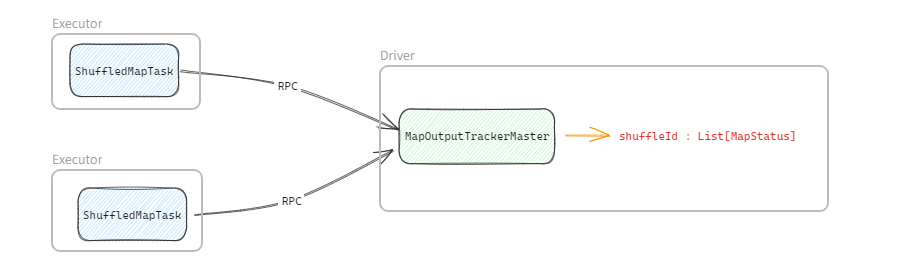
ShuffleReader
ShuffleReader用于Reduce端读取Map端的Shuffle数据。
它的主要工作内容是:
通过
ShuffleHandle获取Shuffle的元信息通过
MapOutputTrackerWorker来获取当前Shuffle指定的分区数据所在的数据位置。基于数据位置,通过
BlockManager来获取数据, BlockManager中维护有本地Block与远程Block的获取方式。将
Block中的数据反序列成 RecordKey, RecordValue数据集合如果需要聚合操作,要进行聚合操作处理
如果需要排序,则使用
ExternalSorter进行排序处理
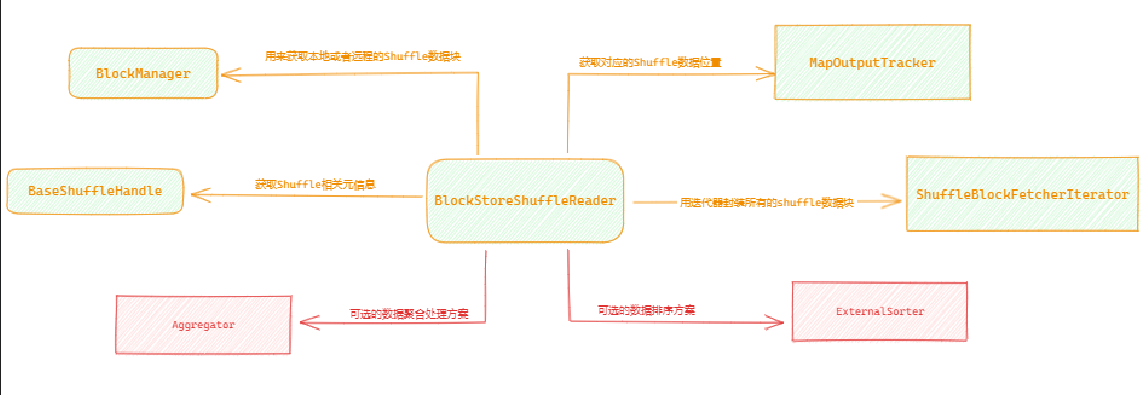
获取Shuffle数据信息
MapStauts我们在上面提到过, 它记录了当前ShuffleId对应的Map任务的Shuffle元信息
1
2
3
4
5
6
7
private[spark] sealed trait MapStatus {
// 当前MapTask Shuffle 的数据位置: ip : port,executorId 等信息
def location: BlockManagerId
// 返回当前MapTask 对应Reduce的分区数据大小
def getSizeForBlock(reduceId: Int): Long
}
当ShuffleMapTask在数据写出完成后,会将MapStatus上报给Driver端的MapOutputTrackerMaster.
当Reduce端任务启动后MapOutputTrackerWorker通过RPC向位于Driver端的发送请求,拉取对应 shuffleId 的 MapStatus 集合。

1
2
3
4
5
// MapOutputTrackerWorker.getStatuses
val fetchedBytes = askTracker[Array[Byte]](GetMapOutputStatuses(shuffleId)) // 从 driver 端获取当前ShuffleId 的 MapStatus 数据
fetchedStatuses = MapOutputTracker.deserializeMapStatuses(fetchedBytes)
logInfo("Got the output locations")
mapStatuses.put(shuffleId, fetchedStatuses) // 为了避免重复的数据拉取, 所以放入缓存中处理
获取到MapStatus之后,Reduce端基于当前要处理的分区获取到对应的分区数据大小,便于后期处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// MapOutputTracker.convertMapStatuses
// 数据按照它的位置进行分区
// 结构 : 数据位置 -> ((ShuffleId,MapId, PartId), 数据大小)
val splitsByAddress = new HashMap[BlockManagerId, ListBuffer[(BlockId, Long)]]
// 遍历所有的 MapStaus
for ((status, mapId) <- statuses.iterator.zipWithIndex) {
// 提取指定分区的数据大小
for (part <- startPartition until endPartition) {
val size = status.getSizeForBlock(part)
if (size != 0) {
splitsByAddress.getOrElseUpdate(status.location, ListBuffer()) += ((ShuffleBlockId(shuffleId, mapId, part), size))
}
}
}
splitsByAddress.iterator
BlockManagerId 包含了数据所在的位置(ip地址,端口等信息),用于Reduce 端请求拉取Map端产生的数据。
ShuffleBlockFetcherIterator
ShuffleBlockFetcherIterator是一个用于从远程节点或本地文件系统获取 Shuffle 数据块的迭代器.
