Paimon 教程 | Paimon 写流程

系统结构
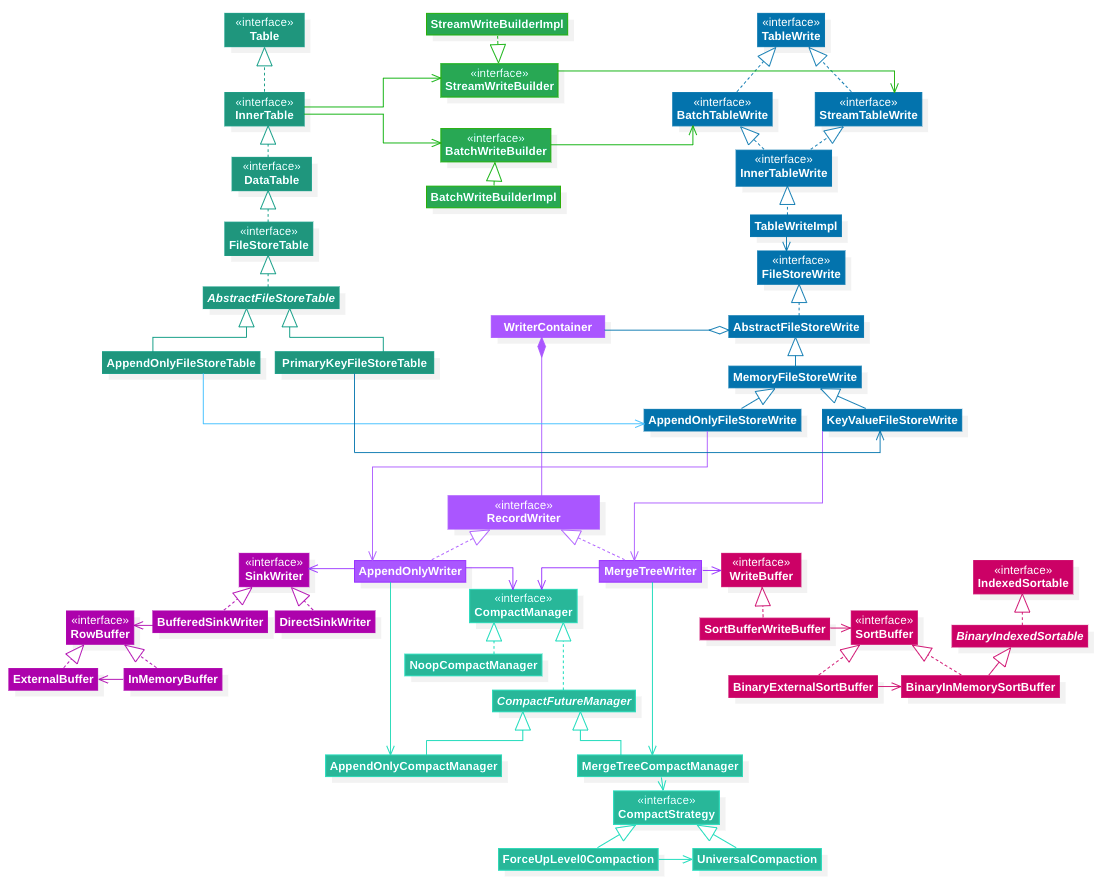
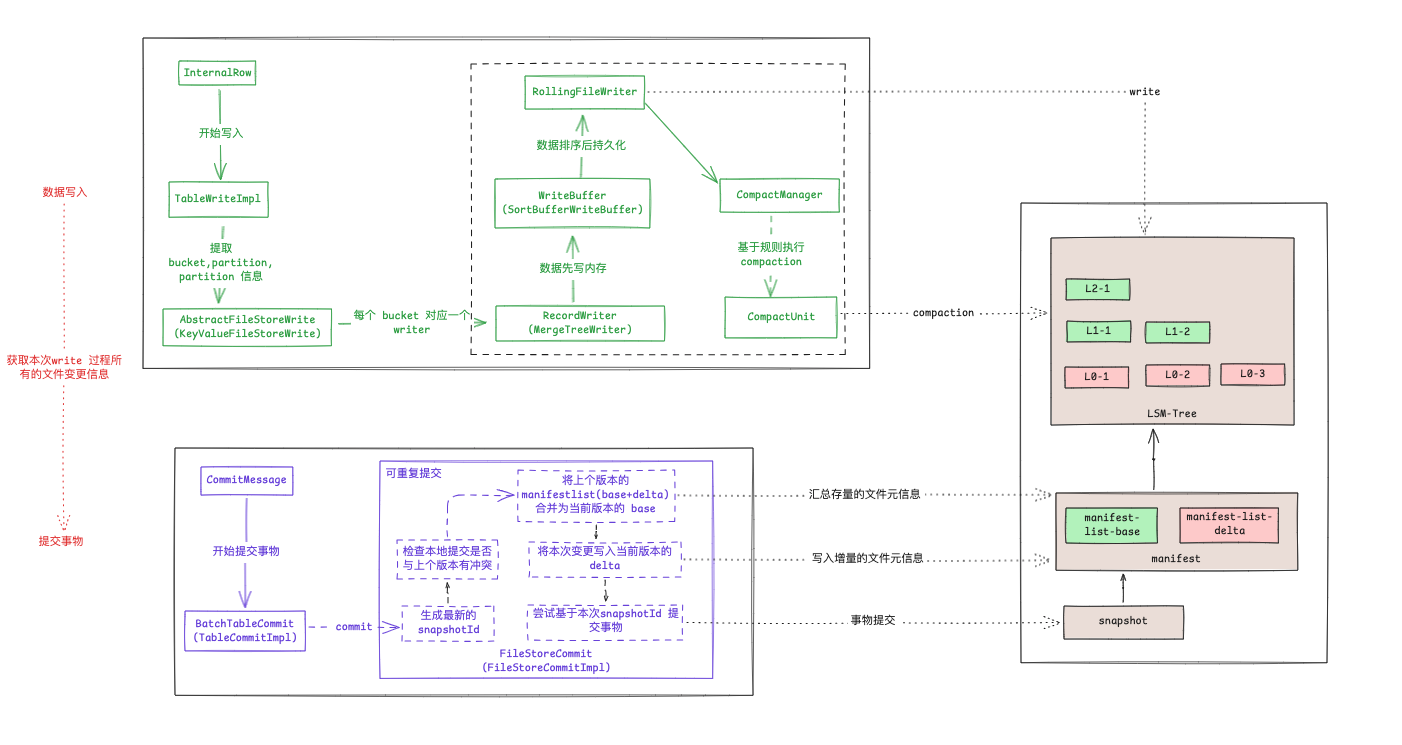
paimon write 过程主要涉及到以上相关的功能结构。
Table
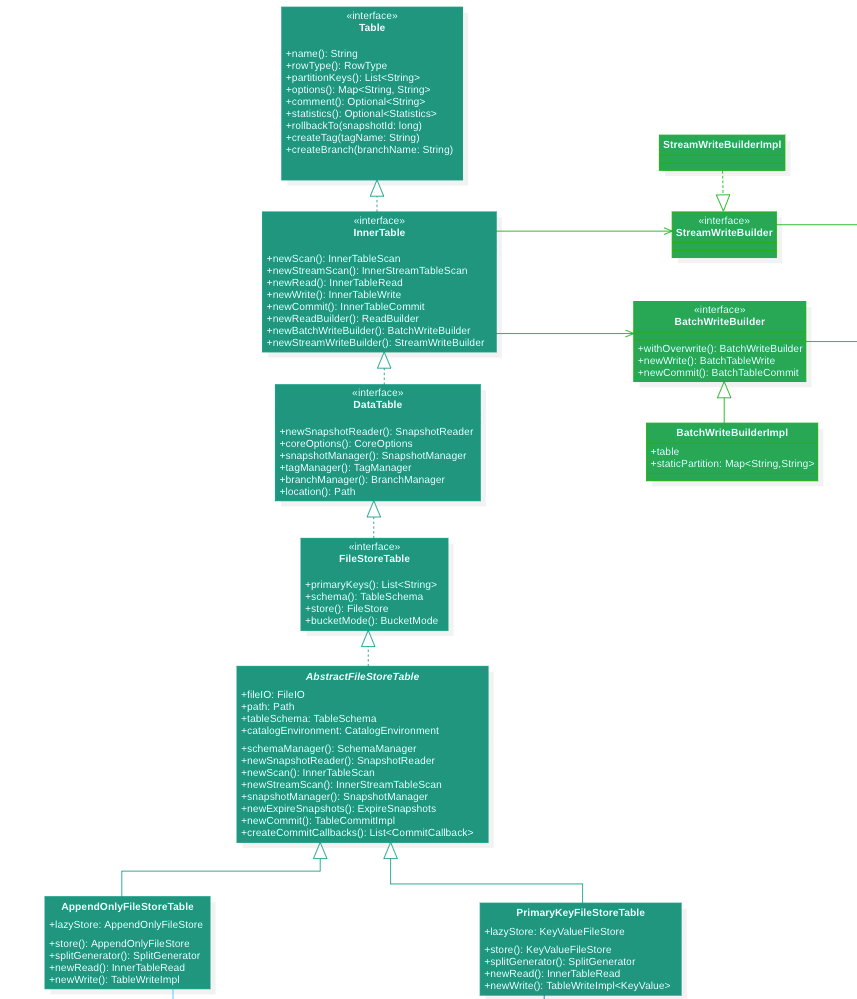
Table 主要是负责管理维护表的相关信息,他主要通过 Catalog 读取表 schema 等相关元信息构建而成。
基于表是否是主键表构建出对应的 PrimaryKeyFileStoreTable 或 AppendOnlyFileStoreTable。
Table 提供的基本大致能力如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// ================== Table Metadata =====================
String name(); // 表名
RowType rowType(); // 表 Schema
List<String> partitionKeys(); // 分区字段
