Paimon 教程 | Paimon 主键表

基本原理
如果定义具有主键的表,则可以在表中插入、更新或删除记录。
主键由一组列组成,这些列包含每条记录的唯一值。
paimon 将数据按partition按bucket划分来维护,每个partition下面有若干个bucket,每个桶下面对应一个 LSM TREE 维护的数据集。
LSM 上面的每个文件可以使用orc, parquet 来存储({file.format:parquet}), 每个文件数据是按照 key 顺序存放。 level0 层数据文件级有序, level>0层数据是层级有序。

数据文件的层级关系, 数据 key 的范围等元信息都记录在 manifest 文件中。
Paimon 文件采用分层风格组织。下图说明了文件布局。从snapshot文件开始,Paimon 读取器可以递归访问表中的所有记录。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Table/
|
+ partition/
| |
| +------- bucket-0 /
| | |
| | +---------- data-dd44f37e-7369-4264-b2eb-9a6528d3d6b3-0.parquet
| |
| +------- bucket-1 /
| |
| +---------- data-5608d256-5578-42bb-ba57-86706cbbc35c-0.parquet
+ manifest /
| |
| +--- manifest-a138bdfe-f46e-4d64-b981-f650f51536b9-0
| +--- manifest-list-23508119-a4fb-487b-9ba7-f9a57186674d-0
| +--- manifest-list-23508119-a4fb-487b-9ba7-f9a57186674d-1
+ schema /
| |
| +-- schema-0
|
+ snapshot /
|
+--- EARLIEST
+--- LATEST
+--- snapshot-1
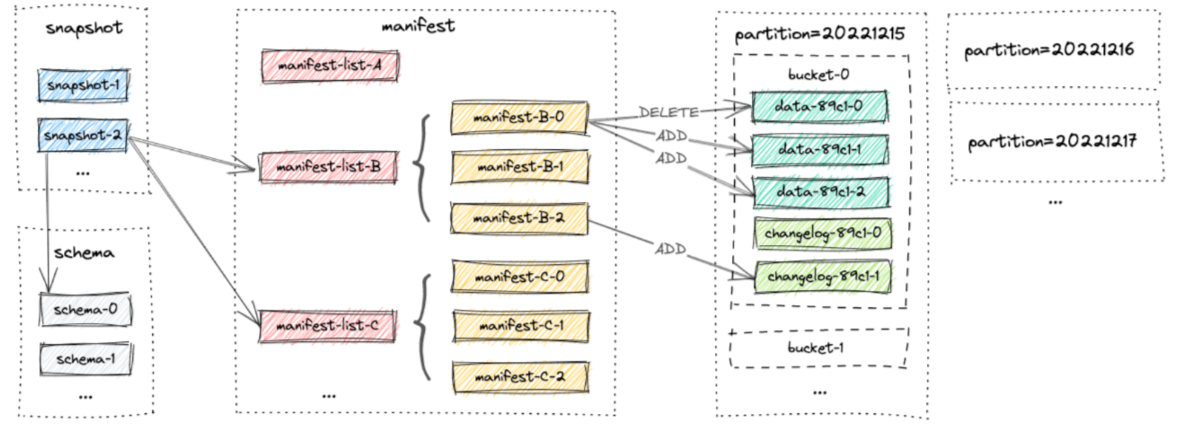
表元信息
Schema
schema 目录下面记录了当前表的元信息,初始创建表时,表元信息会存储在 schema-0 文件中。
在修改表结构时,会生成新的 schema 版本文件并存在这个目录中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
{
"version" : 3,
"id" : 0,
"fields" : [ {
"id" : 0,
"name" : "f0",
"type" : "INT NOT NULL"
}, {
"id" : 1,
"name" : "f1",
"type" : "STRING"
}, {
"id" : 2,
"name" : "f2",
"type" : "STRING"
} ],
"highestFieldId" : 2,
"partitionKeys" : [ ],
"primaryKeys" : [ "f0" ],
"options" : {
"bucket" : "1",
"file.format" : "orc",
"parquet.block.size" : "10485760",
"manifest.compression" : "null"
},
"timeMillis" : 1731477484926
}
fields记录当前的列信息, 每个字段通过id来唯一标识当前列highestFieldId用来记录当前最高的列id号, 他主要用来当schema删除,或者新增列时,保证旧的列的唯一性,用来实现模式演化。partitionKeys当前分区键信息primaryKeys当前表的主键信息options当前表的配置属性集合timeMillis当前schema生成时间