他首先将MapOutputTrackerWorker数据块信息区分是否是本地数据块:
对于本地数据块,可以直接通过文件接口操作
对于远程数据块,调用ShuffleClient来读取。
对于远程数据块,数据在请求时尽量将更多的块在一个请求内完成。请求的数据量大小限制通过 spark.reducer.maxSizeInFlight 参数控制。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
for ((address, blockInfos) <- blocksByAddress) {
if (address.executorId == blockManager.blockManagerId.executorId) {
// 本地数据块
...
} else {
// 远程数据块
val iterator = blockInfos.iterator
var curRequestSize = 0L
var curBlocks = new ArrayBuffer[(BlockId, Long)]
while (iterator.hasNext) {
val (blockId, size) = iterator.next()
curBlocks += ((blockId, size)) // 当前请求的数据块集合
curRequestSize += size // 当前请求的数据量
if (curRequestSize >= targetRequestSize ||
curBlocks.size >= maxBlocksInFlightPerAddress) { // 数据大小超过限制大小
// Add this FetchRequest
remoteRequests += new FetchRequest(address, curBlocks) // 构造远程数据请求
curBlocks = new ArrayBuffer[(BlockId, Long)] // 清空块集合
curRequestSize = 0
}
}
}
}
数据块请求准备完成以后, 对于本地数据块,将读取本地数据文件获取数据内容,对于远程数据块,将调用 RPC 异步的发起读数据块请求。
数据块提供服务可能来自其他Executor, 或者是 ExternalShuffleService(spark.shuffle.service.enabled)。
ShuffleBlockFetcherIterator 并不一次将所有的远程数据块都拉取过来。它是一个迭代器,逐个迭代拉取远程数据块。
这是为了控制内存使用和减少不必要的数据传输开销。
反序列化
数据从远程拉取来以后,通过迭代器的方式逐个获取远程的数据块。然后反序列化成RecordKey->RecordValue数据集合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 为每个流创建一个键/值迭代器。
val recordIter = wrappedStreams.flatMap { case (blockId, wrappedStream) =>
// Note: 下面的asKeyValueIterator将键/值迭代器包装在NextIterator中。
// NextIterator确保在所有记录都被读取后调用底层InputStream的close()方法。
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
}
// 更新每个读取的记录的Task上下文指标。.
val readMetrics = context.taskMetrics.createTempShuffleReadMetrics()
val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]](
recordIter.map { record =>
readMetrics.incRecordsRead(1)
record
},
context.taskMetrics().mergeShuffleReadMetrics())
// 这里必须使用可中断的迭代器,以支持任务取消。
val interruptibleIter = new InterruptibleIterator[(Any, Any)](context, metricIter)
聚合处理
如果这里需要对数据进行聚合处理。则执行聚合过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
} else {
val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
}
} else {
interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]]
}
// ExternalAppendOnlyMap 是一个可溢写的keyvalue
def combineCombinersByKey(
iter: Iterator[_ <: Product2[K, C]],
context: TaskContext): Iterator[(K, C)] = {
val combiners = new ExternalAppendOnlyMap[K, C, C](identity, mergeCombiners, mergeCombiners)
combiners.insertAll(iter)
updateMetrics(context, combiners)
combiners.iterator
}
def combineValuesByKey(
iter: Iterator[_ <: Product2[K, V]],
context: TaskContext): Iterator[(K, C)] = {
val combiners = new ExternalAppendOnlyMap[K, V, C](createCombiner, mergeValue, mergeCombiners)
combiners.insertAll(iter)
updateMetrics(context, combiners)
combiners.iterator
}
这里聚合操作使用上的 ExternalAppendOnlyMap, 它是一个基于磁盘的Map结构,实现过程类似与ExternalSorter,如果数据量过多会发生多次溢写磁盘的情况,最终在iterator遍历时,做合并输出。
排序处理
如果是一些排序的算子, 聚合以后需要基于提供的排序比较器对数据做一次全排序,它的排序实现跟SortShuffleWriter同样使用的是ExternalSorter.
通过多次溢写+最终归并,形成最终的排序数据流。由于上面已经做了描述,此处不在赘述。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
val resultIter = dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
// Create an ExternalSorter to sort the data.
val sorter = new ExternalSorter[K, C, C](context, ordering = Some(keyOrd), serializer = dep.serializer)
sorter.insertAll(aggregatedIter)
context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes)
// Use completion callback to stop sorter if task was finished/cancelled.
context.addTaskCompletionListener[Unit](_ => {
sorter.stop()
})
CompletionIterator[Product2[K, C], Iterator[Product2[K, C]]](sorter.iterator, sorter.stop())
case None =>
aggregatedIter
}