List<String> primaryKeys(); // 主键
Map<String, String> options(); // 表选项
Optional<String> comment(); // 表注释
@Experimental Optional<Statistics> statistics(); // 表指标统计信息
// ================= Table Operations ====================
@Experimental void rollbackTo(long snapshotId); // 将表的状态回滚到特定快照。
@Experimental void createTag(String tagName, long fromSnapshotId); // 从给定快照创建Tag。
@Experimental void deleteTag(String tagName); // 删除一个 Tag
@Experimental void createBranch(String branchName); // 创建一个空的 branch
@Experimental void deleteBranch(String branchName); // 删除一个 branch
/** 手动过期快照,参数可以独立于表选项进行控制. */
@Experimental ExpireSnapshots newExpireSnapshots();
@Experimental ExpireSnapshots newExpireChangelog();
// =============== Read & Write Operations ==================
ReadBuilder newReadBuilder(); // ReadBuilder
BatchWriteBuilder newBatchWriteBuilder(); // BatchWriteBuilder
StreamWriteBuilder newStreamWriteBuilder(); // StreamWriteBuilder
并且 TableWrite 的构建也是依赖于 Table 的具体实现:
- 对于非主键表 :
AppendOnlyFileStoreTable提供了构建AppendOnlyFileStoreWrite的具体方式. - 对于主键表 :
PrimaryKeyFileStoreTable提供了构建KeyValueFileStoreWrite的具体方式.