Snapshot
所有 snapshot 文件都存储在 snapshot 目录中。数据每次写入提交事物时, 会在 snapshot 目录下面生成一个最新的 snapshot 版本文件(snapshot-xxx)。
这个目录下面有两个特殊的文件 :
EARLIEST: 存储最老的snapshot版本文件名LATEST: 存储最新的snapshot版本文件名
用户可以通过 LATEST 文件获取最新 snapshot 访问表的最新数据。通过指定 snapshot 版本号的时间旅行方式,用户还可以通过较早的快照访问表的先前状态。
snapshot 主要记录当前在当前快照情况下的所有有效文件信息。每次数据读取时,先读取对应版本的 snapshot 文件,从snapshot文件中解析并合并读取 baseManifestList, deltaManifestList对应的文件列表,汇总得到当前 事物快照下的所有文件集合。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
"version" : 3,
"id" : 1,
"schemaId" : 0, // 来关联当前数据使用的表元信息
"baseManifestList" : "manifest-list-xxxx-0", // 记录提交事物之前的有效数据文件集合
"deltaManifestList" : "manifest-list-xxxx-1", // 记录当前事物所做的文件变更集合
"changelogManifestList" : null, // 记录在此快照中产生的所有变更日志的清单列表
"commitUser" : "xxxx",
"commitIdentifier" : 9223372036854775807,
"commitKind" : "OVERWRITE", // 此快照中的更改类型,包括 APPEND, COMPACT, OVERWRITE, ANALYZE.
"timeMillis" : 1730272220150,
"logOffsets" : { },
"totalRecordCount" : 3, // 此快照中发生的所有更改的记录计数
"deltaRecordCount" : 3, // 本次事物新增的记录数
"changelogRecordCount" : 0
}
snapshot 版本文件号是递增存储的(用来防止并发冲突),每次最新事物提交时,他首先会从LATEST中获取最新的 snapshot 版本信息,并递增一个 snapshot 版本文件,记录快照信息写入到 snapshot 版本文件中,如果有两个同时写入提交事物,那么通过文件写冲突,保证只有一个能够顺利写入,失败的一方会重新递增版本。

Manifest
manifest 文件主要包含当前提交事物快照(snapshot)所发生的文件变更情况。 每一次新事物提交时, manifest 都会记录本次提交相对于之前版本有效文件集的变化情况:新增的文件详情,或者删除的文件详情。
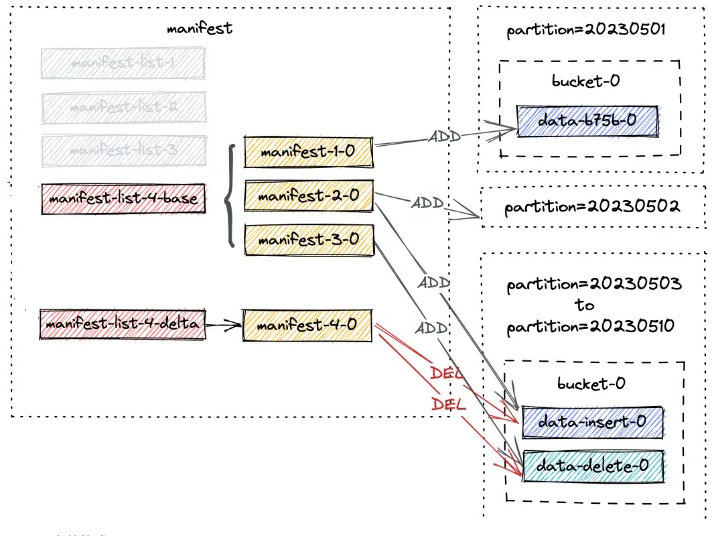
Manifest 文件格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
[
{ // 数据文件元信息
"_VERSION": 2,
"_KIND": 0, // ADD(0) 或 DELETE(1)
"_PARTITION": { "bytes": "xxxxx" }, // 该文件所属分区
"_BUCKET": 0, // 该文件所属分桶
"_TOTAL_BUCKETS": 2,
"_FILE": {
"_FILE_NAME": "data-9577d876-2cb0-4c90-b00b-9b8a6187298c-0.parquet", // 变更文件元信息
"_FILE_SIZE": 1044, // 该文件的大小
"_ROW_COUNT": 1, // 该文件的数据量
"_MIN_KEY": { "bytes": "xxxx" }, // 该文件的最小 key 记录
"_MAX_KEY": { "bytes": "xxxx" }, // 该文件的最大 key 记录
"_KEY_STATS": {
"_MIN_VALUES": { "bytes": "xxxx" },
"_MAX_VALUES": { "bytes": "xxxx" },
"_NULL_COUNTS": [0]
},
"_VALUE_STATS": {
"_MIN_VALUES": { "bytes": "xxxx" },
"_MAX_VALUES": { "bytes": "xxxx" },
"_NULL_COUNTS": [0, 0]
},
"_MIN_SEQUENCE_NUMBER": 0,
"_MAX_SEQUENCE_NUMBER": 0,
"_SCHEMA_ID": 0, // 该文件使用的 schema
"_LEVEL": 0, // 该文件所属的 level 层级
"_EXTRA_FILES": [],
"_CREATION_TIME": 1730307412448,
"_DELETE_ROW_COUNT": 0,
"_EMBEDDED_FILE_INDEX": null,
"_FILE_SOURCE": 0
}
},
...
]
manifest 文件中的每个 entry 代表了变更文件的元信息,他主要记录了对应文件的变更规则(新增/删除), 该文件的所属分区,分桶信息,文件名,文件大小,数据量,数据 key 的范围(最大值,最小值), 所属的 level 等相关信息。
每次事物影响的数据文件记录会汇总写入到同一个 manifest 中, 除非变更的数据文件过多,导致 manifest 过大,超过 {manifest.target-file-size:8M} ,此时会新开一个 manifest 文件进行写入。
由于每次事物提交时都会产生一到多个 manifest 文件, 为了便于维护当前的 manifest 文件集, 所以有了 manifestlist 文件。
manifest-list 是 manifest 文件名称的列表, 包含当前有效的 manifest 集合。所有 manifest-list 和 manifest 文件都存储在 manifest 目录中。
一个 snapshot 有两种 manifestlist, 分别是 baseManifestList, deltaManifestList:
baseManifestList用来包含事物提交以前的记录有效文件变更记录的manifest集合deltaManifestList用来记录当前当前事物所发生变更的manifest文件集合
所以 baseManifestList+deltaManifestList 得到当前事物的有效文件集合
ManifestList 文件格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
[
{ // manifest 文件元信息
"_VERSION": 2,
"_FILE_NAME": "manifest-3e6a597f-cf54-4be0-b6cc-d7133591a64b-0", // manifest文件名
"_FILE_SIZE": 2023, // manifest大小
"_NUM_ADDED_FILES": 1, // 清单中添加的文件数量
"_NUM_DELETED_FILES": 0, // 清单中删除的文件数量
"_PARTITION_STATS": { // 分区统计信息,此清单中分区字段的最小值和最大值
"_MIN_VALUES": { "bytes": "xxxx" },
"_MAX_VALUES": { "bytes": "xxxx" },
"_NULL_COUNTS": []
},
"_SCHEMA_ID": 0 // 写入此清单文件时的模式 ID。
},
...