TableWrite
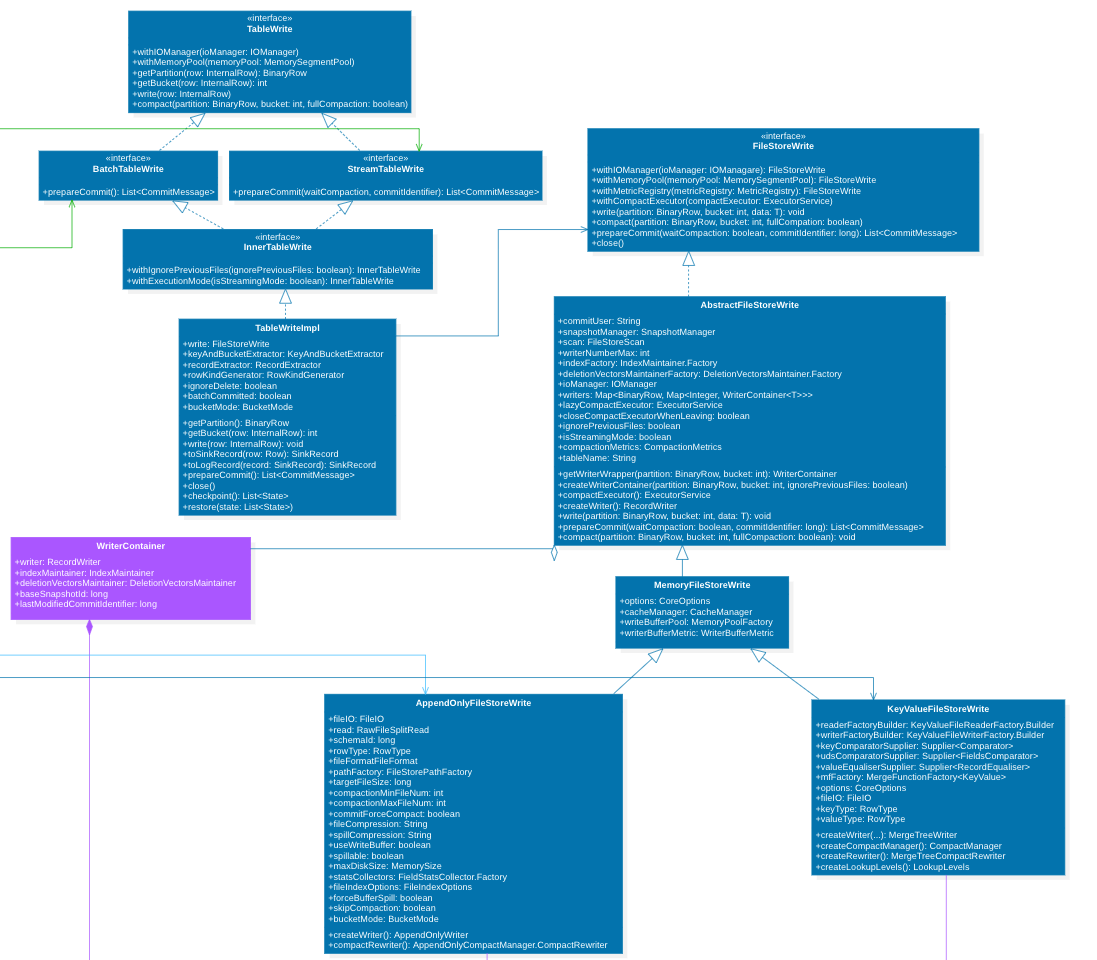
TableWrite 主要用来维护表的写入过程, 他负责将每条记录提取其 partition, bucket 信息。 然后将数据转交给 FileStoreWrite.