]
Manifest 压缩机制
由于每次事物提交过程中都会产生新的 Manifest 文件,时间久了以后,读取表视图这块性能会显著下降。 所以在每次提交事物之前, 会对 baseManifestList 下面的所有的 Manifest 进行压缩操作。
压缩主要是对当前 baseManifestList 下面的所有的 Manifest 中,不足 {manifest.target-file-size:8M} 的 Manifest 文件集进行压缩合并,形成一个较大 manifest 文件 ( 达到 manifest.target-file-size 大小)。
该行为主要用来减少 mainfest 文件数量,提高数据元信息检索性能。
Manifest 有两种压缩行为 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 尝试进行 full-compaction
Optional<List<ManifestFileMeta>> fullCompacted = tryFullCompaction(
input, // manifest 文件集合
newMetas, // 输出文件集合
manifestFile, // manifest handler
suggestedMetaSize, // manifest.target-file-size (8M)
manifestFullCompactionSize, // manifest.full-compaction-threshold-size (16M)
partitionType);
// 如果 full-compaction 没有触发,则尝试进行 minor compaction
return fullCompacted.orElseGet(() -> tryMinorCompaction(
input,
newMetas,
manifestFile,
suggestedMetaSize,
suggestedMinMetaCount));
MinorCompaction

MinorCompaction每次会遍历迭代baseManifestLitst下面的文件, 顺序将不足{manifest.target-file-size:8M}的manifest跟临近的manifest文件合并,用来形成一个大的manifest文件(超过{manifest.target-file-size:8M})- 如果待合并的连续
manifest文件加起来不足{manifest.target-file-size:8M}, 那需要判断待合并的manifest文件数据是否超过{manifest.merge-min-count:30}, 如果超过阈值才进行合并,防止每次合并带来的性能损失 - 在
compaction过程中如果发现同一个文件的ADD,Delete标记, 则不在manifest文件中添加标记 - 在
compaction过程中如果只发现一个文件的Delete标记, 则继续在manifest文件中保留标记,因为ADD标记在其他的manifest文件中
FullCompaction

FullCompaction每次只会优先处理不足{manifest.target-file-size:8M}的小文件与manifest文件中包含数据文件删除标记的文件集合。- 只有上述两类文件集合总大小达到
{manifest.full-compaction-threshold-size:16M}时才会触发full-compaction标记 - 对于有
Delete标记的数据文件元信息,将不在写入到manifest文件中 - 如果发现
Delete标记的文件元信息, 会查找该ADD文件元信息所在的Manifest并将该Manifest一起重新压缩。
数据操作
创建目录
通过以下方式启动 Flink SQL 客户端 ./sql-client.sh 并执行以下命令 语句来创建 Paimon 目录。
1
2
3
4
5
6
CREATE CATALOG paimon WITH (
'type' = 'paimon',
'warehouse' = 'file:///tmp/paimon'
);
USE CATALOG paimon;
这只会在给定路径处创建一个目录 file:///tmp/paimon
创建表
执行以下 create table 语句,将创建一个 3 个字段的 Paimon 表
1
2
3
4
5
6
7
CREATE TABLE T (
id BIGINT,
a INT,
b STRING,
dt STRING COMMENT 'timestamp string in format yyyyMMdd',
PRIMARY KEY(id, dt) NOT ENFORCED
) PARTITIONED BY (dt);
将创建 Paimon 表 T 在路径下 /tmp/paimon/default.db/T、 其 schema 存储在 /tmp/paimon/default.db/T/schema/schema-0
将记录插入表中
在 Flink SQL 中执行以下 insert 语句。
1
INSERT INTO T VALUES (1, 10001, 'varchar00001', '20230501');
旦 Flink 作业完成,记录就会通过成功的 commit。 用户可以通过执行查询来验证这些记录的可见性 SELECT * FROM T这将返回一行。
提交过程会创建一个位于路径 /tmp/paimon/default.db/T/snapshot/snapshot-1。
snapshot-1 处生成的文件布局如下所述:
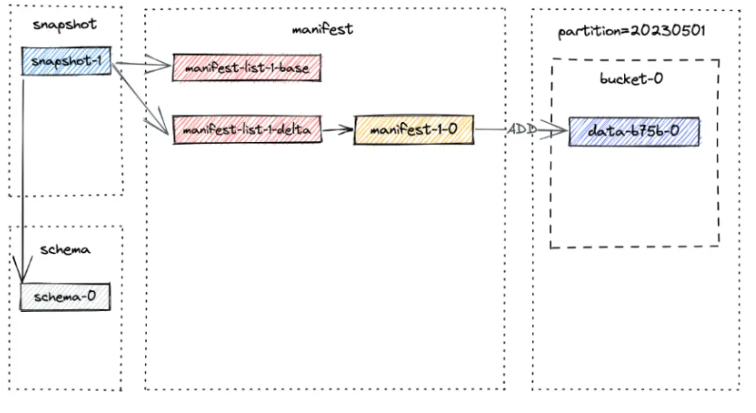
snapshot-1 的内容包含快照的元数据,例如 manifest-list 和 schema-id:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"version" : 3,
"id" : 1,
"schemaId" : 0,
"baseManifestList" : "manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-0",
"deltaManifestList" : "manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-1",
"changelogManifestList" : null,
"commitUser" : "7d758485-981d-4b1a-a0c6-d34c3eb254bf",
"commitIdentifier" : 9223372036854775807,
"commitKind" : "APPEND",
"timeMillis" : 1684155393354,
"logOffsets" : { },
"totalRecordCount" : 1,
"deltaRecordCount" : 1,
"changelogRecordCount" : 0,
"watermark" : -9223372036854775808
}
提醒一下,manifeste-list 包含快照的所有变更,baseManifestList 是当前 snapshot 变更前数据视图。 deltaManifestList 是当前 snapshot 的本次变更。第一次提交将生成一个 manifest 文件,并创建两个manifest-list:
1
2
3
4
./T/manifest:
manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-1
manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-0
manifest-2b833ea4-d7dc-4de0-ae0d-ad76eced75cc-0
manifest-2b833ea4-d7dc-4de0-ae0d-ad76eced75cc-0是manifest文件(在上图中为manifest-1-0),它存储了snapshot中数据文件的信息。manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-0是baseManifestList(在上图中为manifest-list-1-base),它实际上是空的。manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-1是deltaManifestList(在上图中为manifest-list-1-delta),它包含对数据文件执行操作的清单条目,在这种情况下,就是manifest-1-0。
现在让我们插入一批记录到不同的分区,看看会发生什么。在 Flink SQL 中,执行以下语句:
1
2
3
4
5
6
7
8
9
10
INSERT INTO T VALUES
(2, 10002, 'varchar00002', '20230502'),
(3, 10003, 'varchar00003', '20230503'),
(4, 10004, 'varchar00004', '20230504'),
(5, 10005, 'varchar00005', '20230505'),