1
2
3
4
5
6
7
8
// TableWriteImpl.java
RowKind rowKind = RowKindGenerator.getRowKind(rowKindGenerator, row);
if (ignoreDelete && rowKind.isRetract()) {
return null;
}
SinkRecord record = toSinkRecord(row, bucket);
// FileStoreWrite<T> write
write.write(record.partition(), bucket, recordExtractor.extract(record, rowKind));
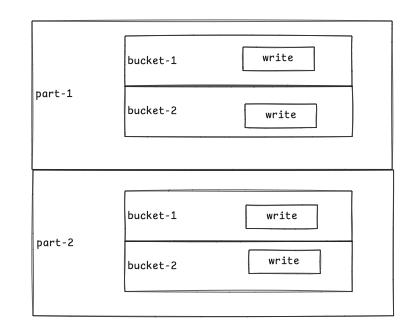
在 FileStoreWrite 每个 bucket 对应有一个 RecordWriter 写工具, 他将每条数据写到对应 bucket 的 RecordWriter 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// AbstractFileStoreWrite.java
protected final Map<BinaryRow, Map<Integer, WriterContainer<T>>> writers;
private WriterContainer<T> getWriterWrapper(BinaryRow partition, int bucket) {
Map<Integer, WriterContainer<T>> buckets = writers.get(partition);
if (buckets == null) {
buckets = new HashMap<>();
writers.put(partition.copy(), buckets);
}
return buckets.computeIfAbsent(
bucket, k -> createWriterContainer(partition.copy(), bucket, ignorePreviousFiles));
}
@Override
public void write(BinaryRow partition, int bucket, T data) throws Exception {
WriterContainer<T> container = getWriterWrapper(partition, bucket);
container.writer.write(data);
if (container.indexMaintainer != null) {
container.indexMaintainer.notifyNewRecord(data);
}
}
RecordWriter
RecordWrite 是数据写入的具体工作类实体, 他主要有三个依赖三个功能组件,完成数据落地:
- 内存缓冲区 : 数据并非是直接写入到目标文件中的,而是在内存中维护一个内存缓冲区, 当缓冲区空间不足不足以写入足够多的数据是, 才对缓冲区的数据进行落盘处理
- 磁盘写入工具: paimon 中主要使用
RollingFileWriter作为数据写入实体, 他主要是负责对具体文件系统的 IO 实现,还有对应不同文件存储格式(ORC/PARQUET)的数据写入实现. - compaction : 主要用来维护管理存量文件,基于具体的策略定期合并历史数据,提升查询效率。
数据写内存
在主键表模式下
数据写入首先通过 WriteBuffer 来写内存, 这是一个可排序的内存缓冲区(SortBuffer).
在数据写入时, 通过内存缓冲池,数据先写入到MemorySegment中。
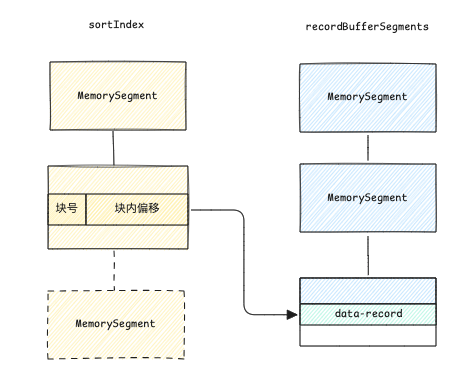