(6, 10006, 'varchar00006', '20230506'),
(7, 10007, 'varchar00007', '20230507'),
(8, 10008, 'varchar00008', '20230508'),
(9, 10009, 'varchar00009', '20230509'),
(10, 10010, 'varchar00010', '20230510');
在 snapshot-2 的新文件布局如下所示:

从表中删除记录
在让我们删除满足条件的记录 dt>=20230503。 在 Flink SQL 中,执行以下语句:
1
DELETE FROM T WHERE dt >= '20230503';
第三次提交发生,它给了我们 snapshot-3。现在,列出表下的文件,您会发现没有分区被删除。 相反,为分区 20230503 - 20230510 创建了一个新的数据文件:
这是有道理的,因为我们在第二次提交中插入了一条记录(由 +I[10, 10010, 'varchar00010', '20230510'] 表示). 然后在第三次提交中删除了该记录(-D[10, 10010, 'varchar00010', '20230510'])。
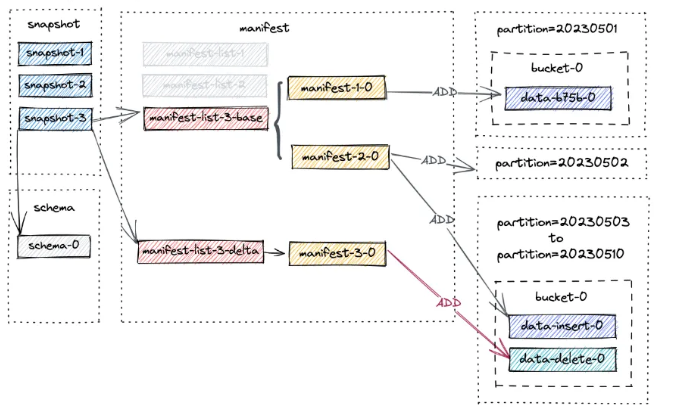
请注意,manifest-3-0 包含 8 个 ADD 操作类型的清单条目,对应于 8 个新写入的数据文件。
数据压缩
正如您可能注意到的,小文件的数量将在连续的快照中增加,这可能会导致读取性能下降。
因此,需要进行压缩以减少小文件的数量。 现在让我们触发full-compaction,并通过 flink run 运行一个专用的压缩作业:
1
2
3
4
5
6
7
8
9
10
<FLINK_HOME>/bin/flink run \
-D execution.runtime-mode=batch \
/path/to/paimon-flink-action-0.9.0.jar \
compact \
--warehouse <warehouse-path> \
--database <database-name> \
--table <table-name> \
[--partition <partition-name>] \
[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \
[--table_conf <paimon-table-dynamic-conf> [--table_conf <paimon-table-dynamic-conf>] ...]
所有当前表文件将被压缩,并创建一个新的snapshot,即 snapshot-4,其中包含以下信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"version" : 3,
"id" : 4,
"schemaId" : 0,
"baseManifestList" : "manifest-list-9be16-82e7-4941-8b0a-7ce1c1d0fa6d-0",
"deltaManifestList" : "manifest-list-9be16-82e7-4941-8b0a-7ce1c1d0fa6d-1",
"changelogManifestList" : null,
"commitUser" : "a3d951d5-aa0e-4071-a5d4-4c72a4233d48",
"commitIdentifier" : 9223372036854775807,
"commitKind" : "COMPACT",
"timeMillis" : 1684163217960,
"logOffsets" : { },
"totalRecordCount" : 38,
"deltaRecordCount" : 20,
"changelogRecordCount" : 0,
"watermark" : -9223372036854775808
}
snapshot-4 的新文件布局如下 :
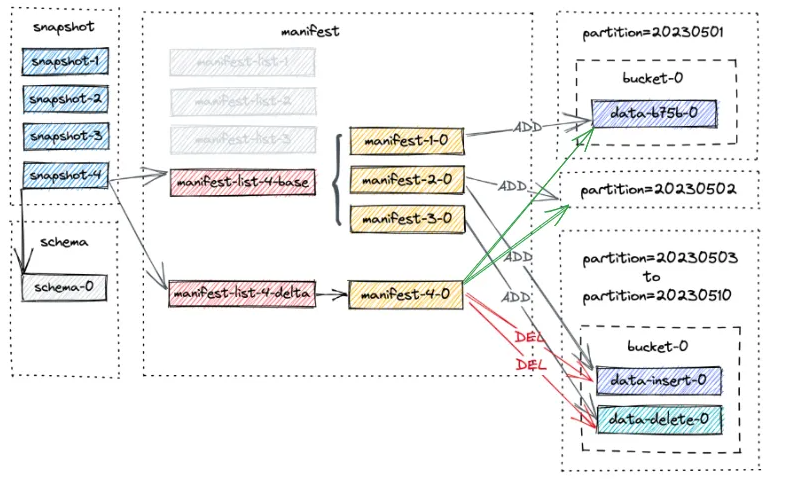
请注意,manifest-4-0 包含 20 个manifest enrtry(18 个 DELETE 操作和 2 个 ADD 操作)
- 对于分区
20230503 - 20230510,两个数据文件的两个DELETE操作 - 对于分区
20230501 - 20230502,同一数据文件的一个DELETE操作和一个ADD操作。这是因为文件已从level0升级到最高level。请放心,这只是元数据的更改,文件本身仍然相同