当内存缓冲池空间不足,或者当前写批次结束时, 会对内存缓冲池的数据按照 key 进行排序处理,然后刷写出去。
1
2
3
4
5
6
7
8
// BinaryInMemorySortBuffer.java
@Override
public final MutableObjectIterator<BinaryRow> sortedIterator() {
if (numRecords > 0) {
new QuickSort().sort(this);
}
return iterator();
}
主键表模式下提供了两种内存缓冲区 :
- 纯内存缓冲区
BinaryInMemorySortBuffer: 只利用内存来存放数据, 通过${write-buffer-size:256M}参数控制大小, 当内存池空间达到上限时, 数据排序后写出到目标文件。 - 可溢出内存缓冲区
BinaryExternalSortBuffer: 他使用BinaryInMemorySortBuffer将数据维护到内存中, 如果内存空间不足,数据会首先排序溢写到本地文件。到所有写数据完成后, 通过多路归并排序(借助PartialOrderPriorityQueue),形成最终的文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public BinaryMergeIterator(
List<MutableObjectIterator<Entry>> iterators,
List<Entry> reusableEntries,
Comparator<Entry> comparator)
throws IOException {
checkArgument(iterators.size() == reusableEntries.size());
this.heap =
new PartialOrderPriorityQueue<>(
(o1, o2) -> comparator.compare(o1.getHead(), o2.getHead()),
iterators.size());
for (int i = 0; i < iterators.size(); i++) {
this.heap.add(new HeadStream<>(iterators.get(i), reusableEntries.get(i)));
}
}
在非主键表模式下
非主键表模式下数据写缓冲主要是通过 RowBuffer 来实现的, 他与SortBuffer功能类似, 只是少了排序过程 :
- 纯内存缓冲区
InMemoryBuffer: 只利用内存来存放数据, 通过${write-buffer-size:256M}参数控制大小, 当内存池空间达到上限时, 数据写出到目标文件。 - 可溢出内存缓冲区
ExternalBuffer: 他使用InMemoryBuffer将数据维护到内存中, 如果内存空间不足,数据溢写到本地文件。到所有写数据完成后,重新读取刷写到目标文件。
数据写磁盘
数据写入过程是通过 RollingFileWriter 来完成的, 他通过{target-file-size:128M}来控制写出文件大小, 他内部将数据写到对应的 orc, parquet 目标文件。 如果数据过多超过了文件大小上限,他会关闭当前在写的文件,重新写入一个新的文件。
compaction 流程
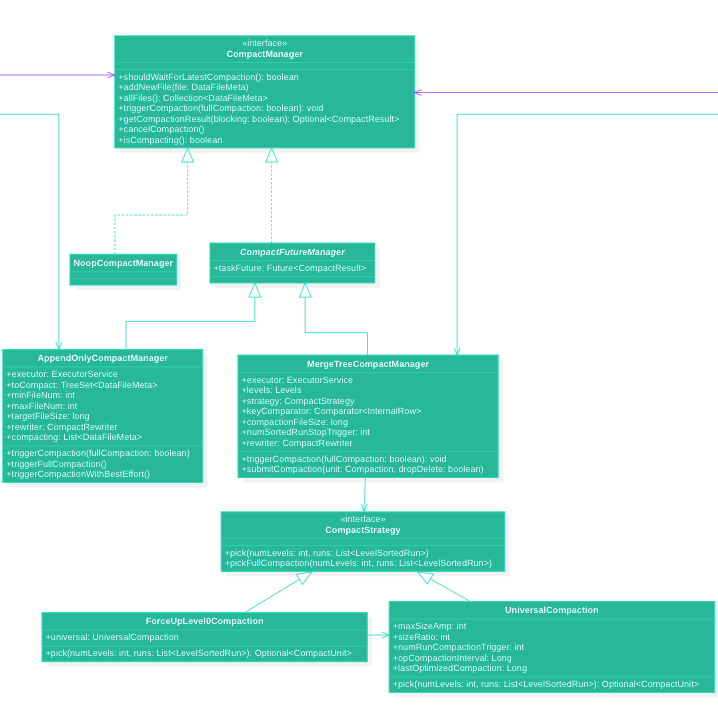
主键表
主键表的 compaction 实现主要是通过 RockesDB-Compaction : https://github.com/facebook/rocksdb/wiki/Universal-Compaction 策略实现(UniversalCompaction).
待压缩的数据集:
level-0的文件,每个文件都是一个 sorted-runlevel>0的文件,每层所有文件对应一个 sorted-run- 数据组织形式(
List<LevelSortedRun>) :level-0-0,level-0-1, …,level-1, …,level-maxlevel(当前lsm已有文件的最大的level)
压缩策略 :
- 检验是否有读放大问题,如果存在则整个 lsm 进行压缩 :
校验前面的 soredrun 总量是否过大
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 除了最后一个 sortedrun 之外的所有的 sortedrun 总大小
long candidateSize = runs.subList(0, runs.size() - 1).stream()
.map(LevelSortedRun::run)
.mapToLong(SortedRun::totalSize)
.sum();
// 最后一个 sortedrun 大小
long earliestRunSize = runs.get(runs.size() - 1).run().totalSize();
// maxSizeAmp : ${compaction.max-size-amplification-percent:200}
if (candidateSize * 100 > maxSizeAmp * earliestRunSize) {
updateLastOptimizedCompaction();
return CompactUnit.fromLevelRuns(maxLevel, runs);
}
- 从第一个
soredrun开始,陆续合并相邻的大小相近的或者较小的soredrun。形成较大的soredrun
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// 读取第一个 SortedRun 大小
long candidateSize = candidateSize(runs, 1);
// 从第二个 SortedRun 开始, 将大小相近的相邻的 SortedRun 合并成较大的 SortedRun
for (int i = 1; i < runs.size(); i++) {
LevelSortedRun next = runs.get(i);
// {compaction.size-ratio:1}
if (candidateSize * (100.0 + sizeRatio) / 100.0 < next.run().totalSize()) {
break;
}
candidateSize += next.run().totalSize();
candidateCount++;
}
// 输出level 取需要压缩的 sorted-run 的最大level
// 如果都是 level0 则取第一个 != 0 的level
if (forcePick || candidateCount > 1) {
return createUnit(runs, maxLevel, candidateCount);
}
- 如果 sorted-run 数量过多, 则触发压缩策略
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
if (runs.size() > numRunCompactionTrigger) { // ${num-sorted-run.compaction-trigger:5}
// 计算sortted-run 超出的数量
int candidateCount = runs.size() - numRunCompactionTrigger + 1;
// 以超出部分为基数开始开始计算压缩
return Optional.ofNullable(pickForSizeRatio(maxLevel, runs, candidateCount));
}
public CompactUnit pickForSizeRatio(
int maxLevel, List<LevelSortedRun> runs, int candidateCount) {
// 计算 [0-超出阈值数量) 的所有 sorted-run 的总大小
long candidateSize = candidateSize(runs, candidateCount);
// 从 超出阈值数量开始,将大小相近的 sortted-run 统一加入压缩
for (int i = candidateCount; i < runs.size(); i++) {
LevelSortedRun next = runs.get(i);
// {compaction.size-ratio:1}
if (candidateSize * (100.0 + sizeRatio) / 100.0 < next.run().totalSize()) {
break;
}
candidateSize += next.run().totalSize();
candidateCount++;
}
// 输出level 取需要压缩的 sorted-run 的最大level
// 如果都是 level0 则取第一个 != 0 的level
if ( candidateCount > 1) {
return createUnit(runs, maxLevel, candidateCount);
}
return null;
}
compaction 过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
// MergeTreeCompactTask.java
// 待合并的文件集合
// 每个 List<SortedRun> 之间数据是不重叠的
// List<SortedRun> 内部, 不同的 SortedRun 之间数据可能会重叠
partitioned = new IntervalPartition(unit.files(), keyComparator).partition();
for (List<SortedRun> section : partitioned) {
if (section.size() > 1) { // 表示有重叠数据,需要进行压缩处理
candidate.add(section);
} else {
// 无重叠:
// 我们可以只升级大文件,只需更改级别,而无需重写
// 但对于小文件,我们会尝试压缩它
SortedRun run = section.get(0);
for (DataFileMeta file : run.files()) {
if (file.fileSize() < minFileSize) { // 文件太小了,需要合并
candidate.add(singletonList(SortedRun.fromSingle(file))); // 小文件将与之前的文件一起重写
} else {
// 大文件出现,重写之前的文件并升级它, 必须要将
rewrite(candidate, result);
upgrade(file, result);
}
}
}
}
rewrite(candidate, result);
/***
* 需要将当前的文件重新合并压缩, 写入到新的文件中
*
* @param candidate 待压缩的文件集合
* @param toUpdate 用于收集的压缩结果信息
*/
private void rewrite(List<List<SortedRun>> candidate, CompactResult toUpdate) throws Exception {
if (candidate.isEmpty()) {
return;
}
if (candidate.size() == 1) {
List<SortedRun> section = candidate.get(0);
if (section.size() == 0) {
return;
} else if (section.size() == 1) { // 如果待压缩的 sortrun 只有一个, 则直接更新
for (DataFileMeta file : section.get(0).files()) {
upgrade(file, toUpdate);
}
candidate.clear();
return;
}
}
rewriteImpl(candidate, toUpdate);
}
/***
* 需要将当前的文件重新合并压缩, 写入到新的文件中
*
* @param candidate 待压缩的文件集合
* @param toUpdate 用于收集的压缩结果信息
*/
private void rewriteImpl(List<List<SortedRun>> candidate, CompactResult toUpdate)
throws Exception {
CompactResult rewriteResult = rewriter.rewrite(outputLevel, dropDelete, candidate);
toUpdate.merge(rewriteResult);
candidate.clear();
}
非主键表
非主键表合并主要是从旧文件开始,定期收集${target-file-size:128M} 一定数量的文件,进行压缩合并,防止中间小文件的产生。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
// 初始化,将所有有效文件加入到待压缩集合中
toCompact = new TreeSet<>(fileComparator(false));
toCompact.addAll(restored);
public static Comparator<DataFileMeta> fileComparator(boolean ignoreOverlap) {
return (o1, o2) -> {
if (o1 == o2) {
return 0;
}
return Long.compare(o1.minSequenceNumber(), o2.minSequenceNumber());
};
}
LinkedList<DataFileMeta> candidates = new LinkedList<>();
// 每次从版本最老的文件开始, 合并历史文件, 防止小文件产生
while (!toCompact.isEmpty()) {
DataFileMeta file = toCompact.pollFirst();
candidates.add(file);
totalFileSize += file.fileSize();
fileNum++;
if ((totalFileSize >= targetFileSize && fileNum >= minFileNum) || fileNum >= maxFileNum) {
return Optional.of(candidates);
} else if (totalFileSize >= targetFileSize) {
// let pointer shift one pos to right
DataFileMeta removed = candidates.pollFirst();
assert removed != null;
totalFileSize -= removed.fileSize();
fileNum--;
}
}
写入流程
这里主要以主键表的情况来介绍 Paimon 的数据写入方式。
在 paimon 中,数据写入时是以 bucket 为粒度进行维护的, 每个bucket 对应一个写入实体。
在主键表中,每个 bucket 是通过 lsm tree 的形式进行维护数据的。 每个 bucket 的数据先写入到内存中,在数据落盘之前会对本次写入的所有数据进行排序,排序完成以后在将数据进行落盘。
磁盘中将存放一个多级有序文件树:
- 每个文件内部是按顺序存放的
- L0 层文件之间可能会重叠数据
- L>0 层文件按层级是有序存放的,不同文件之间数据不重叠
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// 1. 创建一个WriteBuilder
Table table = TableUtil.getTable(); // PrimaryKeyFileStoreTable
BatchWriteBuilder writeBuilder = table.newBatchWriteBuilder(); // BatchWriteBuilderImpl
String[] items = new String[]{"h1", "h2", "h3"};
// 2. 在分布式任务中写入记录
BatchTableWrite write = writeBuilder.newWrite(); // TableWriteImpl
for(int i = 0; i < 400_000; i++){
GenericRow genericRow = GenericRow.of(
(long)i,
BinaryString.fromString(items[i%3]),
BinaryString.fromString(UUID.randomUUID().toString()),
(float)i,
(double)i,
(i % 2) == 0,
BinaryArray.fromLongArray(new Long[]{(long)i, (long)i+1,(long) i+2})
);
write.write(genericRow);
}
// 3. 完成写操作, 获取写入的文件信息
List<CommitMessage> messages = write.prepareCommit();
// 3. 将所有 CommitMessages 收集到一个全局节点并提交
BatchTableCommit commit = writeBuilder.newCommit();
commit.commit(messages);